Large language models (LLMs) have come to dominate natural‑language AI, and a new generation—Large Reasoning Models (LRMs)—now claims to “think” via extended chain‑of‑thought (CoT) outputs. But is this genuine reasoning or merely a high‑tech parlor trick? In their paper “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity”, Shojaee et al. (Apple) tackle this question head‑on. Here’s a detailed unpacking of their approach, results, and the implications for AI’s reasoning frontier.
Why We Need Better Reasoning Evaluations
The Rise of Chain‑of‑Thought
- Chain‑of‑Thought prompting (CoT) nudges LLMs to produce intermediate reasoning steps, boosting performance on math and logic tasks.
- New RL‑tuned “thinking” models (e.g., DeepSeek‑R1, Claude 3.7 Thinking, Gemini Flash Thinking) explicitly optimize for richer CoTs.
Shortcomings of Standard Benchmarks
- Data Contamination: Models often train on the very math problems used to evaluate them (e.g., MATH500), making “success” ambiguous.
- Final‑Answer Focus: Benchmarks score only the correctness of the answer, ignoring whether the reasoning path is valid or merely memorized.
Insight: Without understanding how a model arrives at an answer, we can’t tell if it’s truly reasoning or just pattern‑matching.
ALSO READ:
- What is a Large Language Model (LLM)?
- A Brief History of Large Large Language Models (LLMs)
- Key Components of Large Language Models (LLMs)
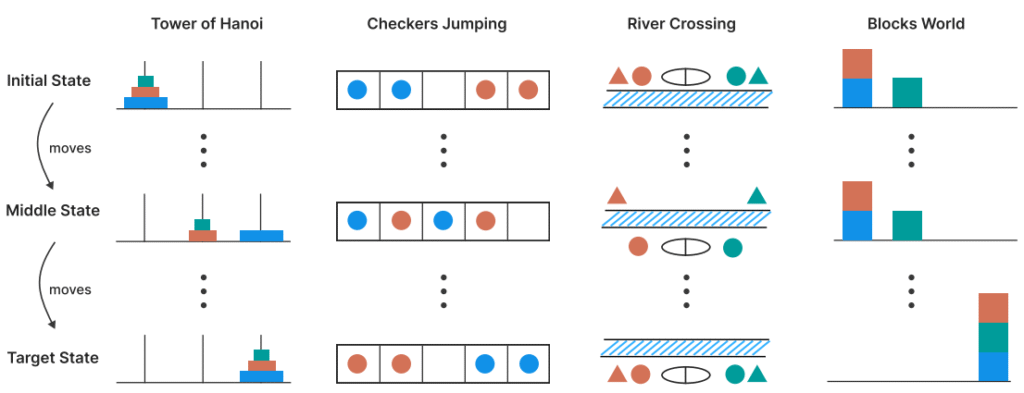
A Controlled Puzzle Testbed
To probe real reasoning, the authors turn to four deterministic puzzles where every step can be rigorously checked:
| Puzzle | Core Challenge | Complexity Control |
|---|---|---|
| Tower of Hanoi | Recursive disk moves | Number of disks (n) |
| Checker Jumping | One‑dimensional color swap | Number of checkers (2n+1) |
| River Crossing | Constraint satisfaction (agents) | Number of pairs (n) |
| Blocks World | Stack reconfiguration | Number of blocks (n) |
Each puzzle comes with a simulator that:
- Validates every intermediate move (e.g., no larger disk on a smaller peg),
- Tracks full state transitions,
- Detects any violation instantly, so we know exactly where and why a model fails.
Experimental Setup
Model Pairs
- Thinking vs. Non‑Thinking
- Claude 3.7 Sonnet (with & without CoT)
- DeepSeek‑R1 (RL‑tuned) vs. DeepSeek‑V3 (base)
- Token Budget Matched
Both variants get the same inference‑time token allowance (up to 64k), removing compute as a confound.
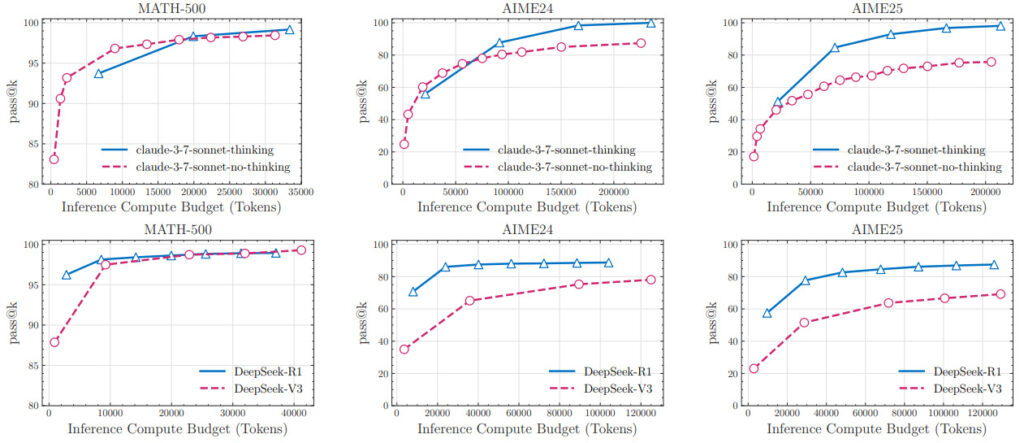
reveals inconsistent performance patterns.
Complexity Regimes
- Low Complexity: Minimal puzzle size (e.g., 3 disks in Hanoi)
- Medium Complexity: Challenging but solvable (e.g., 7 disks)
- High Complexity: Beyond human ease, where solutions require hundreds of steps
For each setting, models attempt 25 samples; success is measured by exactly reaching the goal state.
Three Performance Regimes
Regime I: Low Complexity
- Surprising Winner: Non‑thinking LLMs often outperform their CoT‑enabled peers.
- Fewer tokens used.
- Higher accuracy on trivial instances.
- Why? “Overhead” of producing long thoughts can introduce noise when simple heuristics suffice.
Regime II: Medium Complexity
- Thinking Models Pull Ahead
- Their extended CoTs help explore deeper solution paths.
- Accuracy gap widens in favor of LRMs.
Regime III: High Complexity
- Universal Collapse
- Both thinking and non‑thinking models collapse to near‑zero accuracy.
- Even with plenty of tokens left, LRMs stop expanding their thought traces—a scaling limit.
The Counterintuitive Scaling Limit
Token Usage Peaks, Then Falls
As puzzle difficulty ramps up, LRMs initially consume more reasoning tokens—until a critical threshold. Beyond that:
- They reduce their thought length, despite having unused budget.
- Reflects an internal “give‑up” heuristic rather than graceful scaling.
Implication
Models aren’t genuinely scaling their problem‑solving effort; they’re following learned heuristics that break down under deep compositional depth.
Peeking Inside the “Thoughts”
Using the puzzle simulators, the authors extract every candidate solution step embedded in the CoTs.
Overthinking in Easy Cases
- The earliest correct move appears within the first 10% of tokens.
- Yet the model continues exploring bad paths, cluttering its trace with errors.
Delayed Corrections in Medium Cases
- Correct moves migrate toward the latter half of the CoT.
- Indicates useful self‑reflection, but at high compute cost.
Total Failure in Hard Cases
- No correct moves at any point.
- Suggests models never discover valid sub‑solutions when compositional complexity soars.
Algorithm Execution: No Free Pass
Even when the exact algorithm for the Tower of Hanoi is provided in the prompt:
- Models still fail at roughly the same complexity threshold.
- They struggle not just with devising but even with executing a known procedure.
Takeaway: LRMs lack robust symbolic manipulation—you can’t simply feed them pseudo‑code and expect flawless execution.
Surprising Puzzle‑Specific Behaviors
- Tower of Hanoi: Models can string together 100+ correct moves for n=10 before a single error.
- River Crossing: Fail as early as move 4 for just 3 actor‑agent pairs.
Hypothesis: Web‑trained LMs have seen many Hanoi solutions online, but far fewer River Crossing examples—revealing a heavy reliance on memorization.
Broader Implications
- Reasoning ≠ Longer Chains: Quantity of thought tokens doesn’t guarantee quality or correctness.
- Benchmarks Must Evolve: Controlled, contamination‑free environments are crucial for probing true reasoning.
- Architectural Rethink Needed: Future models must integrate genuine symbolic processors or algorithmic modules—not just deeper autoregression.
Open Questions & Future Directions
- Why do LRMs under‑utilize tokens under extreme difficulty? Is it a learned “early exit” policy?
- Can we hybridize LLMs with discrete planners to avoid these collapse points?
- How can evaluation metrics incorporate trace validity alongside final accuracy?
Conclusion: The Illusion Unmasked
Shojaee et al. deliver a compelling exposé: today’s “thinking” models often simulate reasoning, but do not embody it. Their performance is brittle, over‑reliant on data contamination, and fundamentally capped by scaling limits. To truly advance AI’s reasoning capabilities, the field must move beyond flashy CoT demos and toward architectures that can both generate and verify complex, compositional thought processes.