The You Only Look Once (YOLO) series has revolutionized object detection since its inception in 2015. Developed initially by Joseph Redmon and colleagues, YOLO redefined speed and efficiency in computer vision by transforming detection into a single regression problem. Unlike earlier two-stage detectors (e.g., R-CNN), which required multiple passes over an image, YOLO processes images in a single forward pass, enabling real-time performance critical for applications like autonomous driving and robotics. This article examines the architectural innovations, limitations, and iterative improvements across each major YOLO version, from v1 to the cutting-edge v11 (2024).

YOLOv1 (2015): The Pioneering Single-Shot Architecture
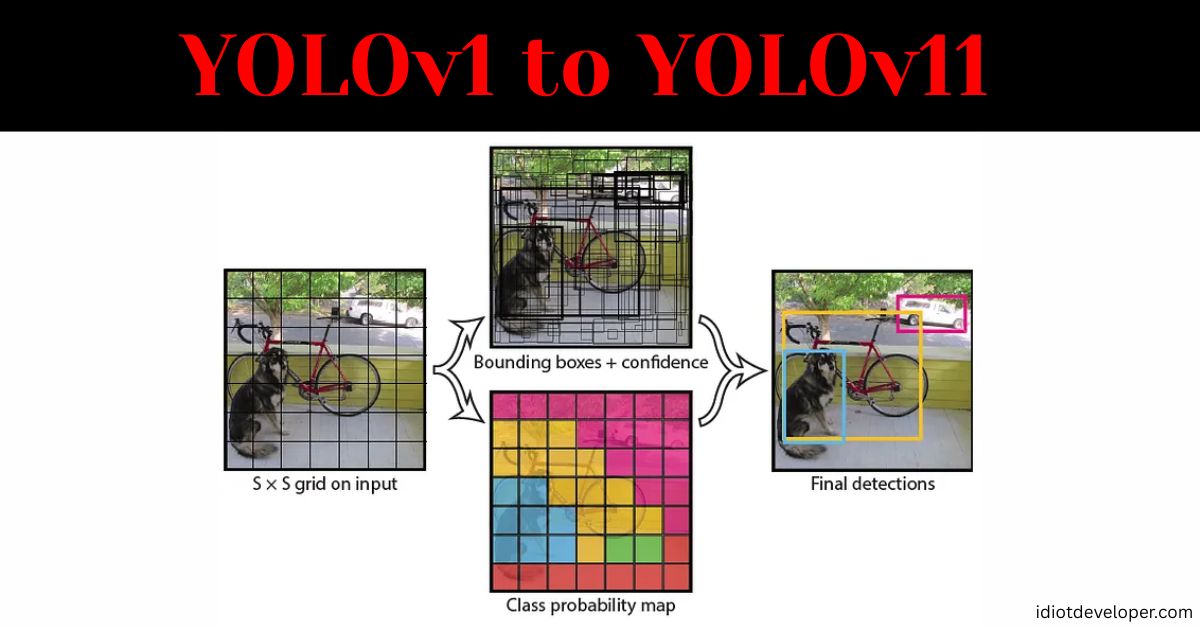
Paper: You Only Look Once: Unified, Real-Time Object Detection
Novelties:
- Grid-Based Detection: Divides images into an S×S grid (typically 7×7), with each cell predicting B bounding boxes and class probabilities.
- Unified Regression: Combines localization and classification into one network pass, reducing computational overhead.
- Real-Time Speed: Achieved 45 FPS on a Titan X GPU, far surpassing contemporaries like Faster R-CNN.
Drawbacks & Limitations:
- Spatial Constraints: Limited to two boxes per grid cell, struggling with small objects and object groups (e.g., flocks of birds).
- Localization Errors: Poor generalization to novel object aspects and sizes due to coarse feature maps.
- Loss Function Flaws: Equal weighting of errors in large/small boxes hurts precision.
ALSO READ:
- Exploring Bounding Boxes and Different Annotation Formats in Object Detection
- What is Intersection over Union (IoU) in Object Detection?
YOLOv2 / YOLO9000 (2016): Better, Faster, Stronger
Paper: YOLO9000: Better, Faster, Stronger
Novelties:
- Anchor Boxes: Introduced priors for bounding box dimensions using k-means clustering, improving recall.
- Batch Normalization: Added after every convolutional layer, stabilizing training and boosting accuracy.
- Multi-Scale Training: Randomly resized inputs during training (e.g., 320×320 to 608×608), enhancing robustness.
- Darknet-19 Backbone: Replaced GoogLeNet with a lighter 19-layer CNN, accelerating inference.
Improvements over v1: Addressed v1’s localization issues via anchor boxes and higher-resolution inputs. Achieved detection of >9,000 object classes via hierarchical WordTree classification.
YOLOv3 (2018): Scaling with Depth and Multi-Scale Features
Paper: YOLOv3: An Incremental Improvement
Novelties:
- Darknet-53 Backbone: Incorporated residual connections, enabling deeper feature extraction (53 layers).
- Multi-Scale Predictions: Three detection heads (at 8×, 16×, and 32× downsampling) improved small-object detection.
- Independent Logistic Classifiers: Replaced softmax with sigmoid for multi-label support.
Improvements over v2: Enhanced small-object handling via multi-scale heads and reduced background false positives. Maintained real-time speed (20 ms/frame) with higher mAP (57.9% on COCO)
YOLOv4 (2020): The Speed-Accuracy Breakthrough
Paper: YOLOv4: Optimal Speed and Accuracy of Object Detection
Novelties:
- CSPDarknet53 Backbone: Leveraged Cross Stage Partial networks to reduce compute load.
- Bag of Freebies (BoF): Training optimizations like Mosaic augmentation (4-image stitching) and CIoU loss improved generalization.
- Neck Architecture: Combined SPP (Spatial Pyramid Pooling) and PANet for multi-scale feature fusion.
Improvements over v3: Balanced speed (65 FPS) and accuracy (43.5% mAP on COCO) via architectural refinements and data augmentation.
YOLOv5 (2020): Developer-Friendly Efficiency
Repo: Ultralytics YOLOv5
Novelties:
- PyTorch Implementation: Simplified training/inference with Python APIs and CLI tools.
- Adaptive Anchors: Auto-learned anchor box sizes during training.
- Mosaic Augmentation: Enhanced context learning via composite images.
- Model Scaling: Five sizes (nano to x-large) for diverse hardware.
Improvements over v4: Streamlined deployment and faster training cycles without sacrificing COCO accuracy.
YOLOv6-v8 (2022–2023): Efficiency and Task Expansion
YOLOv6 (2022)
Paper: YOLOv6: Industrial Object Detection
- Hardware-Optimized Design: EfficientRep backbone for GPU/edge devices.
- Anchor-Free Detection: Simplified head design and SimOTA label assignment.
YOLOv7 (2022)
Paper: YOLOv7: Trainable Bag-of-Freebies
- E-ELAN Backbone: Extended layer aggregation for gradient flow.
- Model Re-Parameterization: Dynamic label assignment for auxiliary heads.
YOLOv8 (2023)
Repo: Ultralytics YOLOv8
- Anchor-Free Head: Direct center-point prediction, eliminating anchor tuning.
- Multi-Task Support: Unified framework for detection, segmentation, and pose estimation.
Improvements: v6–v8 emphasized deployment efficiency (e.g., quantization) and versatility across tasks. v8’s anchor-free design reduced hyperparameter sensitivity.
YOLOv9-v11 (2024): Information Bottlenecks and Hybrid Architectures
YOLOv9 (2024)
Paper: YOLOv9: Learning What to Learn
- Programmable Gradient Information (PGI): Preserved critical gradient flow for lightweight models.
- GELAN Backbone: Combined CSPNet and ELAN for efficient parameter use.
YOLOv10 (2024)
Paper: YOLOv10: Real-Time End-to-End Object Detection
- Dual Label Assignment: One-to-many (training) and one-to-one (inference) heads for NMS-free deployment.
- Hardware-Aware Design: Quantization-friendly for edge devices .
YOLOv11 (2024)
Repo: Ultralytics YOLOv11 Docs
- C3k2 Blocks & C2PSA: Parallel spatial attention for refined feature fusion.
- Multi-Task Scalability: Added oriented bounding boxes (OBB) for rotated objects.
- Efficiency Gains: 22% fewer parameters than YOLOv8m, with 54.7% mAP on COCO.
Improvements: v9–v11 tackled information loss in deep layers via reversible architectures. v11’s OBB support expanded applicability to aerial imagery and documents.
Summary Table of Key Innovations
| Version | Year | Core Innovations | Performance Highlight |
| v1 | 2015 | Single-stage grid detection | 45 FPS, limited accuracy |
| v2 | 2016 | Anchor boxes, batch norm | Multi-scale training, 9k classes |
| v3 | 2018 | Darknet-53, multi-scale heads | 57.9% mAP, better small objects |
| v4 | 2020 | CSPDarknet53, BoF/BoS | 65 FPS, SPP/PANet fusion |
| v5 | 2020 | Mosaic augmentation, PyTorch | Flexible model scaling |
| v6 | 2022 | Hardware-efficient design | Decoupled head, anchor-free |
| v7 | 2022 | Trainable BoF, E-ELAN | 155 FPS, re-parameterization |
| v8 | 2023 | Anchor-free, multi-task | Unified detection/segmentation/pose |
| v9 | 2024 | PGI, GELAN | State-of-art accuracy, fewer params |
| v10 | 2024 | Dual label assignment | Optimized for edge devices |
| v11 | 2024 | C3k2/C2PSA, OBB support | 54.7% mAP, multi-task efficiency |
Challenges and Future Directions
Despite progress, key limitations persist:
- Small Objects: Detection remains challenging due to coarse feature maps.
- Occlusions: Dense scenes cause missed detections (partially mitigated by v8’s context awareness).
- Resource Demands: Real-time edge deployment requires further model compression. Future work may explore 3D detection, neural architecture search (e.g., YOLO-NAS), and diffusion-based enhancements.
Conclusion
YOLO’s journey—from v1’s unified grid to v11’s multi-task efficiency—exemplifies how iterative innovation overcomes core limitations. Each version refined speed, accuracy, or versatility, expanding applications from factory safety to medical imaging. With open-source frameworks like Ultralytics driving accessibility, YOLO remains the gold standard for real-time perception. As computational boundaries push further, its next iterations will continue reshaping computer vision’s frontiers.




