Large Language Models (LLMs) have become the backbone of modern Natural Language Processing (NLP), pushing the boundaries of tasks like text generation, summarization, machine translation, and question-answering. These models are designed to process vast amounts of textual data, enabling them to generate human-like responses. The core strength of LLMs lies in their architecture, particularly the Transformer model, and the enormous amount of data they are trained on. This article will explore the technical components behind LLMs, including their architecture, training datasets, and considerations like computational cost and scalability.
Key Components of Architecture
The key components of the Large Language Model are as follows:
- Transformers
- Tokenization
- Input Embeddings
- Positional Embeddings
- Multi-Head Self Attention
- Layer Normalization and Residual Connections
- Feed-Forward Neural Networks
Transformers
Vaswani et al. introduced the transformer architecture in the seminal paper “Attention is All You Need” (2017). Unlike traditional Recurrent Neural Networks (RNNs) or Convolutional Neural Networks (CNNs), which struggle with long-range dependencies and parallelization, the Transformer excels by utilizing self-attention mechanisms. This architecture allows models to compute relationships between words or tokens in a sequence without requiring sequential processing, significantly speeding up training and inference.
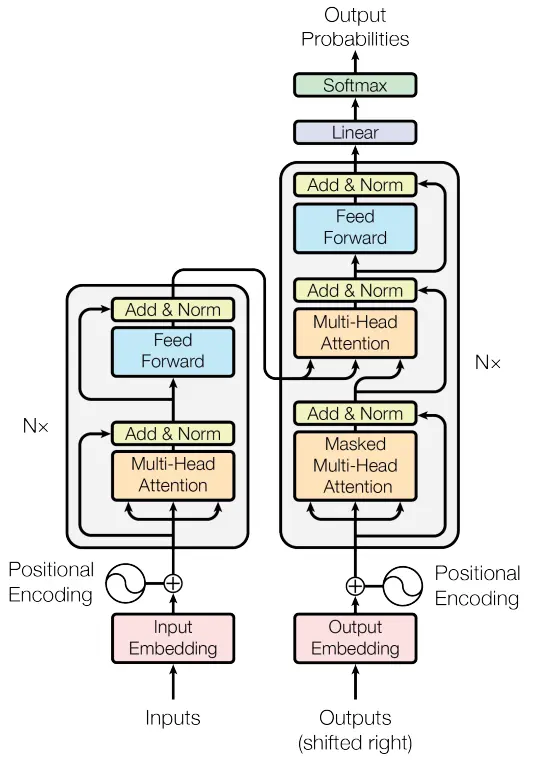
The core idea of the Transformer is the attention mechanism, which computes a weighted sum of input representations. Each token in the input sequence attends to every other token, allowing the model to capture dependencies across the entire sequence, even for long texts.
The key formula for scaled dot-product attention:
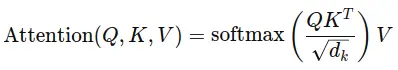
Where:
- Q (query), K (key), and V (value) are all projections of the input embeddings,
- dk is the dimension of the key vectors, and
- The softmax function ensures that attention weights sum to 1.
Tokenization
Tokenization transforms raw text into tokens, which can be words, subwords, or individual characters, depending on the strategy used. This process is essential for converting human-readable text into a numerical format that a machine learning model, like an LLM, can process.
The tokenization step begins by splitting the text based on spaces and punctuation, followed by further decomposition into subwords when necessary. This is especially useful for handling rare or out-of-vocabulary words. Subword tokenization techniques, such as Byte-Pair Encoding (BPE) and SentencePiece, help create a balanced vocabulary size, ensuring common subword units are represented while keeping the model efficient regarding memory and computational power. Each token is mapped to a unique integer ID, which is then used as input for further processing in the model.
In practice, tokenization is the first major step in preparing data for the model. Its purpose is to reduce the complexity of the text by breaking it down into manageable components while preserving its meaning.
For example, in the sentence “The cat is happy,” the model might tokenize it into individual words like “The,” “cat,” “is,” and “happy.” If it encounters a word like “unhappiness,” which is rare in the dataset, it could tokenize it as “un,” “happy,” and “ness,” breaking down the word into subword units.
The numerical representation of these tokens allows the neural network to understand the structure and meaning of the input text.
Input Embeddings
Once tokenization is complete, the next step is transforming these tokens into input embeddings, dense, continuous vector representations of the tokens. Each token, represented by an integer ID after tokenization, is mapped to a high-dimensional vector through an embedding matrix.
The embedding matrix E ∈ RV × dmodel stores the learned vector representation for each token in the model’s vocabulary V, where dmodel is the dimensionality of the embeddings. These embeddings are not static; they are learned during model training, where the neural network adjusts the vector representations based on patterns in the data.
Positional Embeddings or Positional Encoding
Since Transformers process the entire input sequence in parallel, they lack the natural order of RNNs. To address this, positional embeddings are added to the input embeddings to encode the position of tokens in a sequence. These are usually computed using sine and cosine functions of varying frequencies, as described by Vaswani et al.:
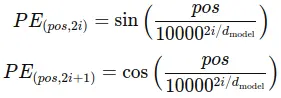
Where:
- pos is the position of the token in the sequence,
- i is the dimension of the embedding vector,
- dmodel is the total dimension of the model’s embedding space.
You can think of sine and cosine as two waves that rise and fall. These waves are special because they repeat in a smooth, predictable way. Using these waves with different frequencies, the model creates a unique “signature” for each position in the sentence. For example, the word in the first position might get a certain value from the sine function, while the second position gets a slightly different value, and so on. The sine wave values rise and fall more quickly for the early positions and slower for the later ones.
Here’s a simple way to imagine it:
- Think of each word’s position in the sentence as getting its “sine-cosine tag,” like a special label.
- For example, “The” at position 1 might get the values (0.5, 0.3) from the sine and cosine functions, while “cat” at position 2 might get (0.6, 0.4), and “sat” at position 3 might get (0.7, 0.5).
- These values help the model understand the words and their location in the sentence.
This process ensures that the Transformer model knows the order of the words even though it looks at all of them simultaneously. The advantage of using sine and cosine is that their repeating patterns are smooth and continuous, allowing the model to understand word positions clearly, whether the sentence is short or long. This way, the model can handle various texts and adapt to longer inputs not seen during training.
Multi-Head Self-Attention
In the self-attention mechanism, the model computes attention scores between every pair of tokens, enabling it to focus on different parts of the sequence. The multi-head attention mechanism enhances this by allowing the model to simultaneously attend to multiple input parts. Each head operates on a subspace of the input embedding, capturing different aspects of the relationships between tokens.
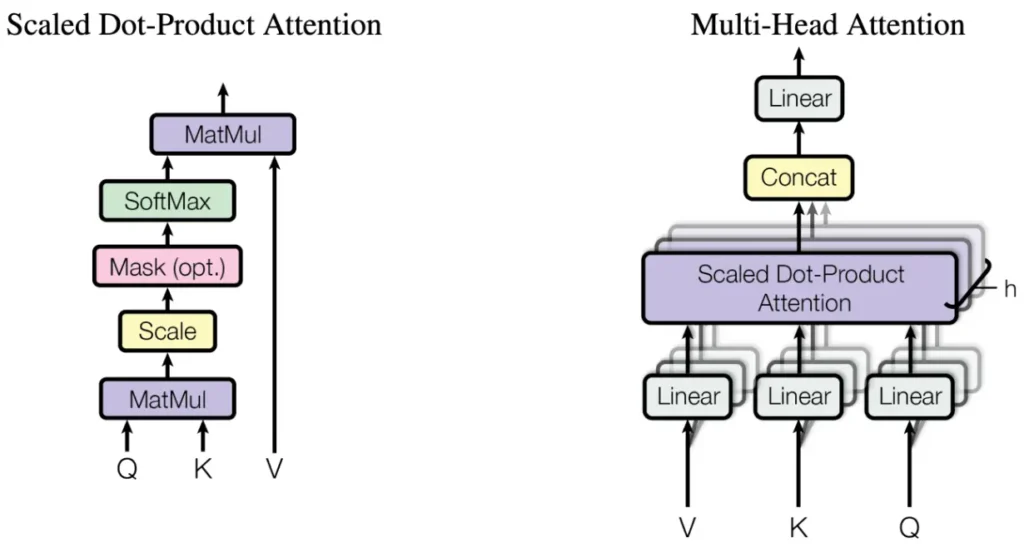
The output of the multi-head attention mechanism is concatenated and linearly transformed:
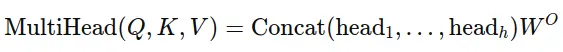
Where each attention head is computed as:
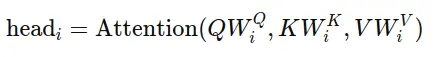
Layer Normalization and Residual Connections
Layer normalization stabilizes training by normalizing each layer’s output to have zero mean and unit variance. This helps prevent issues like vanishing/exploding gradients, particularly when training deep networks.
Additionally, residual connections (skip connections) are employed, which involve adding the input of a layer to its output:
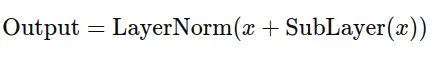
These connections allow the model to propagate information from earlier layers directly to later layers, improving gradient flow and overall model convergence.
Feed-Forward Neural Networks
Each Transformer layer contains a position-wise feed-forward neural network applied to each token independently. This network consists of two linear transformations with a ReLU activation in between:
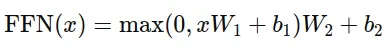
This allows for non-linear transformations on the token embeddings, increasing the representational capacity of the model.
ALSO READ:
Datasets and Training
The training of the Large Language Models (LLMs) is divided into two parts:
- Pre-Training with Large Datasets
- Fine-Tuning with Smaller Datasets
Pre-Training with Large Datasets
In this first training phase, LLMs require enormous datasets, which are often noisy and low-quality, but they help capture a wide range of language patterns, facts, and nuances. Pre-training is the process where LLMs are trained on vast amounts of unlabeled data (e.g., books, articles, and web pages) to learn general language features.
During this stage, the model learns to predict missing words (masked language modeling) or the next word in a sentence (causal language modeling).
Fine-Tuning with Smaller Datasets
Once pre-trained, LLMs can be fine-tuned on smaller, task-specific high-quality datasets to optimize performance on specific applications, such as translation, question-answers, code generation, etc. Fine-tuning allows the model to leverage the general knowledge it gained during pre-training while adapting to the nuances of the target domain.
Additional Considerations
Parameters
Modern LLMs are characterized by their enormous number of parameters. For instance, GPT-3 has 175 billion parameters. These parameters represent the weights in the model and govern the transformations applied to the input data. The larger the number of parameters, the more capacity the model has to capture complex patterns, which also requires more memory and computational power.
Computational Cost
Training large-scale LLMs demands significant computational resources, often involving TPUs or GPUs. Depending on the model size and dataset, the process can take weeks or months. For example, GPT-3 required thousands of petaflop/s-days of computation to train.
This computational burden is a significant factor driving the need for high-performance hardware and distributed training setups. The hardware, electricity, and time costs must be considered, particularly for institutions without access to large-scale infrastructure.
Inference
Even after training, LLMs can be computationally expensive during inference (i.e., when making predictions on new data). Optimization techniques like model pruning, quantization, and distillation help reduce the size and speed up inference without sacrificing too much performance.
Other Considerations
Other critical aspects include managing bias in data, which can lead to harmful outputs, and addressing privacy concerns when models are trained on sensitive data. Moreover, the environmental cost of training large models (regarding energy consumption) is becoming a pressing issue that researchers are beginning to tackle through more efficient training methods. It is critical to ensure that these models are used responsibly and transparently.
Conclusion
LLMs, powered by sophisticated architectures like Transformers, represent a leap forward in natural language understanding and generation. Their architecture and massive datasets enable them to generalize across various tasks. However, as these models grow in size and complexity, additional considerations, such as computational costs and ethical concerns, become increasingly important. As we move forward, balancing innovation with responsible use will be crucial for the future of LLMs in NLP.