Artificial intelligence (AI) has made remarkable progress in recent years, particularly in natural language processing (NLP). One of the most significant developments has been the rise of large language models (LLMs)—powerful models that can easily understand and generate human language. These models have revolutionized various industries, enabling everything from automatic translation and content creation to more sophisticated conversational agents. This article briefly examines the history of LLMs, tracing their development from early methods to the cutting-edge models we have today.
What are Large Language Models (LLMs)?
Large Language Models (LLMs) are expansive, general-purpose models for processing human language. They are initially trained on vast datasets covering diverse topics, allowing them to grasp the underlying structure, meaning, and language patterns. The “large” aspect refers to the immense volume of data used during training and the scale of the model itself, which often consists of billions or even trillions of parameters. This extensive pre-training enables LLMs to excel in tasks like text classification, question answering, and summarization.
Following pre-training, LLMs are often fine-tuned using smaller, domain-specific datasets tailored to specialized fields, such as finance or healthcare. This fine-tuning process enhances their performance for particular applications, making them adaptable to general language tasks and specific, focused problems.
Historical Evolution of Large Language Models (LLMs)
- 1990: N-grams
- 2000: Neural Networks for Language Modeling
- 2013: Word2Vec
- 2014: RNN(LSTM & GRU)
- 2015: Seq2Seq with Attention
- 2017: Transformers (Attention Is All You Need)
- 2018: BERT & GPT
- 2019: GPT-2
- 2020: GPT-3
- 2022: ChatGPT
- 2023: GPT-4
1990: N-grams
The introduction of N-gram models in the 1990s marked a crucial milestone in statistical language modeling. These models operate by calculating the likelihood of a word based on the previous few words in a sequence, providing a simple yet effective way of capturing local context in language. N-grams work by analyzing sequences of “n” words to predict the next word, where “n” could represent unigrams (single words), bigrams (two words), trigrams (three words), and so on.
Although limited by their inability to handle long-range dependencies or capture deeper linguistic patterns, N-gram models laid the foundation for later advancements. Their real-world impact was seen in applications like Google’s PageRank algorithm, which used N-gram analysis to evaluate word co-occurrences across web pages, boosting search result relevance.
2000: Neural Networks for Language Modeling
Research Paper: A Neural Probabilistic Language Model
In 2000, Yoshua Bengio introduced neural networks for language modeling, which marked a significant leap forward. Neural networks introduced the ability to learn complex patterns in data, capturing richer, more meaningful linguistic representations than N-grams. Unlike traditional statistical models, neural networks can model non-linear relationships and are better suited for capturing long-range dependencies within text.
Yoshua Bengio and his team introduced the model, which used a feedforward neural network to predict the next word in a sentence based on previous words. It introduced the concept of a distributed “feature vector” for each word (a real-valued vector in Rm), similar to word embeddings.
These feature vectors allowed the model to represent words as vectors in a continuous space, significantly improving the understanding of word similarities and relationships and setting the stage for future language models.
2013: Word2Vec
Research Paper: Efficient Estimation of Word Representations in Vector Space
Google’s Word2Vec, introduced in 2013, revolutionized how words were represented in machine learning models by creating word embeddings—dense vector representations of words in continuous space. Word2Vec uses two main techniques: Continuous Bag of Words (CBOW) and Skip-gram. CBOW predicts a word based on its context (surrounding words), while Skip-gram does the opposite by predicting the context given the word.

Word2Vec model can capture semantic relationships between words based on their co-occurrence in text, enabling the model to understand, for example, that “king” is to “queen” as “man” is to “woman.” This shift to vector-based representations marked a massive improvement in handling semantics and was foundational to many NLP systems.
2014: RNN (LSTM & GRU)
Research Paper:
- LSTM: Long Short-Term Memory
- GRU: Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation
Although Long-Short-Term Memory (LSTM) networks were originally introduced in 1997, they gained widespread adoption in 2014 alongside Gated Recurrent Units (GRU). Both LSTM and GRU are advanced variants of Recurrent Neural Networks (RNNs) designed to overcome the limitations of traditional RNNs, particularly the vanishing gradient problem.

LSTMs introduced memory cells and gating mechanisms that allow models to retain important information over long sequences, improving their ability to handle long-range dependencies in text.
GRUs, introduced in 2014, simplified the architecture of LSTMs by combining certain gates, making them computationally more efficient while retaining similar performance.
The popularity of LSTM and GRU models in 2014 marked a significant advancement in tasks requiring sequential data processing, such as machine translation, speech recognition, and time-series prediction.
2015: Seq2Seq with Attention
Research Paper: Neural Machine Translation by Jointly Learning to Align and Translate
The Seq2Seq (Sequence-to-Sequence) model, introduced with attention mechanisms in 2015, transformed how language models handled tasks like translation and summarization. Seq2Seq architecture consists of two parts: an encoder and a decoder.
The encoder processes input sequences while the decoder generates the output sequence. The attention mechanism was a major innovation, allowing the model to focus on relevant parts of the input sequence when producing each word in the output. This significantly improved performance in tasks involving long sequences by enabling the model to retain and use information from any input part rather than just the final hidden state.
2017: Transformers (Attention Is All You Need)
Research Paper: Attention Is All You Need
In 2017, the Transformer architecture, introduced in the paper “Attention Is All You Need,” revolutionized natural language processing. Transformers replaced the need for recurrence in RNNs with self-attention mechanisms, allowing the model to capture relationships between all words in a sequence simultaneously.
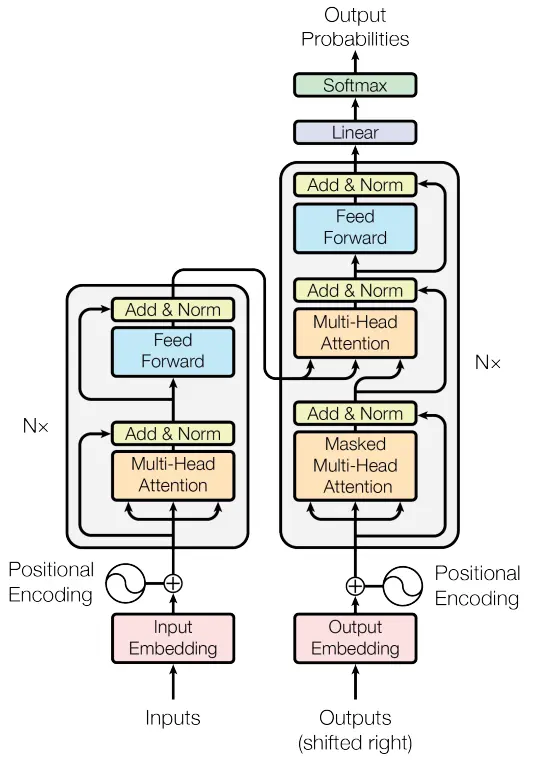
This parallel processing significantly boosted computational efficiency and the ability to capture long-range dependencies, making the Transformer model highly scalable for large datasets. It formed the backbone of subsequent language models like BERT and GPT, leading to breakthroughs in tasks like translation, summarization, and question-answering.
2018: BERT & GPT
Research paper:
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- GPT: Improving Language Understanding by Generative Pre-Training
In 2018, two significant models emerged that further advanced the capabilities of LLMs: BERT (Bidirectional Encoder Representations from Transformers) by Google and GPT (Generative Pre-trained Transformer) by OpenAI.
BERT introduced bidirectional training, which could consider preceding and following words when understanding context, improving tasks like question answering and text classification.

GPT, on the other hand, focused on generative tasks by pre-training on large datasets and fine-tuning for specific tasks, showcasing remarkable ability in text generation.
Together, these models showed Transformers’ versatility in understanding and generating language.
2019: GPT-2
Research Paper: Language Models are Unsupervised Multitask Learners
GPT-2, launched by OpenAI in 2019, built on GPT’s success by scaling up the model to 1.5 billion parameters, significantly improving its ability to generate coherent, human-like text. GPT-2’s ability to generate high-quality, contextually relevant text across diverse topics without task-specific fine-tuning demonstrated the power of large-scale pre-training.
However, due to concerns about misuse, GPT-2 was initially withheld from public release, highlighting ethical considerations in deploying powerful language models.
2020: GPT-3
Research Paper: Language Models are Few-Shot Learners
OpenAI’s GPT-3, released in 2020, further pushed the boundaries of language modeling with a staggering 175 billion parameters. This massive scale enabled GPT-3 to perform various tasks—such as translation, summarization, and even programming—with minimal instruction or fine-tuning. Its ability to generate highly coherent and contextually accurate text set a new standard in NLP, making GPT-3 one of the most influential and versatile language models available. GPT-3 also popularized the concept of few-shot learning, where the model could generalize tasks with just a few examples.

2022: ChatGPT
In 2022, OpenAI launched ChatGPT, a model fine-tuned from GPT-3.5 specifically for conversational AI. ChatGPT was designed to generate more engaging and human-like dialogue, making it suitable for customer service, virtual assistants, and educational tools. ChatGPT demonstrated the practical applications of large-scale language models in everyday communication by focusing on interactivity and conversation coherence. It became widely used for answering questions, creative writing, and real-time conversations, making AI-driven dialogue more accessible and human-like.
2023: GPT-4
Research Paper: GPT-4 Technical Report
GPT-4, a large multimodel language model, was released in 2023 and built upon the advancements of GPT-3. It offers improved understanding of nuanced prompts, greater accuracy in reasoning, and enhanced handling of ambiguous or incomplete information.
A significant improvement over its predecessor was the incorporation of fine-tuning through reinforcement learning, where feedback from both humans and AI systems was used to align the model with human values and ensure policy compliance.
While GPT-3 excelled at general language generation, GPT-4 was designed to handle more complex tasks, including deeper reasoning and problem-solving. GPT-4’s enhanced capabilities make it suitable for specialized domains like legal reasoning, scientific research, and advanced educational tools, representing a further step toward more intelligent, context-aware AI systems.
Conclusion
The journey of Large Language Models (LLMs) from the simple N-gram models of the 1990s to the sophisticated, multi-billion parameter models like GPT-4 reflects the rapid evolution in natural language processing. Early models, such as N-grams and the first neural networks, laid the groundwork for capturing linguistic patterns and dependencies. With the introduction of word embeddings like Word2Vec and GloVe, language understanding became more nuanced as models began to represent words in vector spaces that captured semantic relationships. Recurrent models such as LSTMs and GRUs brought improvements in handling sequential data, paving the way for Seq2Seq models with attention, which significantly improved performance on tasks like translation.
The breakthrough came with the Transformer model in 2017, which revolutionized NLP by discarding recurrence in favor of self-attention mechanisms, greatly enhancing efficiency and scalability. This innovation led to developing powerhouse models like BERT and GPT, each excelling in language understanding and generation. The advent of GPT-2 and GPT-3 highlighted the immense potential of large-scale pre-training and fine-tuning, with GPT-3 setting a new standard for few-shot learning and general language tasks.
Finally, GPT-4 represents the latest achievement in this evolution, combining advanced reasoning with human-aligned training methods. By incorporating reinforcement learning feedback from humans and AI, GPT-4 demonstrates a commitment to ethical considerations and policy compliance, ensuring that AI is powerful and responsible. As LLMs continue to evolve, they promise to revolutionize even more industries, offering sophisticated solutions to various tasks while adhering to ethical standards. This evolution underscores the potential for language models to become even more integrated into daily life, providing intelligent and reliable assistance across various domains.