In recent posts, we’ve built a strong foundation around multiclass image segmentation using PyTorch. From creating segmentation masks, converting RGB to class index masks, overlaying results using OpenCV, to training a full-fledged UNet model and visualizing it with GradCAM, we’ve covered the full training pipeline. But what happens when your trained model doesn’t generalize perfectly to real-world test data? That’s where Test Time Augmentation (TTA) comes in — a simple yet powerful inference-time technique that can significantly boost segmentation accuracy without retraining your model.
In this blog post, we take our previously trained weed segmentation model (U-Net on an augmented weed dataset) and apply TTA to improve prediction robustness and accuracy. Whether you’re working with semantic segmentation in agriculture, healthcare, or autonomous driving, this technique can easily integrate into your pipeline for more reliable results.
Let’s dive in and get your segmentation model performing even better — without touching a single training epoch.
Code: Multiclass Segmentation in PyTorch
What is Test Time Augmentation (TTA)?
Test Time Augmentation refers to applying data augmentation not just during training, but also at inference time. The concept is simple:
Perform inference on multiple augmented versions of the same test image, and combine the predictions (typically by averaging) to produce a final output.
Think of it as a lightweight ensemble technique — one that doesn’t require training multiple models but still yields a performance boost.
Example Augmentations at Test Time:
- Horizontal flip
- Vertical flip
- Rotation
- Color jitter (less common at test time)
For semantic segmentation, we augment the input image, predict the mask, invert the transformation, and finally aggregate the predictions.

Why Use TTA for Image Segmentation?
In real-world datasets, images can vary slightly in orientation, lighting, or perspective. A model trained on clean, well-aligned data may fail to generalize perfectly. This is where TTA comes to the rescue.
Benefits of TTA:
- Better generalization: TTA makes predictions more robust across subtle image variations.
- Improved metrics: It can boost F1-score and IoU (Jaccard Index) by refining boundary segmentation.
- Low cost: No retraining required; just inference-time enhancement.
In our weed segmentation task — distinguishing between background, Weed-1, and Weed-2 — even minor improvements in class boundary prediction can make a big difference in real-world agricultural applications.
Implementation: Test Time Augmentation in PyTorch
Let’s break the implementation into logical blocks and walk through each one with explanations.
Setup & Imports
First, set the environment and import all required libraries:
import os, time
import numpy as np
import cv2
import torch
from tqdm import tqdm
from model import build_unet
from utils import create_dir, seeding
from train import load_data
from sklearn.metrics import f1_score, jaccard_score
Convert Predicted Indices to RGB Mask
This function maps each class index to its corresponding RGB color for visualization.
def index_to_rgb_mask(mask, colormap):
height, width = mask.shape
rgb_mask = np.zeros((height, width, 3), dtype=np.uint8)
for class_id, rgb in enumerate(colormap):
rgb_mask[mask == class_id] = rgb
return rgb_mask
You might remember this function from our earlier blog on RGB to Class Index Mask Conversion.
Test Time Augmentation Logic
This is the heart of the blog post.
def TTA(model, image_tensor):
model.eval()
predictions = []
with torch.no_grad():
# Original
pred_orig = model(image_tensor)
predictions.append(torch.softmax(pred_orig, dim=1))
# Horizontal Flip
img_hflip = torch.flip(image_tensor, dims=[3])
pred_hflip = model(img_hflip)
pred_hflip = torch.flip(torch.softmax(pred_hflip, dim=1), dims=[3])
predictions.append(pred_hflip)
# Vertical Flip
img_vflip = torch.flip(image_tensor, dims=[2])
pred_vflip = model(img_vflip)
pred_vflip = torch.flip(torch.softmax(pred_vflip, dim=1), dims=[2])
predictions.append(pred_vflip)
# Horizontal + Vertical Flip
img_hvflip = torch.flip(image_tensor, dims=[2, 3])
pred_hvflip = model(img_hvflip)
pred_hvflip = torch.flip(torch.softmax(pred_hvflip, dim=1), dims=[2, 3])
predictions.append(pred_hvflip)
# Average predictions and take argmax
mean_pred = torch.stack(predictions, dim=0).mean(dim=0)
final_pred = torch.argmax(mean_pred, dim=1)
return final_pred.squeeze(0).cpu().numpy().astype(np.uint8)
Note: All augmentations are undone post-inference to keep alignment intact before averaging.
Main Function: Executing the TTA
This function:
- Loads test images
- Applies TTA
- Saves overlayed mask predictions
- Computes F1 Score and IoU per class
if __name__ == "__main__":
""" Seeding """
seeding(42)
""" Hyperparameters """
image_w = 256
image_h = 256
size = (image_w, image_h)
dataset_path = "./Weeds-Dataset/weed_augmented"
colormap = [
[0, 0, 0], # Background
[0, 0, 128], # Class 1
[0, 128, 0] # Class 2
]
num_classes = len(colormap)
classes = ["background", "Weed-1", "Weed-2"]
""" Load the checkpoint """
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = build_unet(num_classes=num_classes)
model = model.to(device)
checkpoint_path = "files/checkpoint.pth"
model.load_state_dict(torch.load(checkpoint_path, map_location=device)["model_state_dict"])
model.eval()
""" Test dataset """
(train_x, train_y), (valid_x, valid_y), (test_x, test_y) = load_data(dataset_path)
save_path = f"results_tta"
for item in ["mask", "joint"]:
create_dir(f"{save_path}/{item}")
evaluate(model, save_path, test_x, test_y, size, colormap, classes)
Results are stored in a CSV (score_tta.csv) for future reference or plotting.
Results: Accuracy Boost via TTA
After applying TTA, we observed a notable improvement in both F1 Score and Jaccard Index across all three classes.
The table shows the results before applying Test Time Augmentation.
| Class | F1 | IoU |
|---|---|---|
| Background | 0.97248 | 0.94768 |
| Weed-1 | 0.59912 | 0.52433 |
| Weed-2 | 0.41946 | 0.38736 |
| Mean (Weed-1 & Weed-2) | 0.50929 | 0.45584 |
The table shows the results after applying Test Time Augmentation.
| Class | F1 | IoU |
|---|---|---|
| Background | 0.97726 | 0.95647 |
| Weed-1 | 0.61521 | 0.54610 |
| Weed-2 | 0.43004 | 0.40347 |
| Mean (Weed-1 & Weed-2) | 0.52263 | 0.47479 |
From the tables, we can observe a 1.33% improvement in F1 and 1.89% in IoU.
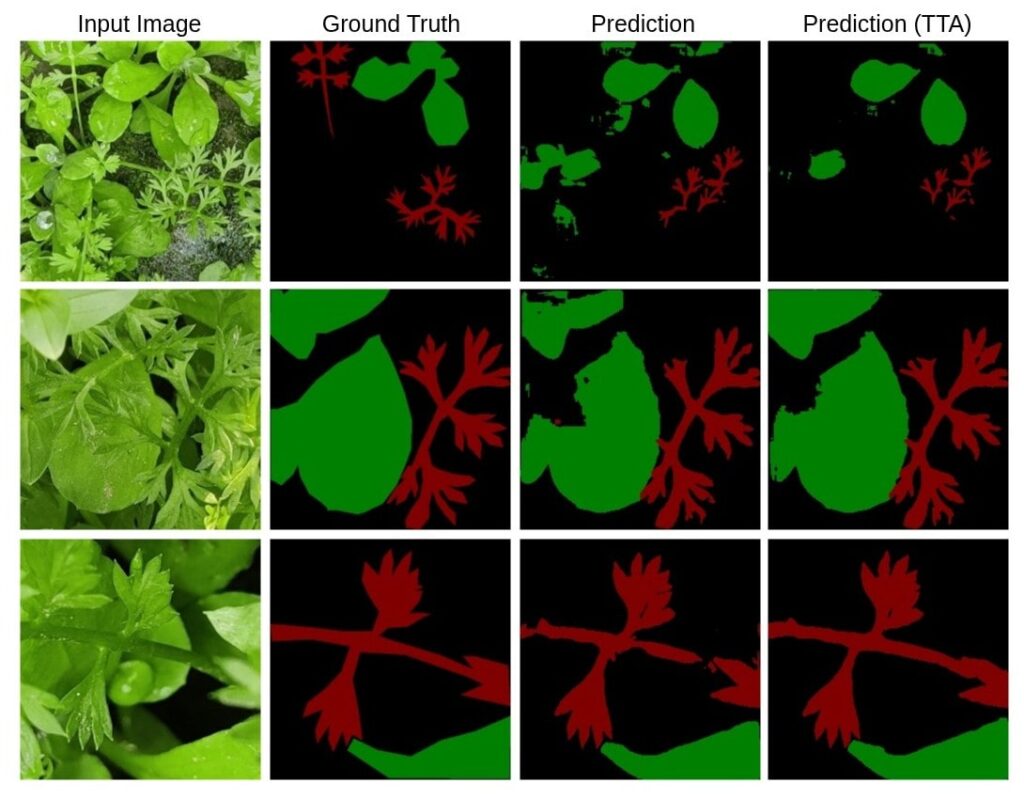
Visual results saved in /results_tta
Conclusion
Test Time Augmentation (TTA) is an easy yet powerful technique that can be added to your existing segmentation pipelines with minimal changes. For our weed segmentation model, we saw significant improvements in F1 and IoU — critical for applications like smart farming and weed detection.
By combining this post with insights from:
- Extracting RGB Codes from Segmentation Masks
- Converting RGB Masks to Class Indexes
- Overlaying Masks on Images
you now have a complete pipeline for training, visualizing, and improving multiclass segmentation models.
If you found this helpful, consider starring the GitHub repo or sharing it with others working in computer vision!