RESUNET refers to Deep Residual UNET. It’s an encoder-decoder architecture developed by Zhengxin Zhang et al. for semantic segmentation. It was initially used for the road extraction from the high-resolution aerial images in the field of remote sensing image analysis. Later, it was adopted by researchers for multiple other applications such as polyp segmentation, brain tumour segmentation, human image segmentation, and many more.
Original Paper: Road Extraction by Deep Residual U-Net
RESUNET is a fully convolutional neural network that is designed to get high performance with fewer parameters. It is an improvement over the existing UNET architecture. RESUNET takes the advantage of both the UNET architecture and the Deep Residual Learning.
Advantages of RESUNET
- The use of residual blocks helps in building a deeper network without worrying about the problem of vanishing gradient or exploding gradients. It also helps in easy training of the network.
- The rich skip connections in the RESUNET helps in better flow of information between different layers, which helps in better flow of gradients while training (backpropagation).
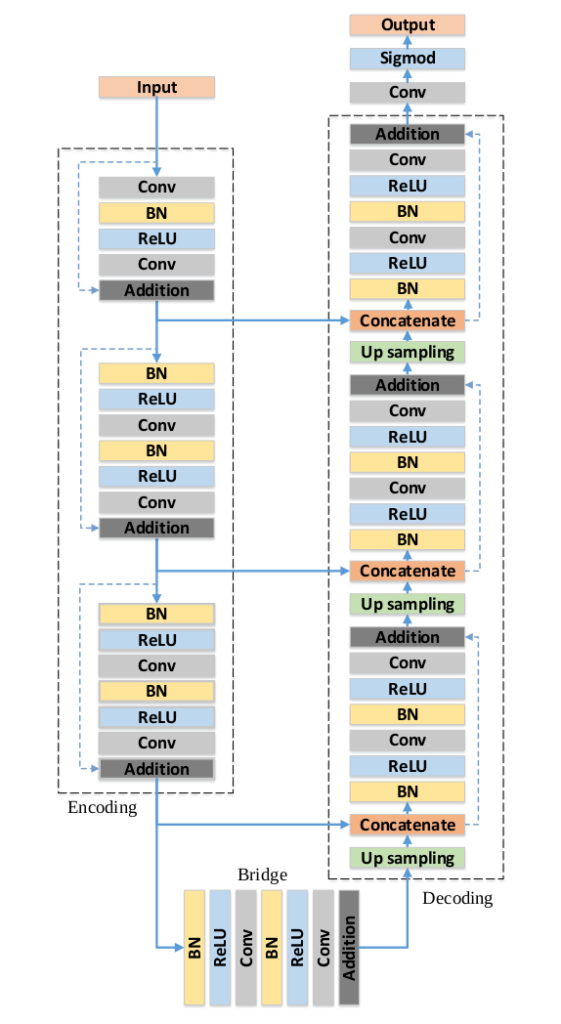
Overall Architecture of RESUNET
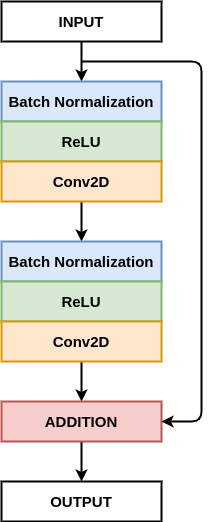
The RESUNET consists of an encoding network, decoding network and a bridge connecting both these networks, just like a U-Net. The U-Net uses two 3 x 3 convolution, where each is followed by a ReLU activation function. In the case of RESUNET, these layers are replaced by a pre-activated residual block.
Encoder
The encoder takes the input image and passes it through different encoder blocks, which helps the network to learn an abstract representation. The encoder consists of three encoder blocks, which are built using the pre-activated residual block. The output of each encoder block acts as a skip connection for the corresponding decoder block.
To reduce the spatial dimensions (height and width) of the feature maps, the first 3×3 convolution layer uses a stride of 2 in the second and the third encoder block. A stride value of 2 reduces the spatial dimensions by half, i.e. 256 to 128.
Bridge
The bridge also consists of a pre-activated residual block with a stride value of 2.
Decoder
The decoder takes the feature map from the bridge and the skip connections from different encoder block and learns a better semantic representation, which is used to generate a segmentation mask.
The decoder consists of three decoder blocks, and after each block, the spatial dimensions of the feature map are doubles and the number of feature channels is reduced.
Each decoder block begins with a 2×2 upsampling, which doubles the spatial dimensions of the feature maps. Next, these feature maps are then concatenated with the appropriate skip connection from the encoder block. These skip connections help the decoder blocks to get the feature learned by the encoder network. After this, the feature maps from the concatenation operation are passes through a pre-activated residual block.
The output of the last decoder passes through a 1×1 convolution with sigmoid activation. The sigmoid activation function gives the segmentation mask representing the pixel-wise classification.
TensorFlow (Keras) Code
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, UpSampling2D, Concatenate, Input
from tensorflow.keras.models import Model
def batchnorm_relu(inputs):
""" Batch Normalization & ReLU """
x = BatchNormalization()(inputs)
x = Activation("relu")(x)
return x
def residual_block(inputs, num_filters, strides=1):
""" Convolutional Layers """
x = batchnorm_relu(inputs)
x = Conv2D(num_filters, 3, padding="same", strides=strides)(x)
x = batchnorm_relu(x)
x = Conv2D(num_filters, 3, padding="same", strides=1)(x)
""" Shortcut Connection (Identity Mapping) """
s = Conv2D(num_filters, 1, padding="same", strides=strides)(inputs)
""" Addition """
x = x + s
return x
def decoder_block(inputs, skip_features, num_filters):
""" Decoder Block """
x = UpSampling2D((2, 2))(inputs)
x = Concatenate()([x, skip_features])
x = residual_block(x, num_filters, strides=1)
return x
def build_resunet(input_shape):
""" RESUNET Architecture """
inputs = Input(input_shape)
""" Endoder 1 """
x = Conv2D(64, 3, padding="same", strides=1)(inputs)
x = batchnorm_relu(x)
x = Conv2D(64, 3, padding="same", strides=1)(x)
s = Conv2D(64, 1, padding="same")(inputs)
s1 = x + s
""" Encoder 2, 3 """
s2 = residual_block(s1, 128, strides=2)
s3 = residual_block(s2, 256, strides=2)
""" Bridge """
b = residual_block(s3, 512, strides=2)
""" Decoder 1, 2, 3 """
x = decoder_block(b, s3, 256)
x = decoder_block(x, s2, 128)
x = decoder_block(x, s1, 64)
""" Classifier """
outputs = Conv2D(1, 1, padding="same", activation="sigmoid")(x)
""" Model """
model = Model(inputs, outputs, name="RESUNET")
return model
if name == "main":
shape = (224, 224, 3)
model = build_resunet(shape)
model.summary()



