
In this article, we are going to learn about the Attention UNET and then implement it in the PyTorch framework. Attention UNET is a type of Convolutional Neural Network (CNN) that is commonly used for image segmentation tasks. It is an extension of the original U-Net architecture, which was proposed for biomedical image segmentation. Attention UNET combines the UNET with the novel Attention Gate which helps the network focus on relevant regions and boost performance.
Attention UNET = UNET + Attention Gate
What is Attention UNET?

In short, we can say Attention UNET is an encoder-decoder style of architecture that combines the strengths of the UNET and the proposed Attention Gate. The key innovation of Attention U-Net is the incorporation of an attention mechanism, which helps the network focus on relevant regions of the input image while filtering out noise and irrelevant information.
Research Paper: Attention U-Net: Learning Where to Look for the Pancreas
Attention Gate
The Attention Gate is a spatial attention module that helps in highlighting the important regions of the feature map and suppressing the irrelevant ones. It is inserted in the decoder part of the Attention UNET.
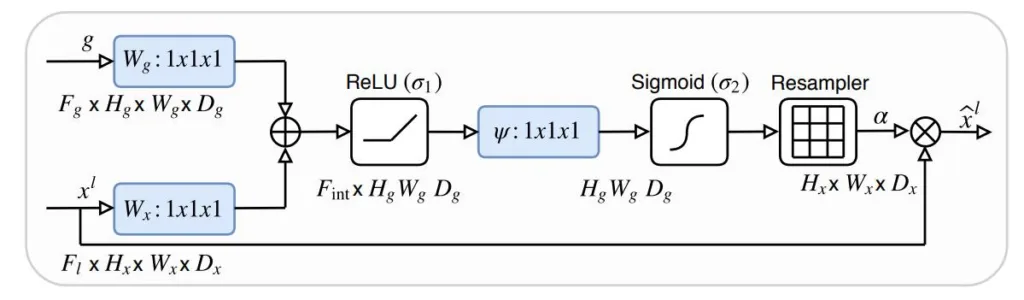
It consists of a series of convolutional layers, which are added and followed by a ReLU activation. Next, it again has a convolutional layer followed by the sigmoid activation function. The sigmoid activation function generates an attention map with values between 0 and 1. The attention map is then multiplied with the input feature map (skip connection).
Implementation of the Attention UNET in PyTorch
First, we are going to import the torch module.
import torch
import torch.nn as nn
Next, we are going to define the conv_block, which is simply a sequence of two 3×3 convolution layers. Each is followed by a batch normalization and a ReLU activation function.
class conv_block(nn.Module):
def __init__(self, in_c, out_c):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_c, out_c, kernel_size=3, padding=1),
nn.BatchNorm2d(out_c),
nn.ReLU(inplace=True),
nn.Conv2d(out_c, out_c, kernel_size=3, padding=1),
nn.BatchNorm2d(out_c),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
Now, we will use the conv_block to build the encoder_block.
class encoder_block(nn.Module):
def __init__(self, in_c, out_c):
super().__init__()
self.conv = conv_block(in_c, out_c)
self.pool = nn.MaxPool2d((2, 2))
def forward(self, x):
s = self.conv(x)
p = self.pool(s)
return s, p
Now, we will implement the proposed Attention Gate. It takes two input features:
- Gating Signal: It is the previous feature map.
- Skip connection: It is the feature from the encoder having same spatial resolution.
class attention_gate(nn.Module):
def __init__(self, in_c, out_c):
super().__init__()
self.Wg = nn.Sequential(
nn.Conv2d(in_c[0], out_c, kernel_size=1, padding=0),
nn.BatchNorm2d(out_c)
)
self.Ws = nn.Sequential(
nn.Conv2d(in_c[1], out_c, kernel_size=1, padding=0),
nn.BatchNorm2d(out_c)
)
self.relu = nn.ReLU(inplace=True)
self.output = nn.Sequential(
nn.Conv2d(out_c, out_c, kernel_size=1, padding=0),
nn.Sigmoid()
)
def forward(self, g, s):
Wg = self.Wg(g)
Ws = self.Ws(s)
out = self.relu(Wg + Ws)
out = self.output(out)
return out *
Now, we will use both the conv_block and the attention_gate to implement the decoder_block.
class decoder_block(nn.Module):
def __init__(self, in_c, out_c):
super().__init__()
self.up = nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True)
self.ag = attention_gate(in_c, out_c)
self.c1 = conv_block(in_c[0]+out_c, out_c)
def forward(self, x, s):
x = self.up(x)
s = self.ag(x, s)
x = torch.cat([x, s], axis=1)
x = self.c1(x)
return x
Finally, we will use all the blocks defined above and implement the attention_unet.
class attention_unet(nn.Module):
def __init__(self):
super().__init__()
self.e1 = encoder_block(3, 64)
self.e2 = encoder_block(64, 128)
self.e3 = encoder_block(128, 256)
self.b1 = conv_block(256, 512)
self.d1 = decoder_block([512, 256], 256)
self.d2 = decoder_block([256, 128], 128)
self.d3 = decoder_block([128, 64], 64)
self.output = nn.Conv2d(64, 1, kernel_size=1, padding=0)
def forward(self, x):
s1, p1 = self.e1(x)
s2, p2 = self.e2(p1)
s3, p3 = self.e3(p2)
b1 = self.b1(p3)
d1 = self.d1(b1, s3)
d2 = self.d2(d1, s2)
d3 = self.d3(d2, s1)
output = self.output(d3)
return output
Now, we will execute the attention_unet.
if __name__ == "__main__":
x = torch.randn((8, 3, 256, 256))
model = attention_unet()
output = model(x)
print(output.shape)
Summary
In summary, Attention UNET is an improvement over the existing UNET architecture with the addition of the proposed Attention Gate. The Attention Gate helps in highlighting the important features and suppressing the irrelevant ones. In this way, it helps in boosting overall performance.
Still, have some questions or queries? Just comment below. For more updates. Follow me.




