In the article, we will go through the paper Attention U-Net: Learning Where to Look for the Pancreas. It was written by Ozan Oktay et. al in the year 2018 at the MIDL (Medical Imaging with Deep Learning) conference. The Attention UNET introduces a novel Attention Gate that enables the UNET architecture to focus on the important regions or structures with different shapes and sizes.
Research Paper: Attention U-Net: Learning Where to Look for the Pancreas
Table of Content
- What is UNET?
- Why is attention needed in the UNET?
- Implementation of the Attention UNET.
- Summary
What is UNET?
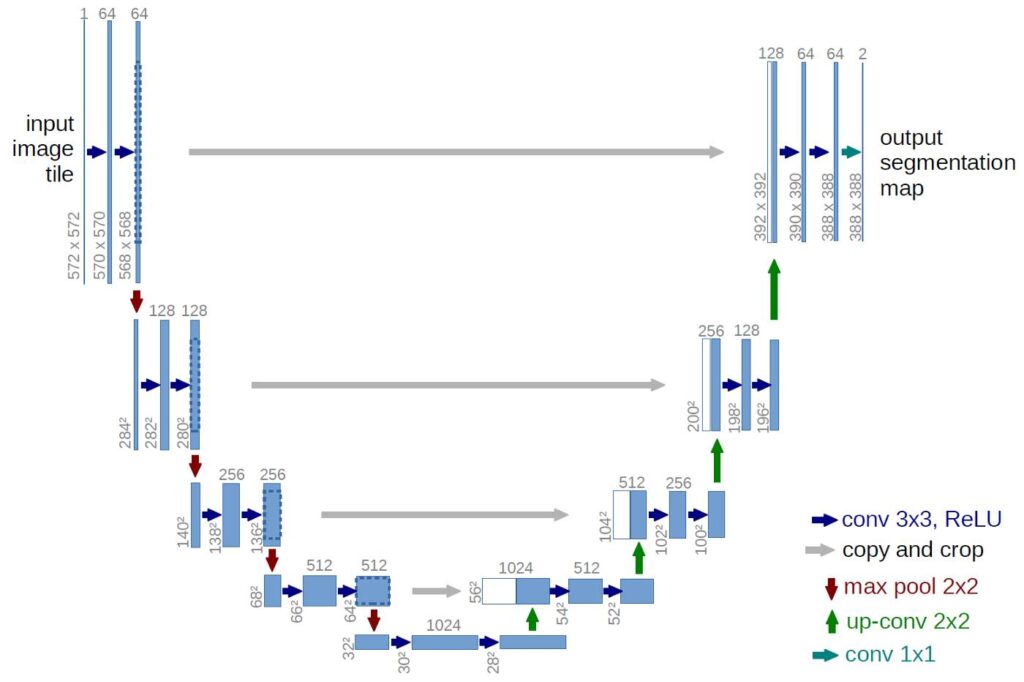
UNET is an architecture developed by Olaf Ronneberger et al. for Biomedical Image Segmentation in 2015 at the University of Freiburg, Germany. It is one of the most popularly used approaches in any semantic segmentation task today. UNET is a U-shaped encoder-decoder network architecture consisting of four encoder blocks and four decoder blocks connected via a bridge. The encoder network (contracting path) has half the spatial dimensions and double the number of filters (feature channels) at each encoder block. Likewise, the decoder network doubles the spatial dimensions and half the number of feature channels.
READ MORE
Why is attention needed in the UNET?
Attention is an important aspect of any computer vision task where we need to focus on specific regions in an image. Regarding image segmentation, attention is a massive help in highlighting the important regions of the image. Due to this the model converges much faster and has better generalisation capabilities.
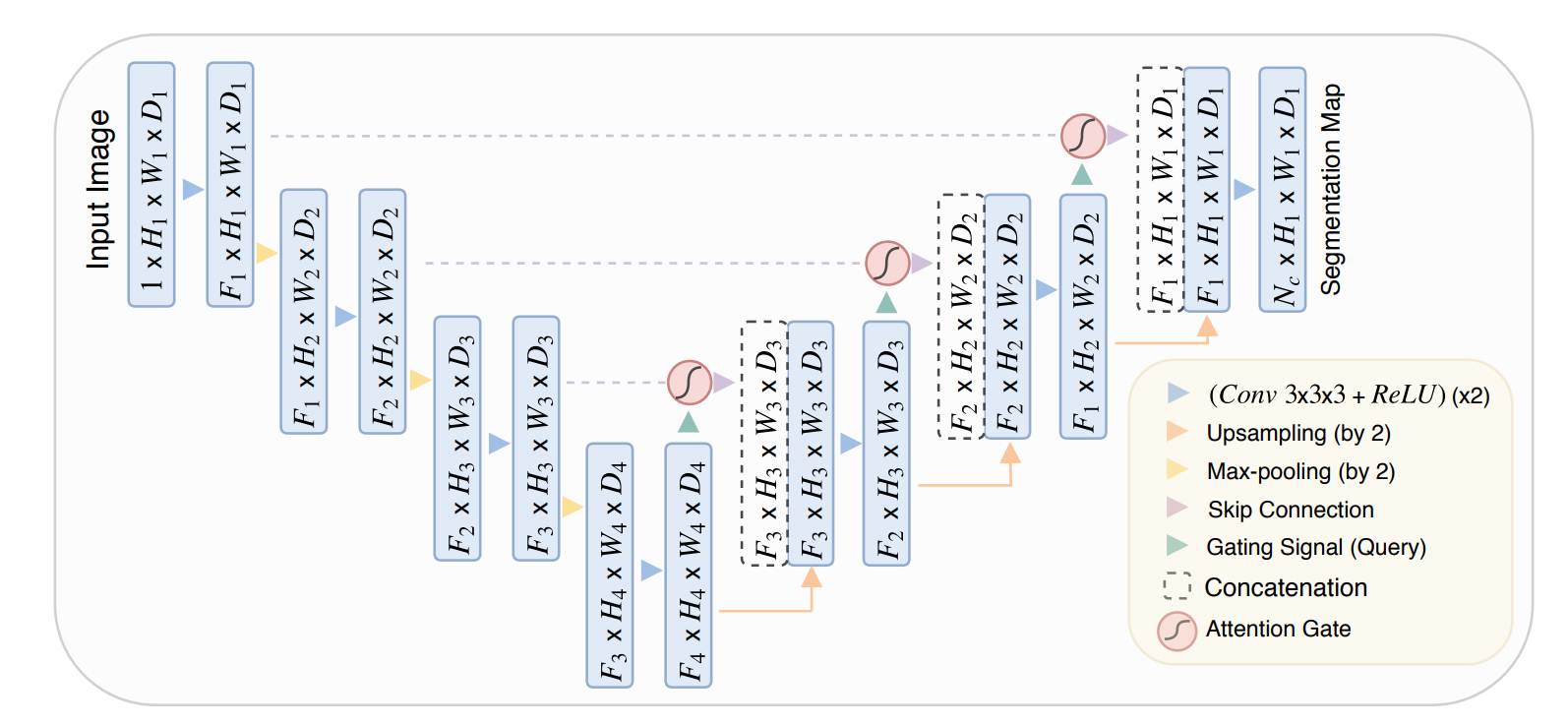
Here in Attention UNET, the author proposes a novel spatial attention mechanism called Attention Gate (AG). The Attention Gate helps to focus on target structures of varying shapes and sizes in medical images.
The models trained with Attention Gate implicitly learn to suppress irrelevant regions in an input image while highlighting salient features useful for a specific task. This enables us to eliminate the necessity of using any explicit localisation modules.
The Attention Gate can be easily integrated into any existing segmentation architecture such as U-Net with a minimal increase in the parameters. This increase in parameters boosts the model’s sensitivity and accuracy.
Implementation of the Attention UNET.

First of all, we are going to import the required libraries.
import tensorflow as tf
import tensorflow.keras.layers as L
from tensorflow.keras.models import Model
Next, we will define a simple conv_block, which consists of two 3×3 convolution layers, each followed by a batch normalization and ReLU activation function.
def conv_block(x, num_filters):
x = L.Conv2D(num_filters, 3, padding="same")(x)
x = L.BatchNormalization()(x)
x = L.Activation("relu")(x)
x = L.Conv2D(num_filters, 3, padding="same")(x)
x = L.BatchNormalization()(x)
x = L.Activation("relu")(x)
return x
Now, we are going to use the conv_block define above to implement the encoder_block. The encoder_block consists of a conv_block followed by a 2×2 max-pooling layer.
def encoder_block(x, num_filters):
x = conv_block(x, num_filters)
p = L.MaxPool2D((2, 2))(x)
return x, p
After the encoder_block, comes the proposed attention_gate, which is the main novelty of the Attention U-Net. The attention gate is used inside the decoder block, which is used to highlight the features in the skip connection and suppress the irrelevant ones. This process helps to improve the model’s performance.
def attention_gate(g, s, num_filters):
Wg = L.Conv2D(num_filters, 1, padding="same")(g)
Wg = L.BatchNormalization()(Wg)
Ws = L.Conv2D(num_filters, 1, padding="same")(s)
Ws = L.BatchNormalization()(Ws)
out = L.Activation("relu")(Wg + Ws)
out = L.Conv2D(num_filters, 1, padding="same")(out)
out = L.Activation("sigmoid")(out)
return out * s
Now, we will define the decoder_block. The decoder_block begins with a bilinear upsampling and is then followed by the Attention Gate. The Attention Gate uses both the upsampled feature map and the skip connection feature map and provides a highlighted feature map. In the highlighted feature map, the irrelevant features are suppressed.
After that, the highlighted feature map is concatenated with the skip connection and then followed by a conv_block.
def decoder_block(x, s, num_filters):
x = L.UpSampling2D(interpolation="bilinear")(x)
s = attention_gate(x, s, num_filters)
x = L.Concatenate()([x, s])
x = conv_block(x, num_filters)
return x
Till now, we have defined the blocks required to build the Attention U-Net. Now, we will implement it.
def attention_unet(input_shape):
""" Inputs """
inputs = L.Input(input_shape)
""" Encoder """
s1, p1 = encoder_block(inputs, 64)
s2, p2 = encoder_block(p1, 128)
s3, p3 = encoder_block(p2, 256)
b1 = conv_block(p3, 512)
""" Decoder """
d1 = decoder_block(b1, s3, 256)
d2 = decoder_block(d1, s2, 128)
d3 = decoder_block(d2, s1, 64)
""" Outputs """
outputs = L.Conv2D(1, 1, padding="same", activation="sigmoid")(d3)
""" Model """
model = Model(inputs, outputs, name="Attention-UNET")
return
Let’s execute the attention_unet model.
if __name__ == "__main__":
input_shape = (256, 256, 3)
model = attention_unet(input_shape)
model.summary()
Summary
In summary, Attention UNET is an improvement over the existing UNET architecture with the addition of the proposed Attention Gate. The Attention Gate helps in highlighting the important features and suppressing the irrelevant ones. In this way, it helps in boosting overall performance.
Still, have some questions or queries? Just comment below. For more updates. Follow me.




