Convolutional Neural Network (CNN) is used to solve a wide range of visual tasks such as image classification, object detection, semantic segmentation, and many more. CNN consists of a series of convolutional layers with non-linear activation functions and some downsampling layers. These CNNs are able to capture hierarchical patterns and produce image representations.
Overview:
- What is Convolution Neural Network?
- Why Convolution Neural Network over Feed Forward Neural Network?
- Major Building Block of CNN
- Convolutional layer
- Activation layer
- Pooling layer
- Fully connected layer
What is Convolution Neural Network?
Convolutional Neural Network (CNN) or ConvNets for short is a class of deep neural networks popularly used for visual data analysis. This visual data can be in the form of images or videos. CNNs are inspired by the mammalian visual cortex. They were developed as a computational model for natural visual perception, similar to the human visual system. The applications of CNN include image classification, object detection, semantic segmentation, medical image analysis, and many more.
A Convolutional Neural Network (CNN) takes an input image, performs a series of operations on it and then classifies it under certain categories (Example: Cat or Dog). The result can vary depending upon the type of problem we are trying to solve. In the case of image classification, we get a label (probability score). In the case of semantic segmentation, we get the segmentation map in which each pixel is labeled with a class label.
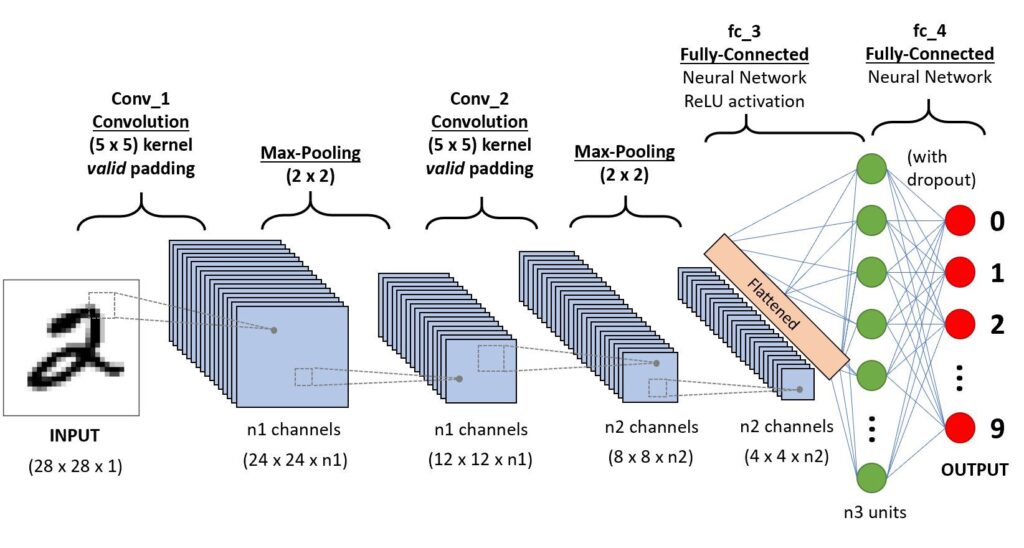
The basic architecture of a convolutional neural network (CNN) consists of the following layers:
- Convolutional layer – CONV
- Activation layer – ACT
- Pooling layer – POOL
- Fully-connected layer – FC
All these layers are used in some combination to build a convolutional neural network. For an image classification task, the general architecture is as follows:
INPUT-> [CONV -> ACT -> POOL] x N times -> [FC -> ACT] x M times -> OUTPUT
Why Convolution Neural Network over Feed Forward Neural Network?
Now the question arises, why do we need convolutional neural networks if we have a feed-forward neural network.
A feed-forward neural network can also be used for image classification instead of a convolutional neural network. Feed-forward neural networks take the input as a number of features (batch, features). For that, we need to flatten the image into a one-dimensional representation, due to which we lose the spatial information represented by the image. To take advantage of this spatial information, we use convolutional neural networks. A convolutional neural network takes the batches of the image as input without any modifications in their shapes. The input shape for a convolutional neural network is (batch, height, width, channels).
Feed-forward neural networks are very dense in nature, as they have a lot of trainable parameters (weights), which makes them prone to the problem of overfitting.
In case of convolutional neural network parameter sharing or weight sharing is there, so they have very fewer parameters as compared to the feed-forward neural network, due to which they take less time in training as compared to the feed-forward neural network.
Major Building Block of CNN
As we all know that a convolutional neural network is made of some layers that are stacked on top of each other. These layers form the building block of the convolutional neural network.
Convolutional Layer
The central building block of convolutional neural networks (CNN) is the convolution layer, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer.
The convolutional layer consists of the mathematical convolution operation, which takes two inputs, first the image matrix and a small kernel matrix. The kernel slides over the input image and produces the output feature map.
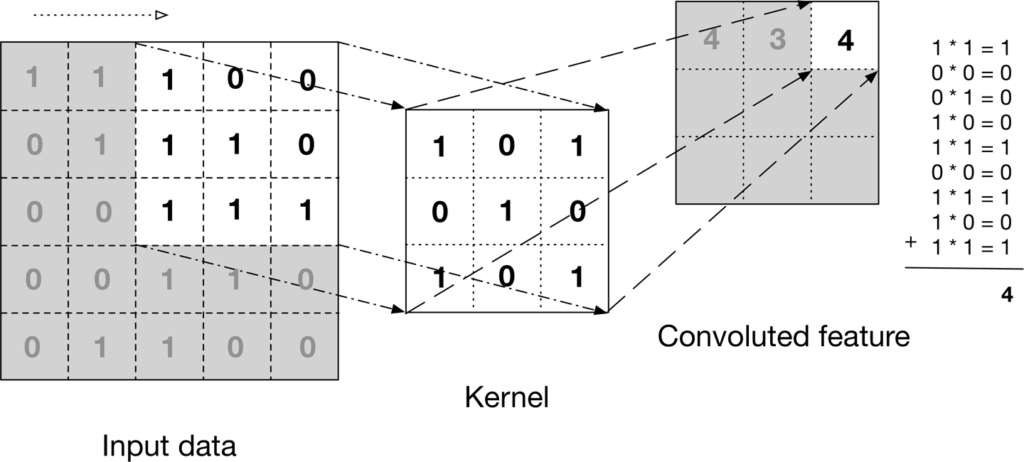
The aim of the convolution operation is to extract high-level features such as edges, lines, curves, etc from the input image. On a broad level, we can say the role of the convolution layer is to reduce the images into a form which is easier to process, without losing the essential features.
Activation Layer
The activation layer introduces non-linearity in the neural network. ReLU (Rectified Linear Unit) is the most popularly used activation function in the convolutional neural network. It is used in all the layers except the output layer. The activation function of the output layer depends upon the type of problem we are trying to solve. Like in the case of classification, we use sigmoid for single class and softmax for multiple classes.
Pooling Layer
The pooling layer is used to reduce the spatial dimensions i.e., height and width of the input feature maps. It helps to reduce the computational resources required to process the features maps by dimensionality reduction.
There are two major types of pooling:
- Max pooling
- Average pooling
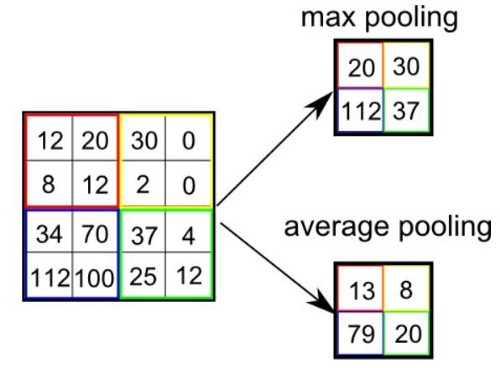
A pooling operation takes a kernel size and a stride value. The kernel size determines the patch size from the feature maps from which the values are to be extracted to create a new feature map. The stride value helps us shift over the feature maps.
Fully Connected Layer
After a series of convolutional, activation, and pooling layers, we flatten the incoming feature maps and feed them as input to the fully connected layers for classification.
The fully connected or dense layers take the flatten input features and the number of output features.
For example:
- B: Batch size
- H: Height
- W: Width
- N: Number of channels
The Input shape of features from the pooling layer is (B, H, W, N). Now, we flatten the feature maps by reshaping them into (B, H*W*N). Now we feed it in the fully connected layer with the number of output features be the O. The shape of the feature map given by the fully connected layer is (B, O).
After that we apply an activation function on the output of the fully connected layer, we get a probability score, which is used to determine the label for the input image.




