Human pose estimation is one of the most critical tasks in computer vision. It aims to localize anatomical key points (like shoulders, knees, and wrists) on the human body. Traditional convolutional neural networks (CNNs) have long dominated this field, but a new horizon has emerged with the advent of transformers in vision tasks. Enter ViTPose, a simple yet powerful architecture based on plain Vision Transformers (ViTs), which discards the complexity of hybrid CNN-transformer designs.
What is ViTPose?
At its core, ViTPose is a straightforward approach to human pose estimation using plain, non-hierarchical Vision Transformers as feature extractors. Instead of hybridizing CNNs and transformers (as many past methods do), ViTPose uses a pure transformer backbone like ViT-B, ViT-L, ViT-H, or ViTAE-G, followed by a light-weight decoder.
Paper: ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
Key Highlights:
- Simplicity: Minimalistic design, no domain-specific tricks.
- Scalability: From 100M to 1B+ parameters with stable improvements.
- Flexibility: Works with various input resolutions, pretraining strategies, and multi-task settings.
- Transferability: Large models can train smaller ones via knowledge tokens.
ViTPose employs a modular architecture:
- Backbone: Plain ViTs (e.g., ViT-B, ViT-L, ViT-H, ViTAE-G)
- Decoder: Classic or simplified deconvolution layers
- Training: Self-supervised with MAE or ImageNet
- Tasks: Single or multi-dataset 2D keypoint estimation
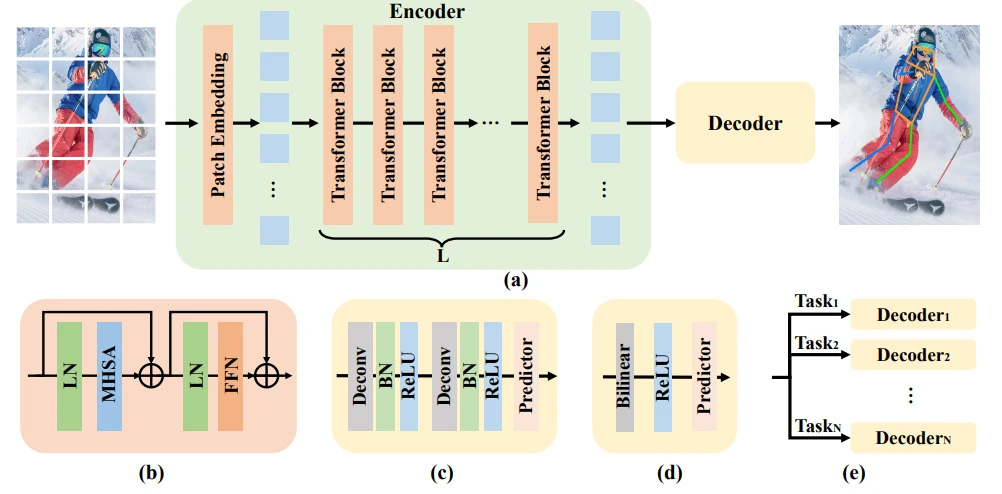
ViTPose Workflow
Input Image → Patch Embedding → Transformer Blocks → Feature Maps → Decoder → Keypoint Heatmaps
Core Components
The core components of the ViTPose are as follows:
- Patch Embedding and Transformer Encoder
- Decoder
Patch Embedding and Transformer Encoder
ViTPose first splits an input image into small fixed-size patches, which are then transformed into a sequence of tokens. These tokens are passed through a stack of transformer layers. Each layer consists of two main parts:
- Multi-Head Self-Attention (MHSA): Helps the model learn relationships between different parts of the image.
- Feed-Forward Network (FFN): Applies transformations to enrich the features.
This setup allows ViTPose to understand the image globally and capture long-range dependencies effectively.
Decoder Design
ViTPose uses two kinds of lightweight decoders:
- Classic Decoder: Upsamples the feature maps through two deconvolution layers, followed by a final prediction layer to generate keypoint heatmaps.
- Simple Decoder: Upsamples features using bilinear interpolation, applies a ReLU activation, and uses a final convolution to generate heatmaps. Despite being simpler, it delivers competitive performance.
Why ViTPose Works So Well
ViTPose’s effectiveness stems from a well-balanced combination of design decisions and practical training techniques. Here are the key reasons why it performs so impressively:
- Flexible Training Paradigms: ViTPose is versatile when it comes to training. It can be pre-trained on standard datasets like ImageNet, or even just on pose datasets using self-supervised learning. This makes it highly adaptable and data-efficient.
- Scalability Without Complexity: By simply adjusting the number of layers or the size of the transformer model (e.g., from ViT-B to ViT-H), ViTPose can scale from a compact, fast model to a state-of-the-art, high-accuracy system. No redesign of the architecture is needed.
- Transferable Knowledge: With the introduction of knowledge tokens, ViTPose allows knowledge transfer from large models to smaller ones efficiently. This makes it easier to deploy high-performing models in resource-constrained environments.
- Efficient Attention Mechanisms: Through smart use of attention techniques like shifted windows and pooled context, ViTPose minimizes memory usage while maintaining accuracy. This ensures scalability even at high resolutions.
Performance & Scalability
ViTPose can be scaled from lightweight models to billion-parameter giants.
| Model | Params | FPS | COCO AP |
| ViTPose-B | 86M | 944 | 75.8 |
| ViTPose-L | 307M | 411 | 78.3 |
| ViTPose-H | 632M | 241 | 79.1 |
| ViTPose-G | 1B+ | — | 80.9 |
Multi-Dataset Training: Training ViTPose jointly on multiple datasets improves its generalization and accuracy.
| Datasets Used | AP |
| COCO Only | 75.8 |
| COCO + AIC | 77.0 |
| COCO + AIC + MPII | 77.1 |
Knowledge Transfer with Tokens
ViTPose introduces an elegant technique to transfer knowledge from a large (teacher) model to a smaller (student) model using a knowledge token. Here’s how it works:
- A learnable token is added to the input of the teacher model.
- The token learns to represent the essential knowledge during training.
- This trained token is then used as part of the student model’s input.
This helps the student model perform better without needing to train a large model from scratch.
Flexibility in Training and Inference
Input Resolutions: Higher input image resolutions consistently improve ViTPose’s performance:
| Input Size | AP |
| 224×224 | 74.9 |
| 384×288 | 76.9 |
| 576×432 | 77.8 |
Attention Strategies: Different attention strategies help balance performance and computational cost. Using a combination of localized (window) attention and techniques like shifted windows or pooled tokens leads to strong results with lower memory usage.
| Attention | AP | Memory (MB) |
| Full | 77.4 | 36,141 |
| Window | 66.4 | 21,161 |
| Shift+Pool | 77.1 | 26,778 |
Real-World Results
- MS COCO Test-dev: 80.9 AP (ViTPose-G)
- OCHuman (occlusion): 93.3 AP
- MPII (PCKh): 94.3
- AI Challenger: 43.2 AP

ViTPose not only excels on standard benchmarks but also performs well in challenging conditions like occlusion, blur, and irregular poses.
Why ViTPose is a Big Deal
- Simple: No bells and whistles. Plain ViT + lightweight decoder.
- Scalable: Works from 86M to over 1B parameters.
- Flexible: Easily adapts to new data and different resolutions.
- Transferable: Efficiently trains smaller models using large-model knowledge.
ViTPose proves that simplicity can still deliver state-of-the-art performance. Its modularity and scalability make it suitable for both academic research and real-world deployment.




