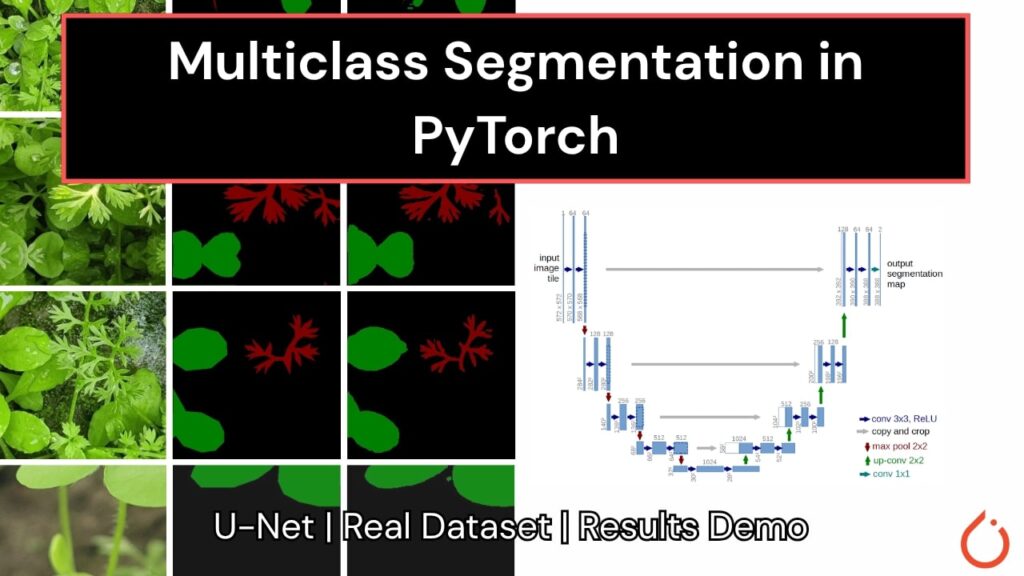
Semantic segmentation is a crucial task in computer vision that involves labeling each pixel in an image with its corresponding class. In this blog post, we’ll dive into building a multiclass semantic segmentation pipeline using the U-Net architecture with PyTorch. Our goal is to segment different types of weeds from Continue Reading
deep learning
ViTPose: Human Pose Estimation with (ViT) Vision Transformers
Human pose estimation is one of the most critical tasks in computer vision. It aims to localize anatomical key points (like shoulders, knees, and wrists) on the human body. Traditional convolutional neural networks (CNNs) have long dominated this field, but a new horizon has emerged with the advent of transformers Continue Reading
GradCAM with TensorFlow: Interpreting Neural Networks with Class Activation Maps

Deep learning models, particularly convolutional neural networks (CNNs), are widely used for image classification, object detection, and various computer vision tasks. However, these models are often referred to as “black boxes” due to their complex decision-making processes. To interpret these decisions and understand what parts of an image influence the Continue Reading
[Paper Summary] EMCAD: Efficient Multi-scale Convolutional Attention Decoding for Medical Image Segmentation
![[Paper Summary] EMCAD: Efficient Multi-scale Convolutional Attention Decoding for Medical Image Segmentation](https://idiotdeveloper.com/wp-content/uploads/2024/09/Paper-Summary-EMCAD-Efficient-Multi-scale-Convolutional-Attention-Decoding-for-Medical-Image-Segmentation-1024x536.jpg)
This post will analyze the research paper “EMCAD: Efficient Multi-scale Convolutional Attention Decoding for Medical Image Segmentation.” We will discuss the problems with existing medical image segmentation methods and how the given method (EMCAD) solves these issues. What is EMCAD? EMCAD is a newly developed efficient multi-scale convolutional attention decoder Continue Reading
What is Image Captioning?

In recent years, the field of artificial intelligence (AI) has seen remarkable advancements, particularly in how machines can understand and describe visual content. One of the fascinating developments in this area is image captioning, where AI models are trained to generate descriptive captions for images. This technology, often referred to Continue Reading
What is Dice Coefficient?

This article will explore the Dice Coefficient (DSC), a metric commonly used to evaluate the similarity between two sets. We’ll delve into its definition, provide implementations in NumPy, TensorFlow, and PyTorch, and discuss its practical applications. By the end of this guide, you’ll have a solid understanding of the Dice Continue Reading
Generative and Discriminative Models in Machine Learning

Machine learning is a fascinating field that teaches computers to make decisions or predictions based on data. Two main types of models are commonly used: generative models and discriminative models. These models have different approaches to learning from data, and understanding them can help you choose the right one for Continue Reading
ResUNet++ Implementation in TensorFlow
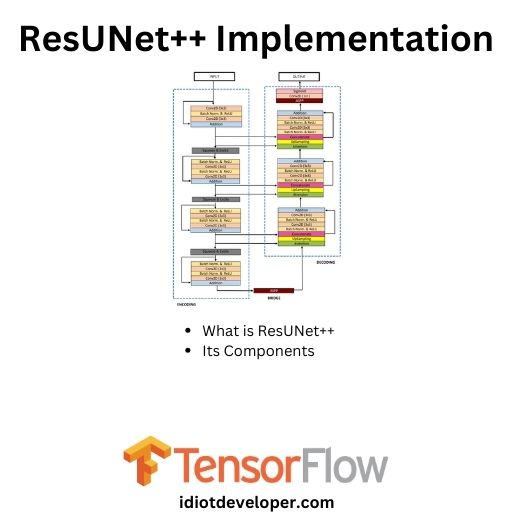
In this article, we will study the ResUNet++ architecture and implement it using the TensorFlow framework. ResUNet++ is a medical image segmentation architecture built upon the ResUNet architecture. It takes advantage of Residual Networks, Squeeze and Excitation blocks, Atrous Spatial Pyramidal Pooling (ASPP), and attention blocks. What is ResUNet++? Debesh Continue Reading
UNet 3+ Implementation in TensorFlow

In this article, we will implement the UNet 3+ architecture using TensorFlow. UNet 3+ extends the classic UNet and UNet++ architecture incorporating full skip connections. We will delve into each block of the UNet 3+ architecture, explaining how they work and how they contribute to improving the model’s performance. Understanding these Continue Reading
Skip Connection in Image Segmentation: UNet, UNet++ and UNet 3+

Image segmentation, a fundamental task in computer vision, involves partitioning an image into multiple segments to simplify its representation. One of the critical advancements in image segmentation architectures is the integration of skip connections, which have revolutionized the field by improving the accuracy and efficiency of segmentation models. What are Continue Reading