
We are going to continue our journey on the autoencoders. In this article, we are going to build a convolutional autoencoder using the convolutional neural network (CNN) in TensorFlow 2.0.
Let us first revise, what are autoencoders?
Autoencoders are neural networks that attempt to mimic its input as closely as possible to its output. It aims to take an input, transform it into a reduced representation called code or embedding. Then, this code or embedding is transformed back into the original input. The code is also called the latent-space representation.
For more: Introduction to Autoencoders
In this article, we are going to explore the following topics:
- What is Convolutional Neural Network?
- What is a Convolutional Autoencoder?
- The Architecture of Convolutional Autoencoder
- Implementation
What is Convolutional Neural Network
A convolutional neural network (CNN) consists of the following layers:
- Convolutional layer
- Activation layer
- Pooling layer
- Upsampling layer
A convolutional neural network uses these layers to extract features from the 2D data structure of images (or 2D input such as a speech signal) and then followed by the sub-sampling or pooling layer. Now we can add a dense or feedforward layer to the convolutional neural network for classification, or we can add an upsampling layer to increase the resolution of the feature maps for image generation tasks like semantic segmentation, image-to-image translation, etc.
For more:
Let us discuss each of the layers used in convolutional neural networks in detail.
Convolutional Layer
The convolutional layer is the main building block of the convolutional neural network (CNN). The layer consists of trainable filters or kernels which operate on the input to generate the output feature maps.

The kernel is generally a 3×3 shape of a matrix of a fixed size that slides over the input image computing the dot product which is then summed together in a single value. Like this, the feature maps for the next layer are computed by the convolutional layer.
While programming the input (number of images) x (image height) x ( image width) x (image depth) is given to the convolutional layer and the output the (number of images) x (image height) x ( image width) x (number of feature channels).
Activation Layer
Activation layers are an essential part of the deep neural network. As they consist of activation functions, which introduces non-linearity into the deep neural network. Without this non-linearity, the deep neural networks are only able to perform the linear mapping between inputs and the outputs.
This non-linearity helps the deep neural network to learn the complex mapping between the inputs and the outputs of the dataset. Due to this deep neural network can solve such complicated tasks like speech recognition, language translation, etc.
There are many different activation functions used in the deep neural network, which are:
- Linear
- Sigmoid
- Tanh
- ReLU
- Softmax
and many others.
Pooling Layer
The pooling or the subsampling layer is used to reduce the spatial dimensions of the feature maps, i.e., from (256 × 256) to (128 × 128).
There are two main types of pooling layers:
- Max pooling layer
- Average pooling layer

In max pooling function, the maximum value is chosen from the selected patch of the feature maps.
In case of average pooling, the average value is taken from the selected patch of feature maps.
UpSampling Layer
The upsampling layer performs the reverse of the pooling layer. It is used to increase the dimensions of the incoming feature maps, i.e., from (128 ×128) to (256 × 256).
The upsampling layer is generally used in generative tasks i.e., generating an image or other data. For example semantic segmentation, text to image generation, etc.
What is a Convolutional Autoencoder
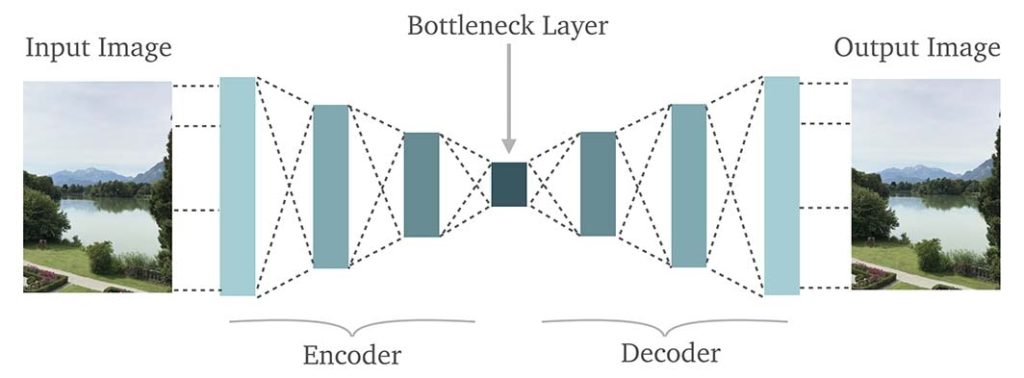
An autoencoder that uses convolutional neural networks (CNN) to reproduce its input in the output layer. Convolutional autoencoders are best suited for the images as it uses a convolution layer. These convolutional layers are best for extracting features from the images or other 2D data without modifying (reshaping) their structure.
The Architecture of Convolutional Autoencoder
An autoencoder consists of two parts: encoder and decoder.
The encoder has used the convolutional layer, batch normalization layer, an activation function and at last, a max-pooling function which reduces the dimensions of the feature maps.
After a specific number of layers, when the encoder is complete the feature maps are flattened and a dense layer is used for the latent-space representation.
Now, the transpose convolution is used for the upsampling of the incoming feature maps, which is followed by the batch normalization and the activation function.
Implementation
The convolutional autoencoder is implemented in Python3.8 using the TensorFlow 2.2 library.
First we are going to import all the library and functions that is required in building convolutional autoencoder.
import os
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "2"
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Conv2D, Activation, MaxPool2D
from tensorflow.keras.layers import BatchNormalization, Flatten, Reshape, Conv2DTranspose, LeakyReLU
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam, SGDLet us seed the environment and load the Fashion MNIST dataset.
## Seeding
np.random.seed(42)
tf.random.set_seed(42)
## Loading the dataset and then normalizing the images.
dataset = tf.keras.datasets.fashion_mnist
(x_train, y_train),(x_test, y_test) = dataset.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0Now we specify the hyperparameters.
## Hyperparameters
H = 28
W = 28
C = 1
## Latent space
latent_dim = 128Now we will build the model for the convolutional autoencoder. the inputs variable defined the input for the model which takes the input image while training.
inputs = Input(shape=(H, W, C), name="inputs")
x = inputsThe layers specified below forms the encoder for the convolutional autoencoder. The Conv2D layer learn the required features from the incoming image or feature maps.
x = Conv2D(32, (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
x = MaxPool2D((2, 2))(x)
x = Conv2D(64, (3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
x = MaxPool2D((2, 2))(x)x = Flatten()(x)
units = x.shape[1]
x = Dense(latent_dim, name="latent")(x)
x = Dense(units)(x)
x = LeakyReLU(alpha=0.2)(x)
x = Reshape((7, 7, 64))(x)The layer specified below forms the decoder for the convolutional autoencder. The decoder is a mirror image of the encoder, except instead of using Conv2D layer, the Conv2DTranspose (Transpose Convolution) is used. The transpose convolution is used learns to increase the dimensions of the incoming feature maps.
At the last a sigmoid activation is used because we want the output value between 0 and 1.
x = Conv2DTranspose(64, (3, 3), strides=2, padding="same")(x)
x = BatchNormalization()(x)
x = LeakyReLU(alpha=0.2)(x)
x = Conv2DTranspose(1, (3, 3), strides=2, padding="same")(x)
x = BatchNormalization()(x)
x = Activation("sigmoid", name="outputs")(x)
outputs = xThe convolutional autoencoder is now complete and we are ready to build the model using all the layers specified above.
autoencoder = Model(inputs, outputs)
autoencoder.compile(optimizer=Adam(1e-3), loss='binary_crossentropy')
autoencoder.summary()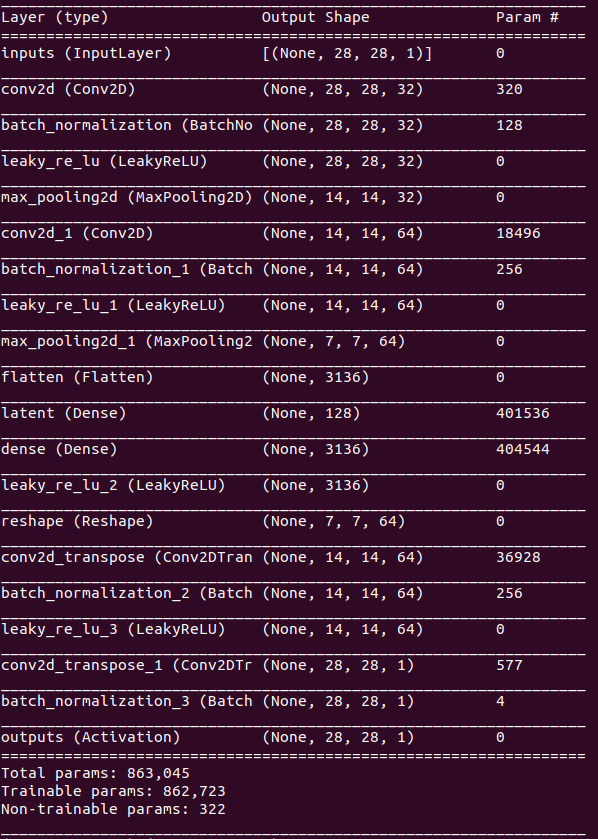
Now we start training the convolutional autoencoder using the Fashion MNIST dataset.
autoencoder.fit(
x_train,
x_train,
epochs=20,
batch_size=256,
shuffle=False,
validation_data=(x_test, x_test)
)After the training is complete, we can make predictions on the test dataset.
test_pred_y = autoencoder.predict(x_test)After the output is generated on the test images, we will save some of the test images and its output for the comparison.
n = 10 ## how many digits we will display
plt.figure(figsize=(20, 4))
for i in range(n):
## display original
ax = plt.subplot(2, n, i + 1)
ax.set_title("Original Image")
plt.imshow(x_test[i].reshape(H, W))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
## display reconstruction
ax = plt.subplot(2, n, i + 1 + n)
ax.set_title("Predicted Image")
plt.imshow(test_pred_y[i].reshape(H, W))
plt.gray()
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.savefig("results/convolutonal_autoencoder.png")




