The research lab OpenAI has released a preprint arXiv paper, titled “Language Models are Few-Shot Learners” or OpenAI GPT-3, which is a continuation of their previous work entitled “Language Models are Unsupervised Multitask Learners” or GPT-2.
As a recap. GPT-2 is a language model based on the transformer architecture with 1.5 billion parameters. It was trained to predict the next word in a collection of 40GB of text.
What is OpenAI GPT-3
As stated in the paper,
GPT-3, an autoregressive language model with 175 billion parameters, 10x more than any previous non-sparse language model, and tests its performance in the few-shot setting.
In simpler words, we can say that GPT-3 is a transformer-based language model trained with unsupervised machine learning. In particular, it focuses on few-shot learning which is useful for many downstream NLP tasks.
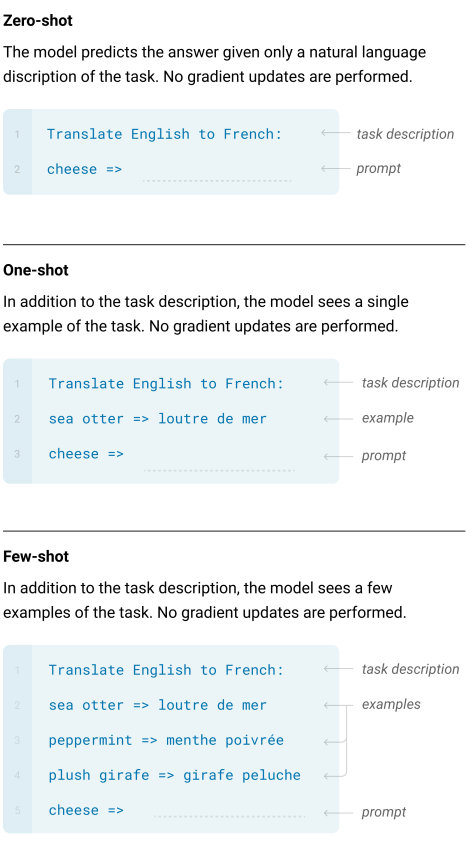
The GPT-3 is evaluated on three conditions:
- Few-shot learning
- One-shot learning
- Zero-shot learning
The model isn’t evaluated on the popular fine-tuning method.
Models and Architecture of OpenAI GPT-3
The GPT-3 used the same model and architecture as used in GPT-2, including the modified initialization, pre-normalization, and reversible tokenization. A few modifications are made by using alternating dense and locally banded sparse attention patterns in the layers of the transformer, similar to the Sparse Transformer.
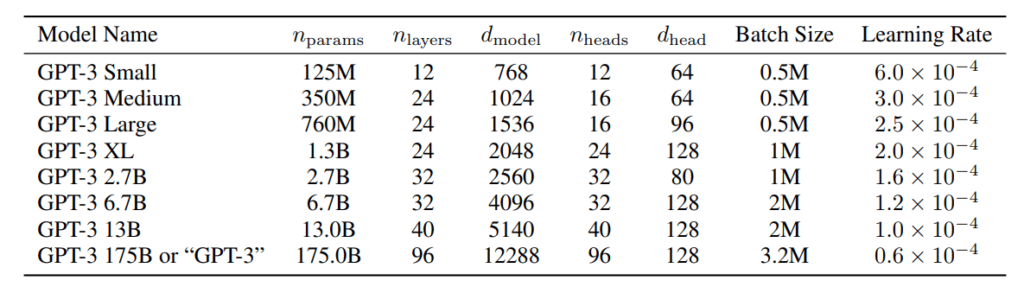
which we trained. All models were trained for a total of 300 billion tokens.
The researchers trained 8 different size models ranging from 125 million parameters to 175 billion parameters.
Training Dataset used in OpenAI GPT-3
To train the OpenAI GPT-3, the following datasets are used.
- Common Crawl (filtered)
- WebText2
- Book1
- Book2
- Wikipedia
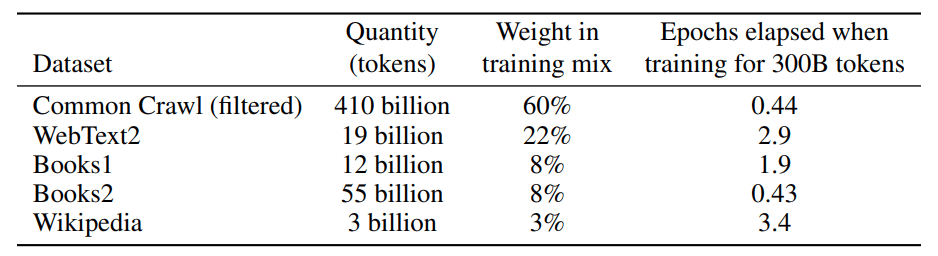
The Common Crawl dataset is not used directly. It is first filtered to make sure that it only has high-quality data. We then use an expanded version of WebText, which is collected by scraping links over a longer period. Finally, two internet books (Book1 and Book2)and English-language Wikipedia data are included in the training dataset.
Evaluation and Results
The OpenAI GPT-3 is evaluated over two dozens of NLP datasets and several novel tasks designed to test model adaptation to tasks that are not included in the training dataset.
The GPT-3 is evaluated on the following tasks:
- Language modelling tasks: Cloze tasks and sentence/paragraph completion tasks
- Close book question answering task: Answering the general knowledge question using the information stored in the model parameters.
- Language Translation
- Winograd Schema-like tasks
- Commonsense reasoning or question answering
- Comprehension reading tasks
- SuperGLUE benchmark suite
- Natural Language Inference (NLI) tasks.
- Additional tasks: Tasks that test the reasoning, adaptation skills, or open-ended text synthesis.
Some of the state-of-the-art results achieved by GPT-3 are on the following tasks:
- Cloze tasks and sentence/paragraph completion tasks.
- Commonsense reasoning on PIQA dataset.
Limitations
Despite having good improvements GPT-3 is still having some limitations.
- GPT-3 sometimes repeats the text during text synthesis at the document level.
- As the model has huge parameters, so it is not easy to fine-tune.
- Another limitation broadly shared by language models is poor sample efficiency during pre-training.
- Due to its large size and a huge number of parameters, it is expensive and inconvenient during the inference.
Conclusion
The present study demonstrates that with a very large scale language model like GPT-3, we can get more acceptable and general language models. It is also an important step towards the zero-shot, one-shot and few-shot learning, which are crucial for some downstream NLP tasks due availability of the labelled dataset.
The paper is on arXiv, and the project is available on the GitHub.