Deep neural networks have become popular due to their high performance in real-world applications, such as image classification, speech recognition, machine translation and many more. Over time deep neural networks are becoming deeper and deeper to solve more complex tasks. Adding more layers to a deep neural network can improve its performance, but up to a certain point. After that, it becomes difficult to train the network and the performance starts to decrease. In order to solve these challenges, researchers introduce the residual network.
In this article, we will learn more about the residual network and how they work and help to solve the above challenges.
Table of contents:
- What is Residual Network
- Why do we need a Residual Network?
- What is Residual Block?
- How Residual Block Helps
- ResNet Architectures
- Summary
- Read More
What is Residual Network?
Residual network or ResNet in short was introduced in 2015 by Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun in their paper “Deep Residual Learning for Image Recognition”.
The success of these ResNet models can be seen from the following:
- ResNet model won 1st place in the ILSVRC 2015 classification competition with a top-5 error rate of 3.57%.
- The network got 1st place in multiple ILSVRC and COCO 2015 competitions. These competitions include:
- ImageNet Detection and Localization,
- COCO Detection and Segmentation.
- An improvement of 28% was observed by replacing the VGG-16 layers in Faster R-CNN with ResNet-101.
Why do we need a Residual Network?
We know that neural networks are universal function approximators, they can learn to map the input X to an output Y, when given a good dataset. The performance of a neural network increases with the increase in the number of layers. The reason behind adding more layers is that these layers would learn more complex features. The initial layers would learn to detect lines, edges, etc, and the subsequent layers at the end may detect recognizable objects such as a dog or a cat.
There is a limit to add the number of layers to a neural network. After that threshold is reached, the accuracy of the model starts to saturate and then degrade. This is due to the vanishing/exploding gradients, which causes the gradient to become 0 or too large. Thus when we increase the number of layers, the training and test error rate also increases.
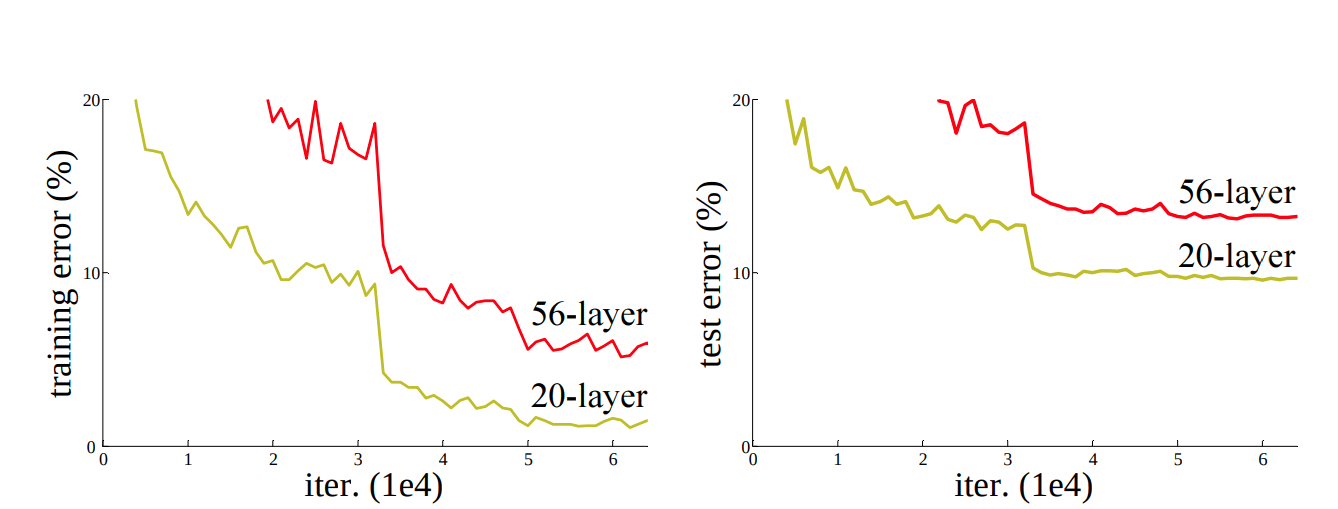
From the above graph, we can say that a shallow network performs better than a deeper network. We can see that the error rate of the 20-layer network is less than the 56-layer network in both the training and testing.
You might also think that the 56-layer model is overfitting. In the case of overfitting, the training performance of a model increases drastically and the testing performance drops significantly. Here, the performance of the 56-layer network is worse in both the training and the testing.
Due to the depth of the network and the curse of dimensionality the network cannot be trained properly. So, the shallow (20-layer) network performs better than the deeper (56-layer) network.
What is Residual Block?
The residual network consists of the residual units or blocks as the main component of the network. Before going deeper into the details, here is the diagram of the residual block.
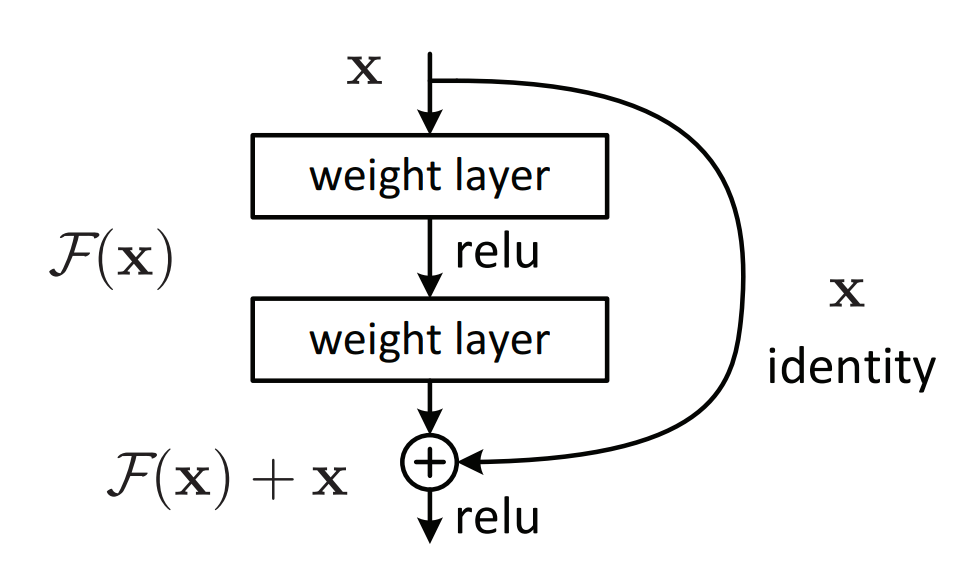
In previous approaches, each layer feed to its next layer and the same goes on subsequently. In a residual network, each layer feeds to its next layer and directly to the 2-3 layers below it.
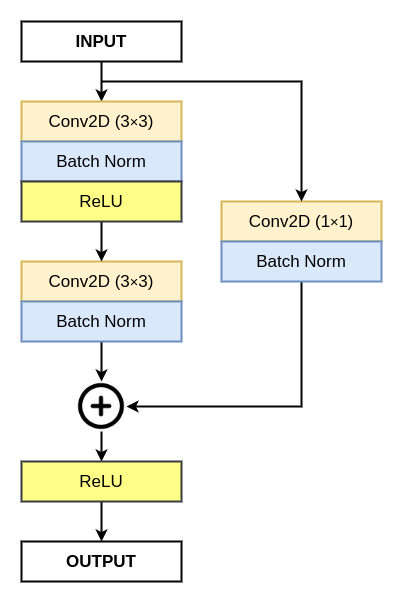
The residual block consists of two 3×3 convolution layers and an identity mapping also called a shortcut connection. Each, convolution layer is followed by a batch normalization layer and a ReLU (Rectified Linear Unit) activation function. An element-wise addition is performed between the identity mapping with the output of the last batch normalization.
For the element-wise addition of two features, the number of output channels (feature channels) should be the same. In case, where the number of output channels is not the same, we perform a 1×1 convolution and batch normalization on the identity mapping.
How Residual Block Helps
The residual block helps the researchers to build and train a deeper network without the problem of vanishing/exploding gradients. The identity mapping or the shortcut connection present in the residual block helps in the following ways:
- It provides an alternative path for the better flow of gradients during the backpropagation. It helps the earlier layers to learn better, which helps to improve the performance of the network.
- The identity mapping learns an identity function that ensures that the residual block performs as good as the lower layer.
In case the layers in the normal flow do not learn anything, then the identity mapping basically copies the information from the earlier layers. This helps the neural network to perform better even with the deeper architecture.
Using the residual network or ResNet can drastically improve the performance of neural networks despite having more layers.
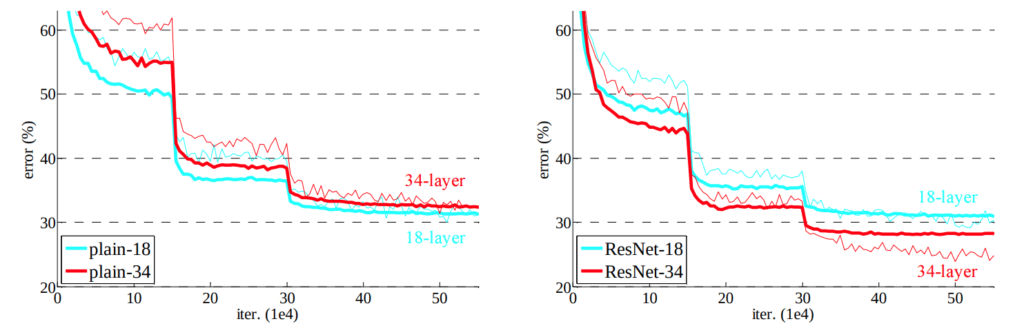
The graph above clearly shows that the ResNet-34 has a much lower error rate as compared to plain-34. Also, we can see the error rate for plain-18 and ResNet-18 is almost the same.
| LAYERS | PLAIN | RESNET |
|---|---|---|
| 18 | 27.94 | 27.88 |
| 34 | 28.54 | 25.03 |
ResNet Architectures
There are a number of ResNet architectures that are built with a different number of layers in the network. The networks are:
- ResNet18
- ResNet34
- ResNet50
- ResNet101
- ResNet152
The residual network uses a 34-layer plain network architecture inspired by VGG-19 in which then the shortcut connections are added and thus forming a residual network with 34-layers as shown in the figure below:
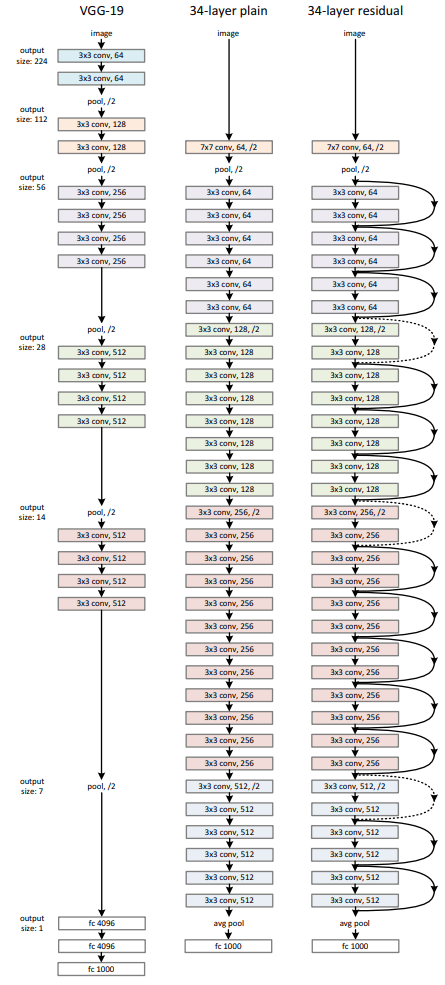
Summary
In this article, you learn about the Residual Network and the following things about it.
- What is the problem with the existing neural network and how residual network solved them?
- What is a residual block and how it works?
- How the residual block helps.
Still, have some questions or queries? Just comment below. For more updates. Follow me.




