In this article, we are going to explore the two machine learning approaches – supervised and unsupervised learning. It is one of the most basic questions for data science beginners. Without a basic understanding of supervised and unsupervised learning, you cannot make any progress in the field of data science. So, let’s start and learn more about these two approaches.
The basic difference between the two approaches is supervised learning uses labelled datasets while the other technique uses an unlabelled dataset.
Table of Contents
- What is supervised learning?
- What is unsupervised learning?
- Summary
What is Supervised Learning?
Supervised learning is a machine learning technique that uses well-defined labelled datasets. In this technique, the model takes the inputs and learn to predict the correct outcomes. With these outcomes, we can measure the performance of the model and see how well our model is performing over time.

Supervised learning can be classified into two different types:
- Classification algorithms are used to caterorize an input into specific categories, such as classifiying a cat or a dog. In real world, supervised learning algorithms are used for sentiment analysis, span email classification, etc.
- Regression algorithms are used to understand the relationship between dependent and independent variables. These algorithms are useful for predicting numerical values, such as annual income based on the current business performance.
What is Unsupervised Learning?
Unsupervised learning is another machine learning technique where unlabelled datasets are used. The unsupervised algorithms are used to discover the hidden patterns inside the unlabelled datasets.
Unsupervised learning helps you to perform the following tasks:
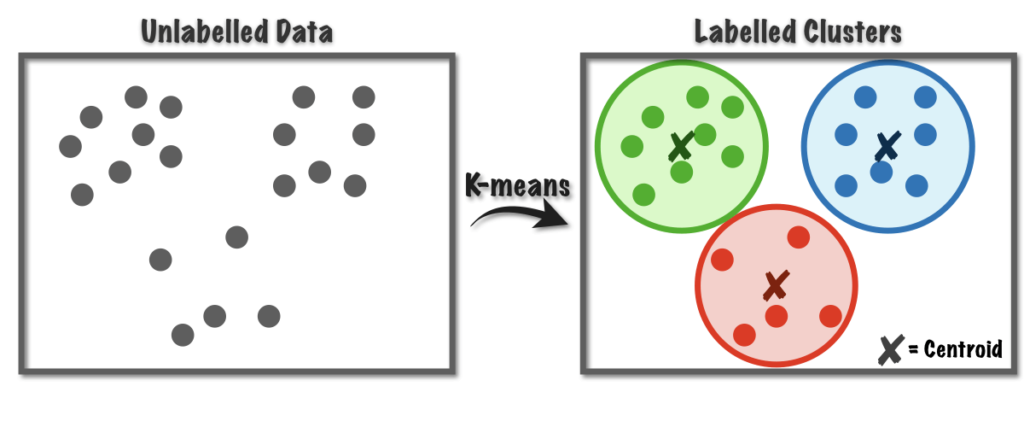
- Clustering algorithms are used to discover the similarities and differences between different data points. On the basis of these similarities and differences multiple groups are formed consisting of different data points.
- Assocication algorithms are used to find the rules or relation between different variables. For example, clothes sales based on the types of season.
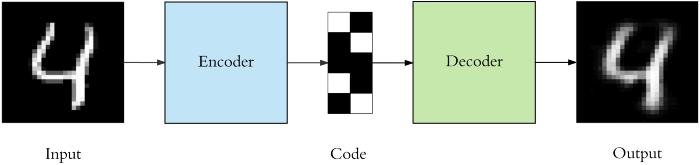
- Dimensionality reduction is another technique where the number of features are reduced to a manageable size while preserving the important features. For example, autoencoders are used to reduce the input features to a small number of features, which are further used to generate the original input.
Summary
In this article, you have learned the following:
- What is supervised learning?
- What is unsupervised learning?
Still, have some questions or queries? Just comment below. For more updates. Follow me.