
Convolutional Neural Network (CNN) has been most widely used in the field of computer vision and visual perception to solve multiple tasks such as image classification, semantic segmentation and many more. However, there is a need for approaches that can further improve its performance. One such approach is to add some attention mechanism to an already existing CNN architecture for further improvements. Squeeze and Excitation Network (SENet) is one such attention mechanism that is most widely used for performance improvements.
In the article, we are going to learn more about the Squeeze and Excitation Networks, how they work and how they help to improve performance.
Table of Contents:
- What is Squeeze and Excitation Network?
- The intuition behind Squeeze-and-Excitation Network.
- The architecture of Squeeze-and-Excitation Networks.
- Squeeze
- Excitation
- Scaling
- How Squeeze-and-Excitation Networks Help?
- Summary
- Read More
What is Squeeze and Excitation Network?
The squeeze and excitation attention mechanism was introduced in the year 2018 by Hu et al. in their paper “Squeeze-and-Excitation Networks” at CVPR 2018 with a journal version in TPAMI. It is one of the most dominant paper in the field of attention mechanism and was cited more than 8000 times.
Squeeze and Excitation Network is a channel-wise attention mechanism that recalibrates each channel accordingly to create a more robust representation by enhancing the important features.
The Squeeze and Excitation Network basically introduces a novel channel-wise attention mechanism for CNNs (Convolutional Neural Network) to improve their channel interdependencies. The network adds a parameter that re-weights each channel accordingly so that it becomes more sensitive towards significant features while ignoring the irrelevant features.
The Squeeze and Excitation Network was used in the ILSVRC 2017 classification submission and won first place and reduced the top-5 error to 2.251%, surpassing the winning entry of 2016 by a relative improvement of ∼25%.
The intuition behind Squeeze and Excitation Networks
The Convolutional Neural Network (CNN) used the convolution operator to extract hierarchical information from the images. The lower layer detects lines, edges, etc., while the upper layers detect complete objects like a human face, cat or dog. All these works by fusing the spatial and channel-wise information at each layer.
The convolution operator generates a feature map with the different number of channels, where it treats all the channels equally. It means that every single channel is equally important and this may not be the best way. The Squeeze and Excitation attention mechanism adds a parameter to each channel that rescales them independently.
The Squeeze and Excitation basically act as a content-aware mechanism that re-weights each channel adaptively.
The architecture of Squeeze and Excitation Networks
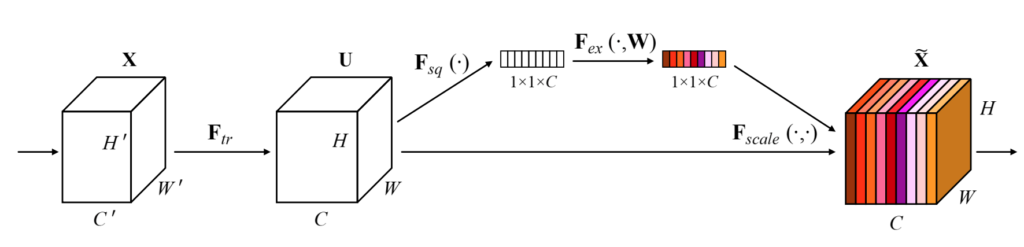
The author proposes an easy-use module called Squeeze and Excitation block also called SE-block. The SE-block consists of three operations:
- Squeeze
- Excitation
- Scaling
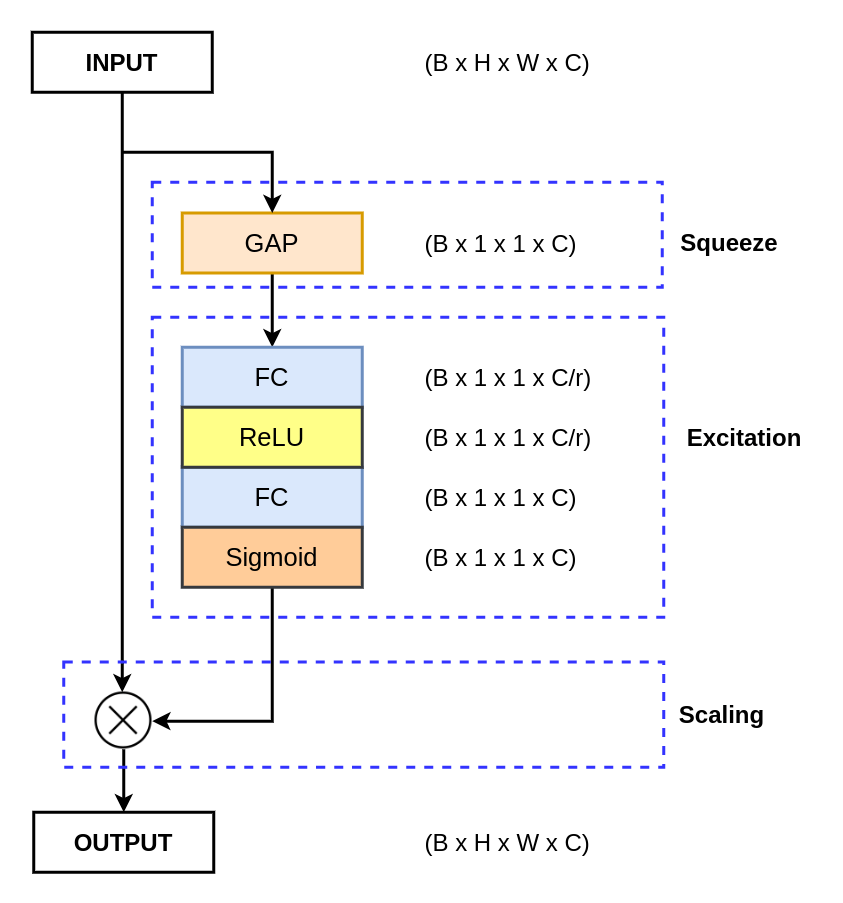
Squeeze
The squeeze operation is mainly used to extract the global information from each channel of the feature map. The feature map is basically the output of the convolution layer, which is a 4D tensor of size B x H x W x C. Here:
- B: refers to batch size.
- H: refers to the height of each feature map.
- W: refers to the width of each feature map.
- C: refers to the number of channels in the feature map.
As we know that the convolution is a local operation, as it gets to see a smaller part from the complete input image. So, it is essential to get a global understanding of the feature map.
As we are dealing with a 4D tensor, which consists of a lot of parameters. This would essentially mean that we need to deal with a large number of parameters as the number of channels increases drastically in a modern convolution neural network. So, we need a method to decompose each feature channel into a single numeric value. This decomposition would decrease the number of parameters and thus reducing the computational complexity.
In modern convolutional neural networks, pooling operations are used to reduce the spatial dimensions of the feature maps. The two widely used pooling operations are:
- Max Pooling: operation is used to take the maximum pixel value from a defined window.
- Average Pooling: operation is used to computes the average pixel values from a defined window.
The author performs a set of experiments to investigate the performance of each pooling operation, which are Global Max Pooling (GMP) and Global Average Pooling (GAP).
| Pooling | Top-1 Error Rate | Top-5 Error Rate |
|---|---|---|
| Max | 22.57 | 6.09 |
| Average | 22.28 | 6.03 |
From the above table, it is clear that the Global Average Pooling (GAP) performs better than the Global Max Pooling (GMP). Thus in the squeeze operation, the Global Average Pooling (GAP) is used to reduce the B x H x W x C feature map to B x 1 x 1 x C.
Excitation
The feature map is now reduced to a smaller dimension (B x 1 x 1 x C), basically for each channel of size H x W is reduced to a singular vector. For the excitation operation, a fully connected Multi-Layer perceptron (MLP) with a bottleneck structure is used. The MLP is used to generate the weights to scale each channel of the feature map adaptively.
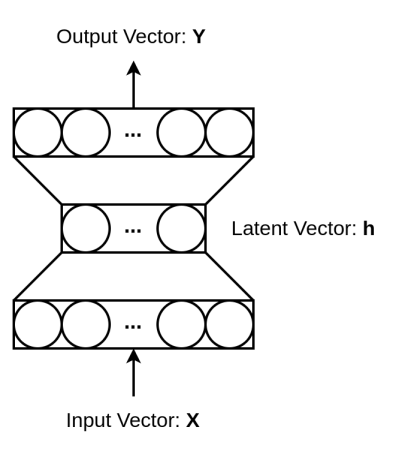
The MLP consists of three layers, where the hidden layer is used to reduce the number of features by a reduction factor r. The dimensions of the feature maps in the layers are:
- The input is of shape (B x 1 x 1 x C), which is reduced to B x C. Thus the input layer has the C number of neurons.
- The hidden layer reduces the number of neurons by a factor of r. Thus the hidden layer has a C/r number of neurons.
- Finally, In the output layer, the number of neurons increased back to C.
Overall, the MLP takes the input as B x 1 x 1 x C as return the output with the same dimensions.
Scaling
The excitation operation passes the “excited” tensor of shape B x 1 x 1 x C. This tensor is then passed through a sigmoid activation function. The sigmoid activation function converts the tensor values in the range of 0 and 1. We then perform an element-wise multiplication between the output of the sigmoid activation function and the input feature map.
If the value is close to 0 means the channel is less important so, the values of the feature channel would be reduced, and if the value is close to 1, this means that is channel is important.
To further investigate the scaling operation, the author has performed an ablation study by replacing sigmoid with other non-linear activation functions.
| Activation Function | Top-1 Error Rate | Top-5 Error Rate |
|---|---|---|
| ReLU | 23.47 | 6.98 |
| Tanh | 23.00 | 6.38 |
| Sigmoid | 22.28 | 6.03 |
From the above table, we can say that the sigmoid is the best non-linear activation function.
How Squeeze-and-Excitation Networks Help?
So, till now you have understood the architecture of the Squeeze and Excitation Network. During the scaling operation, we perform an element-wise multiplication between the initial feature map and the output of the sigmoid activation function.
The sigmoid activation function outputs a value between 0 and 1 and each channel is multiplied with it.
So, now imagine, a channel is multiplied with a value that is near 0. It will reduce the pixel values of that feature map, as these pixel values are not much relevant according to the SE-block.
When the channel is multiplied with a value that is near 1, it would not reduce the pixel values that much, if compared with the above case.
So, now we can see that the Squeeze and Excitation Network basically scale each channel information. It reduces the non-relevant channel information and the relevant channel are not much affected. So, after the whole operation, the feature map only contains the relevant information, which increases the representational power of the entire network.
Summary
In this article, you have learned about one of the most widely used channel-wise attention mechanisms known as “Squeeze and Excitation Network”.
You have learned the following things about it.
- What is Squeeze and Excitation Network?
- What is the intuition behind the SENet?
- The architectural structure of the SENet.
- How does it help?
Still, have some questions or queries? Just comment below. For more updates. Follow me.




