Machine learning is a fascinating field that teaches computers to make decisions or predictions based on data. Two main types of models are commonly used: generative models and discriminative models. These models have different approaches to learning from data, and understanding them can help you choose the right one for your project.
What Are Generative Models?
Think of generative models as artists. They don’t just learn how to recognize a pattern; they learn how to create it. Imagine you’re teaching a computer about different types of fruit. A generative model wouldn’t just learn to identify an apple; it would learn what makes an apple an apple—its color, shape, and size—and then be able to create a new apple that looks similar.
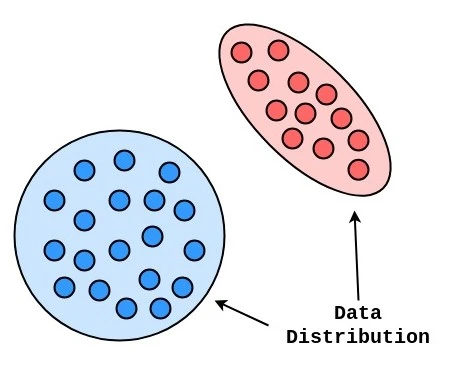
Data distribution refers to the way data points are spread out or arranged across the range of possible values in a dataset.
Generative models work by understanding the entire data set, including how the data points relate to each other. Technically, they learn the joint probability distribution of the data and its labels. This means the model knows how the features (color and size) and labels (like apple or banana) are connected. Once trained, these models can generate new data points that follow the same rules as the original data.
In short, generative models:
- Maximize the joint probability: P(X, Y)
- Learn class-conditional distribution: P(X | Y)
Examples of Generative Models
- Naive Bayes: This model assumes all features are independent and uses probability to classify data.
- Generative Adversarial Networks (GANs): These are popular for creating realistic images, music, and text.
Read More:
Generative models are great when you need to create new data similar to what you’ve already seen. They’re used in fields like image generation, speech synthesis, and more.
What Are Discriminative Models?
On the other hand, discriminative models are like detectives. They focus on finding the difference between things. If you’re teaching a computer about fruit, a discriminative model will focus on determining what makes an apple different from an orange. It doesn’t try to recreate the apple; it just wants to classify it correctly.
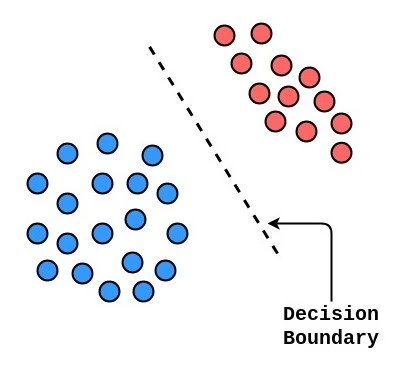
A decision boundary is a line or surface that separates different classes in a classification problem.
Discriminative models work by learning the conditional probability P(Y | X) between the data features and the labels. They don’t worry about how the data is generated. Instead, they focus on drawing boundaries between different classes based on their features. This approach makes them very effective for tasks like classification.
In short, discriminative models:
- Learn decision boundary.
- Maximize conditional probability: P(Y | X)
Examples of Discriminative Models
- Logistic Regression: A simple model that predicts the probability of a binary outcome, like whether an email is spam or not.
- Support Vector Machines (SVMs): These models create a boundary between classes, such as separating images of cats from dogs.
Read More:
- Dog Breed Classification using Transfer Learning in TensorFlow
- Mastering k-Nearest Neighbor Algorithm in R
Discriminative models are commonly used for tasks requiring you to categorize or label data, like identifying objects in images or classifying emails as spam.
When to Use Which?
- Generative Models: Use these when you need to generate new data, understand the underlying structure of your data, or perform tasks like image synthesis or anomaly detection.
- Discriminative Models: These are your go-to models when accuracy in classification tasks is crucial, like in image recognition or text classification.
Conclusion
Generative and discriminative models might approach learning differently, but both are powerful tools in the machine learning toolbox. Generative models are like creators, learning to reproduce and generate new data, while discriminative models are classifiers, focusing on distinguishing between different categories. By understanding these models, you can choose the right approach for your machine learning projects, whether you’re building a system to generate new data or one that classifies existing data.