PP-LiteSeg is a lightweight encoder-decoder architecture designed for real-time semantic segmentation.
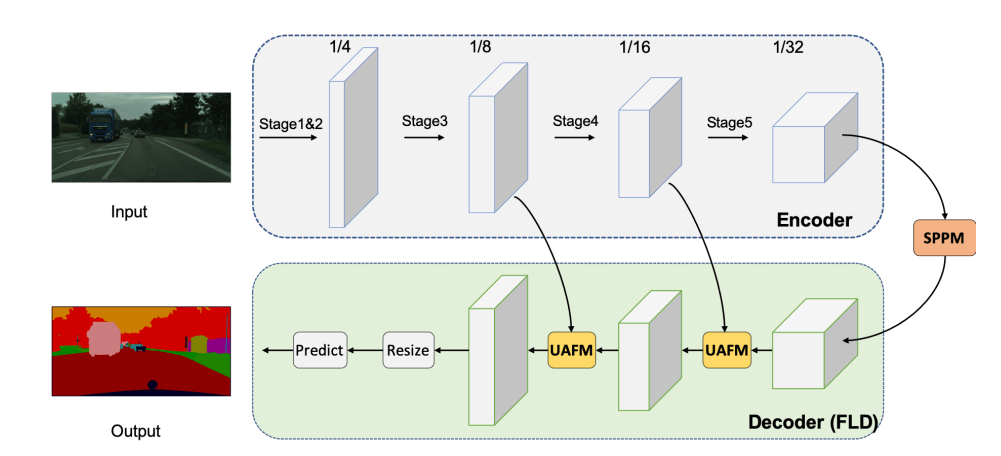
It consists of three modules:
- Encoder: Lightweight network
- Aggregation: Simple Pyramid Pooling Module (SPPM)
- Decoder: Flexible and Lightweight Decoder (FLD) and Unified Attention Fusion Module (UAFM)
Encoder
The STDCNet is the encoder for the proposed PP-LiteSeg for its high performance.
The research paper presents two versions of the PP-LiteSeg: PP-LiteSeg-T and PP-LiteSeg-B, where STDC1 and STDC2 are used as encoders respectively.
| Model | Encoder | Channels in Decoder |
|---|---|---|
| PP-LiteSeg-T | STDC1 | 32, 64, 128 |
| PP-LiteSeg-S | STDC2 | 64, 96, 128 |
Flexible Lightweight Decoder (FLD)
- FLD gradually decreases the channels of the features from high level to low level.
- FLD can easily adjust the computation cost to achieve a better balance between the encoder and the decoder.
- The FLD consists of a set of convolutional layers along with the Unified Attention Fusion Module (UAFM) to enrich the features by using channel and spatial attention.
Unified Attention Fusion Module (UAFM)
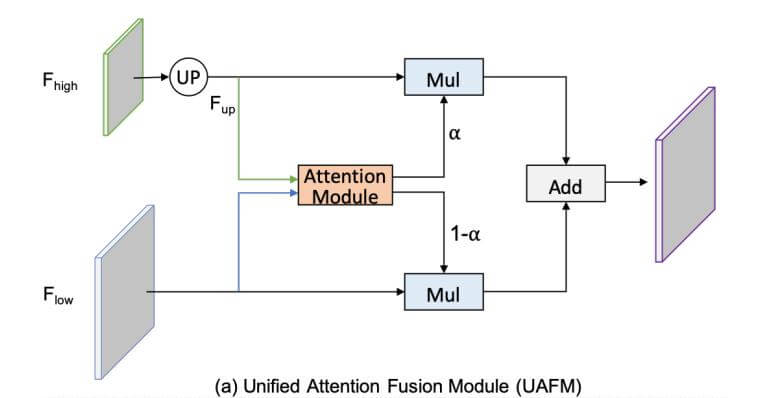
- UAFM applies channel and spatial attention to enrich the fused feature representations.
- The UAFM takes two sets of input feature maps: F_high and F_low. F_high is the feature map from the previous block and the F_low is the feature from the respective encoder block.
- The F_high feature map is first upsampled by using a bilinear interpolation. Next, both the F_high and F_low are passed through the Attention Module and produce the weight α.
- Next, we perform an element-wise multiplication of F_high and F_low with the weight α and 1-α respectively and then we perform an element-wise addition and give the output.
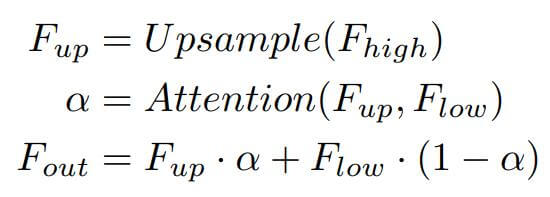
Spatial Attention Module (SAM)

The spatial attention module exploits the inter-spatial relationship from the input feature map and produces a spatial attention map. This spatial attention map highlights the region of interest in the input feature and supress the irrelevant.
Channel Attention Module (CAM)

The channel attention module exploits the inter-channel relationship from the input feature map and produces a vector representing the importance of each channel present in the input feature map.
Simple Pyramid Pooling Module (SPPM)

- SPPM connects the encoder and decoder of the PP-LiteSeg or it acts as a bridge between the encoder and the decoder.
- It begins with a global average pooling with three different bin sizes i.e., 1×1, 2×2, and 4×4.
- The three output features are followed by a sequence of 1×1 convolution, batch normalization and ReLU activation function.
- Next, all three features are upsampled and added together to produce a single fused feature map.
- Finally, it is then followed by 1×1 convolution, batch normalization and ReLU activation function.
Datasets and Implementation Details
- The model has trained two different datasets: Cityscapes and CamVid.
- Stochastic Gradient Descent (SGD) is used as an optimizer with a momentum of 0.9.
- The “poly” learning rate scheduler is used while training the PP-LiteSeg.
- For data augmentation, random scaling, random cropping, random horizontal flipping, random color jittering and normalization are used. The random scale ranges in [0.125, 1.5], [0.5, 2.5] for Cityscapes and Camvid respectively.
Results


Summary
In this paper, the authors focused on designing a semantic segmentation architecture for real-time performance. To achieve this the authors have developed novel modules such as Flexible and Lightweight Decoder (FLD) and Unified Attention Fusion Module (UASM) to strengthen the feature representations. Simple Pyramid Pooling Module (SPPM) is further used to aggregate global contextual information with low-overhead computation cost. By combining all these novel modules, the authors developed PP-LiteSeg, which has achieved top performance along with high FPS with high-resolution input.




