
In recent years, the field of artificial intelligence (AI) has seen remarkable advancements, particularly in how machines can understand and describe visual content. One of the fascinating developments in this area is image captioning, where AI models are trained to generate descriptive captions for images. This technology, often referred to as image to caption AI, has a wide range of applications, from helping the visually impaired to enhancing content creation.
Image Captioning
Image captioning is the process of generating textual descriptions for images. It combines computer vision and natural language processing (NLP) to produce captions that describe an image’s content, context, and details. The goal is to create a system that can look at an image and describe what it sees similarly to how a human would.

For example, given the above picture, an image captioning model might generate a caption like, “A dog playing with a ball in the park.”
How Image Captioning Works
The process of generating captions for images typically involves two key components:
- Image feature extraction
- Caption Generation
Image Feature Extraction
This stage employs a Convolutional Neural Network (CNN) to analyze the image and extract relevant features. CNNs are particularly effective at identifying patterns such as edges, textures, and shapes by processing the image through multiple layers of filters. These extracted features serve as a high-level representation of the image’s content, capturing essential visual information.
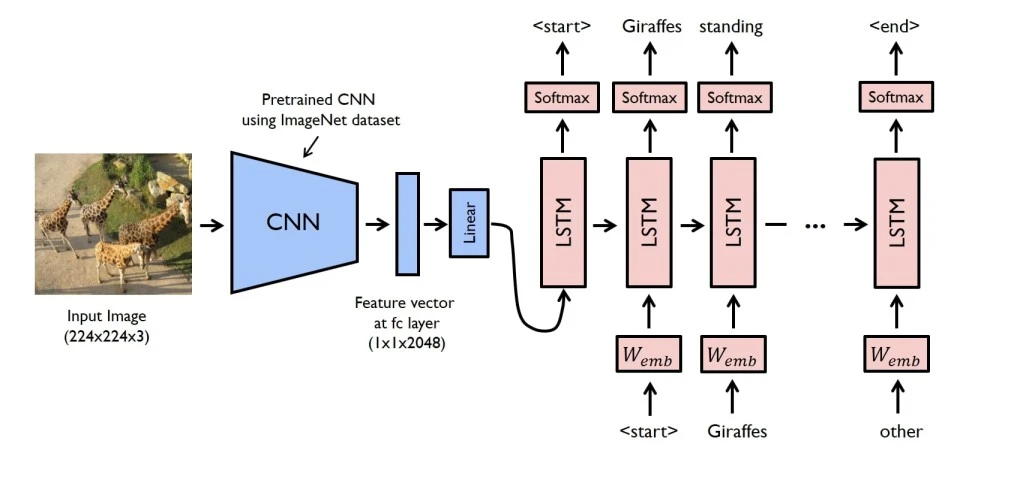
Caption Generation
Once the image features are extracted, they are fed into a language model that generates a corresponding textual description. Initially, Recurrent Neural Networks (RNNs), including Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) models, were used for this task due to their ability to handle sequential data.
However, RNNs are increasingly being replaced by Transformer models, which offer improved performance through parallel processing and self-attention mechanisms. Transformers can better capture complex relationships between words and image features, producing more accurate and contextually rich captions.
Architecture Explanation
RNN-Based Image Captioning
Before the introduction of Transformers, image captioning relied heavily on RNNs like LSTM and GRU. These models could generate sequential data, making them suitable for tasks like caption generation. The basic architecture involved a CNN to extract image features and an RNN to generate the corresponding text.
However, RNNs have some limitations:
- Sequential Processing: RNNs process data sequentially, which can be slow and less efficient for long sequences.
- Vanishing Gradient Problem: RNNs can struggle to retain information over long sequences, which can make generating accurate and contextually appropriate captions difficult.
Transformer-Based Image Captioning
The introduction of Transformers marked a significant improvement in image to caption AI. Transformers use self-attention mechanisms, allowing them to process all parts of the input simultaneously, rather than sequentially like RNNs. This parallel processing capability makes Transformers faster and more efficient.
Key advantages of Transformers include:
- Better Context Understanding: Transformers can capture long-range dependencies in the data, leading to more coherent and contextually accurate captions.
- Parallel Processing: Transformers process all words in a sentence simultaneously, making them faster and more efficient than RNNs.
- Scalability: Transformers can easily scale to handle larger datasets and more complex tasks, making them ideal for modern AI applications.
ALSO READ:
- Vision Transformer – An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
- What is Residual Network or ResNet?
Applications of Image Captioning
Image captioning has a wide range of applications in various fields:
Assisting the Visually Impaired
One of the most impactful applications of image to caption technology is aiding the visually impaired. By generating accurate descriptions of images, these systems can help visually impaired individuals understand visual content, such as photos, scenes, and even text within images.
Content Creation
In the media and advertising industries, image captioning can automate the generation of image descriptions. This helps efficiently manage large volumes of content, such as social media posts, product descriptions, and news articles.
Enhancing Search Engines
Search engines can use image to caption AI to improve their image search capabilities. By understanding an image’s content and generating relevant captions, search engines can provide more accurate search results.
Surveillance and Security
In security and surveillance, image captioning can automatically describe what happens in video feeds or images. This can assist security personnel in monitoring large areas more effectively.
Conclusion
Image captioning represents a significant advancement in AI, combining computer vision and natural language processing to create systems that can describe visual content in human-like ways. While early models relied on RNNs like LSTM and GRU, the introduction of Transformers has revolutionized the field, making these systems faster, more accurate, and more scalable. As image to caption AI continues to evolve, its applications will only expand, offering even more benefits across various industries.




