
In this blog post, we are going to learn about the Vision Transformer (ViT). It is a pure Transformer based architecture used for image classification tasks. Vision Transformer (ViT) has the ability to replace the standard CNNs while achieving excellent results. The Vision Transformer (ViT) attains excellent results when pre-trained on larger datasets and transferred to tasks with a smaller dataset, such as CIFAR 100, CIFAR10, etc.
The paper is published at ICLR 2021.
Research paper link: https://arxiv.org/pdf/2010.11929.pdf

The input image is first split into fixed-size patches, passes through some linear layers, then adds position embeddings and then fed into the Transformer Encoder. An extra learnable embedding/token ([class]) is added at the beginning for performing image classification.
Related
What is Vision Transformer (ViT)
Here, we will discuss the Vision Transformer (ViT) architecture in detail. The sequence is as follows:
- Input image Transformation.
- What is Class Token?
- Position Embeddings
- Transformer Encoder
Input Image Transformation
The first step is the transformation of a 2D image into a sequence of flattened patches.
Input Image (I) = H x W x C, would be transformed into Patches (P) = N x (P2 x C).
N = (H x W) / (P x P)
Here,
- H x W: refers to the height and width of the Input Image (I).
- C: refers to the number of channels in the Input Image (I)
- P2: refers to the height and width of an individual patch.
- N: refers to the number of patches.
The number of patches (N) serves as the effective input sequence length for the ViT. All the flattened patches are mapped into D dimensions by passing through some learnable linear layers. The output features from these linear layers are called patch embeddings.
What is Class Token?
A learnable [class] token is added at the beginning of the sequence of the patch embeddings. The [class] token gathers information from the sequence of the patches over the different layers and learns the general image representation. It is basically an empty learnable token whose output would be used for the purpose of image classification.
Later when the ViT is used for image classification, an MLP (Multilayer Perceptron) is used. The MLP uses the information from the [class] token and leaves the rest. In this way, the model is not biased towards any specific image patch.
Position Embeddings
Now position embeddings are also added to patch embeddings to retain the positional information. The authors have used simple 1-dimension learnable position embeddings. The positional encoding helps in ViT to determine the correct sequence of patches, such as the 1st patch referring to the top-left and so on.
Transformer Encoder
The transformer encoder begins with Normalization Layer (LayerNorm), Multi-Head Self Attention (MSA) and then is followed by a residual connection from the input. Next, we again have the Normalization Layer (LayerNorm), followed by a sequence of MLP (Multilayer Perceptron) and the residual connection. The MLP consists of two Linear (fully connected) layers
and a GELU (Gaussian Error Linear Units) in between.

Results
The authors have pre-trained the ViT on large datasets and fine-turned downstream tasks. The ViT is trained on the following datasets:
- ImageNet1k – 1k classes and 1.3 million images.
- ImageNet21k – 21k classes and 14 million images.
- JFT – 18k classes and 303 million images.
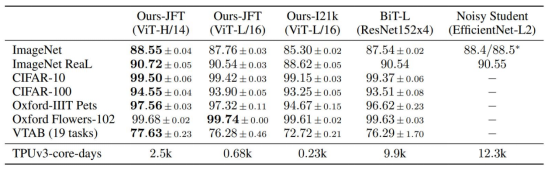
The above table shows the results of ViT pre-trained on the JFT dataset and outperforms ResNet-based architecture on all the downstream datasets.
Summary
In this paper, the authors focused on using the Transformer architecture for task image classification. For this purpose, the authors developed the Vision Transformer (ViT), which obtains state-of-the-art performance when compared with the ResNet the standard CNN architecture.




