
This article covers an overall summary of the MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformers research paper. MobileViT is a lightweight and general-purpose vision transformer for mobile vision tasks. It combines the strength of the standard CNN (Convolutional Neural Network) and the Vision Transformers. It has outperformed several CNNs and ViT-based networks across different tasks and datasets. On the ImageNet-1k dataset, MobileViT had achieved top-1 accuracy of 78.4% with about 6 million parameters, which is 3.2% and 6.2% more accurate than MobileNetv3 (CNN-based) and DeIT (ViT-based) architectures having a similar number of parameters. On the MS-COCO object detection task, MobileViT is 5.7% more accurate than MobileNetv3 for a similar number of parameters.
The architecture of the MobileViT is proposed by researchers from Apple and is published as a conference paper at ICLR 2022. Till now, it is cited 127 times.
Outlines:
- What is the need for MobileViT?
- Architecture
- Results
- Summary
What is the need for MobileViT?
The high performance in ViT comes with a huge number of parameters and latency which is not effective for many real-world applications. These applications require the model to run effectively on less-hardware resources such as mobile phones, embedded devices, etc. The huge number of parameters required in ViT is likely because they lack image-specific inductive bias, which is an inherent property of CNNs.
To build a more robust and high-performing ViT model, the authors combine CNN and ViT. The focus is on designing a light-weight, general-purpose and low-latency network for mobile vision tasks. With MobileViT, the authors combine the strength of CNNs (e.g., spatial inductive biases and less sensitivity to data augmentation) and ViTs (e.g., input-adaptive weighting and global processing). The paper proposes a MobileViT block that encodes both local and global information more effectively.

Architecture
The core idea of MobileViT is to learn global representations with transformers as convolutions. This allows the network to more easily incorporate convolution-like properties (e.g., spatial bias) and learn image representation with fever parameters and simple training recipes.
MobileNetv2 (MV2) Block
The MV2 blocks refer to the Inverted Residual block, which is introduced in the MobileNetv2 research paper: MobileNetV2: Inverted Residuals and Linear Bottlenecks. The research paper is accepted at the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
The Inverted Residual block begins with a 1×1 point-wise convolution, followed by a depthwise convolution layer and at last, has a 1×1 point-wise convolution. After that, it had a residual connection, that add the input and output of the block.

MobileViT Block
The MobileViT block aims to model the local and global information in an input tensor with fewer parameters. The following sequence of operations are applied to the input tensor in the MobileViT block.
- Input tensor: X = H x W x C, refers to the height, width and number of channels in the input feature map.
- The input tensor is passed through a n x n convolution and then a 1×1 convolution, which projects the feature to high-dimensional (d-dimensional) space.
- The feature maps XL (H x W x d) are then transformed into N non-overlapping flattened patches XU (P x N x d). Here,
- P = wh, hw refers to the height and width of the patches.
- N=HW/P, HW refers to the height and width of feature maps XL.
- N is the number of patches.
- The flattened patches are passed to the Transformers to learn global representations with spatial inductive bias. The output from transformers XG = P x N x d.
- The XG is then again transformed back into XF = H x W x d. Next, a 1×1 convolution is applied and concatenated with the input tensor X.
- Another n × n convolution is applied to fuse these concatenated features.
Variants of MobileViT
The MobileViT has three models having different network sizes:
- Small – MobileViT-S
- Extra small – MobileViT-XS
- Extra extra small – MobileViT-XSS
MobileViT Architecture
The architecture begins with a 3×3 convolution, followed by multiple MV2 (Inverted Residual) blocks from MobileNetv2 and MobileViT blocks. The swish activation function is used in the entire architecture. The spatial dimensions (height and width) of the feature maps are usually multiple of 2. Therefore, a patch size of 2×2 is used at all levels. The MV2 blocks are mainly used for downsampling the feature maps by applying strided convolution.
Results
The MobileViT is trained on the ImageNet-1k classification dataset. MobileViT outperforms both the light-weight CNNs and heavy-weight CNNs on the ImageNet-1k validation set.
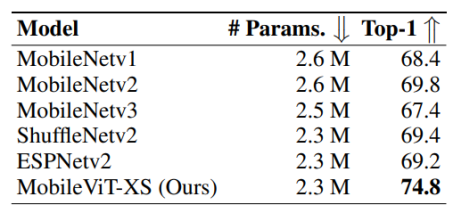
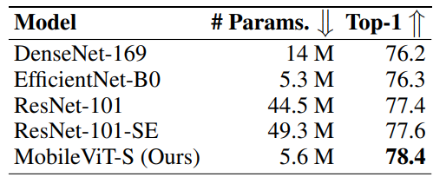
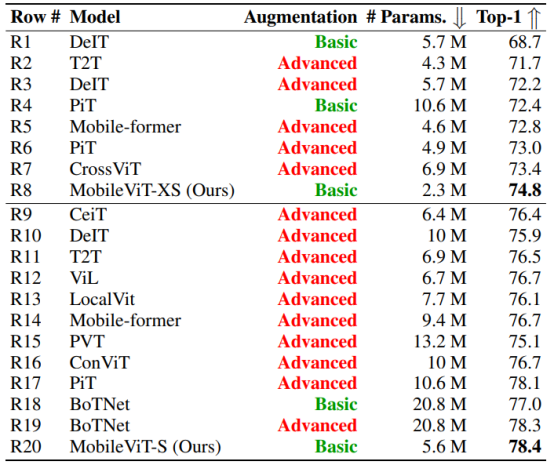
MobileViT also outperforms several ViT (Vision Transformer) based architectures on the ImageNet-1k validation dataset.
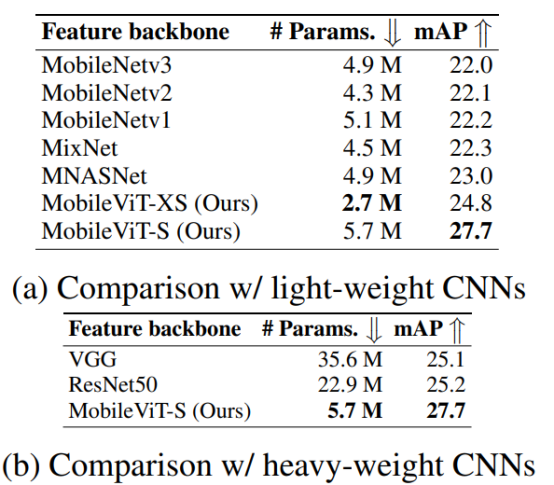
MobileViT also achieves top performance on object detection (SSDLite) and semantic segmentation (DeepLabv3).
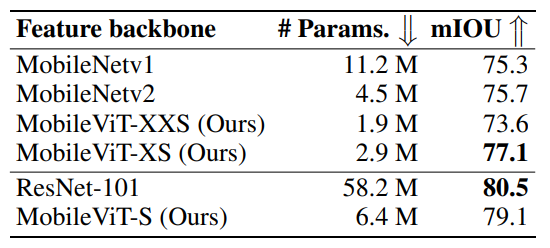
Summary
In short, we can say that MobileViT is light-weight, general-purpose and low latency network for mobile vision tasks, which combines the strength of the CNN and the Vision Transformers. It has outperformed several light-weight and heavy-weight architectures on the ImageNet-1k dataset. MobileViT also shows high performance on both object detection and semantic segmentation.




