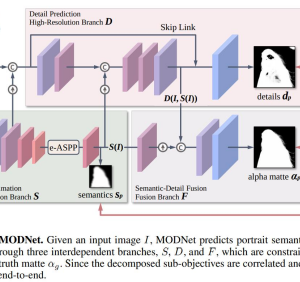
In this work, we present a lightweight matting objective decomposition network (MODNet) for portrait matting in real-time with a single input image. MODNet inputs a single RGB image and applies explicit constraints to solve matting sub-objectives simultaneously in one stage. The research paper is accepted at AAAI 2022 conference.
Research paper: https://arxiv.org/pdf/2011.11961v4.pdf
The method proposed two novel techniques:
- Efficient Atrous Spatial Pyramid Pooling (e-ASPP): fuse multi-scale features for semantic estimation
- Self-supervised sub-objectives consistency (SOC) strategy: It is used to adapt MODNet to real-world data to address the domain shift problem common to trimap-free methods
What is Portrait Matting?
Portrait matting aims to predict a precise alpha matte that can be used to extract the persons in a given image or video.

The purpose of the image matting task is to extract the desired foreground F from a given image I. This task predicts an alpha matte with a precise foreground probability value α for each pixel i as:
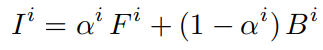
READ MORE:
- Deep Learning based Background Removal from Images using TensorFlow and Python
- PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
Method
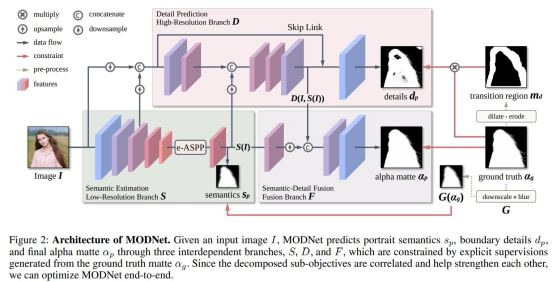
In MODNet, we divide the trimap-free matting objective into three branch:
- Semantic estimation
- Detail prediction
- Semantic-detail fusion
All the three branches of the MODNet are interconnected with each other. Each branch predicts a mask which is further used by the other branchs to finally predicts the required alpha mask.
The input image is passed to the semantic estimation branch which predicts a low-resolution course segmentation mask. This course mask is then used by the detail prediction branch to further predicts a detailed mask. Both the course mask and the detailed mask is used by the semantic-detail fusion branch to finally predict the high-quality alpha matte.
Semantic Estimation
In semantic estimation, the first step is to locate the portrait in the input image. For this purpose, a pre-trained MobileNetV2 is used as the encoder. The input image is fed to the encoder and the output feature map is passed through the Efficient Atrous Spatial Pyramid Pooling (e-ASPP). The e-ASPP is used to efficiently extract and fuse multi-scale features. In the end, we predict a course segmentation mask, which is supervised by the thumbnail of the ground truth matte. The L2 loss function is used to optimize the course mask.

Here,
- Sp refers to the predicted course mask.
- G refers to the downsampled ground-truth with gaussian blur.
Efficient Atrous Spatial Pyramid Pooling (e-ASPP)
ASPP has been proven to improve the performance of the network but with an increase in the number of parameters and the computational cost. To balance the performance and efficiency, the authors proposed an Efficient ASPP (e-ASPP).

Detail Prediction
The aim of the detail prediction branch is to generate a boundary detail matte (mask). The branch takes the input image concatenates it with a feature map from the pre-trained encoder of the semantic estimation branch. The combined feature map is then passed through some convolutional layer and pooling layer. Here the feature maps are reduced by a factor of 4. The reduced feature map is then concatenated with the course segmentation mask and passed through some convolutional layers. Here, the feature map is upsampled back to the original resolution. Next, it is followed by a concatenation with a skip connection. After that, we generate boundary detail matte (mask), which is optimized by L1 loss function.

Here,
- md refers to the boundary mask, which is generated through dilation and erosion on the ground truth.
- dp refers to the predicted boundary detail matte.
- αg refers to the ground truth.
Semantic-Detail Fusion
In this branch, we simply fuse the course segmentation mask and boundary detail-rich feature map from the detail prediction branch to predict the final alpha matte. The alpha matte is optimized by customized loss function Lα
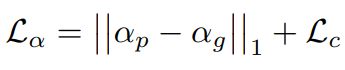
Here,
- αp refers to the predicted alpha matte.
- αg refers to the ground truth.
- Lc refers to the is the compositional loss.
Final Loss
The MODNet is trained end-to-end through a sum of all the loss functions with three hyperparameters balancing the losses.

Here,
- λs = λα = 1
- λd = 10
Summary
In summary, the authors focused on designing an efficient and real-time architecture for trimap-free portrait matting architecture called MODNet. To achieve this the authors have decomposed the architecture into three different parts: 1) Semantic Estimation branch, which predicts the course segmentation mask, 2) Detail Prediction branch, which predicts the boundary details and 3) Semantic-Detail Fusion branch to predicts the final alpha matte. With the combination of the above branches, the architecture is able to perform real-time portrait matting.




