The Internet is a rich source of data and information in the world that is easy to acquire. This data includes images, PDF, text, audio, and video. To acquire the data it is necessary to scrape it. In this tutorial, we are going to learn about scraping images with python from a website.
In this tutorial, we are going to learn:
- What is Web Scraping
- Uses of Web Scraping
- Implementation
What is Web Scraping
Web scraping is the process of automatically extracting or mining data and information from the World Wide Web (WWW) using the Hypertext Transfer Protocol (HTTP). It is the process of collecting unstructured data from a webpage and storing it into a structured format.
Video
Implementation
Here we are going to write a program that will help in scraping images with python and its respective alt tag value from a website. The website which we are going to use is https://www.freepik.com/
Using this program you can create your own dataset from tasks, such as:
- Image classification
- Image captioning
- Text to Image generation and many more
First we will imports all the required libraries and the functions.
import os
import requests
from bs4 import BeautifulSoup
import cv2
from skimage import ioNext we are going to write a function that will helps us to create a directory if it does not exist.
def create_dir(path):
""" Create folders """
try:
if not os.path.exists(path):
os.makedirs(path)
except OSError:
print("Error")Now, we are going to write a function that will helps us to create an empty CSV file. This CSV file is going to store the path of the image and its respective alt attribute information.
def create_file(path):
""" Create a file """
try:
if not os.path.exists(path):
f = open(path, "w")
f.write("Name,Alt\n")
f.close()
except OSError:
print("Error")Now we will start working on the main function called save_image. This function save_image takes the search_term and page_num as the parameters.
The search_term is used to search the images on the website and we are going to extract these images and alt attribute information. The page_num indicate the current page number, you can use this variable to go to the requrired page and this will help us to extract the images from the multiple pages.
def save_image(search_term, page_num=1):
## URL and headers
url = "https://www.freepik.com/search?dates=any&format=search&page="+str(page_num)+"&query="+str(search_term)+"&selection=1&sort=popular&type=photo"
header = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'}
## making a GET request to the website and getting the information in response.
result = requests.get(url, headers=header)
if result.status_code == 200:
soup = BeautifulSoup(result.content, "html.parser")
else:
print("Error")
exit()
## Paths and file for saving the images and data.
dir_path = f"Downloads/{search_term}/"
file_path = f"Downloads/{search_term}/{search_term}.csv"
create_dir(dir_path)
create_file(file_path)
f = open(file_path, "a")
for tag in soup.find_all("a", class_="showcase__link"):
if tag.img:
try:
src = tag.img["data-src"]
alt = tag.img["alt"]
except Exception as e:
alt = None
try:
if alt:
image = io.imread(src)
name = src.split("/")[-1].split("?")[0]
data = f"{name},{alt}\n"
f.write(data)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
cv2.imwrite(dir_path + name, image)
print(name, ": ", alt)
except Exception as e:
passLet us understand the functionality of the save_image function in detail.
url = "https://www.freepik.com/search?dates=any&format=search&page="+str(page_num)+"&query="+str(search_term)+"&selection=1&sort=popular&type=photo"The url consists of the search_term and page_num variable and other paramaters and this url is address to the content from where we are goint to extract the images.
header = {'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36'}
## making a GET request to the website and getting the information in response.
result = requests.get(url, headers=header)
if result.status_code == 200:
soup = BeautifulSoup(result.content, "html.parser")
else:
print("Error")
exit()Now we are going to make a GET requests to the url specified above using the requests.get function. The function will return some data in the result variable. After that we check the status code to make sure that we have fetch the entire HTML code from the url.
If the status code is 200, means everything is going good, else their is some problem in fetching the HTML code from the url.
After getting the HTML code, we parse it with the BeautifulSoup library.
## Paths and file for saving the images and data.
dir_path = f"Downloads/{search_term}/"
file_path = f"Downloads/{search_term}/{search_term}.csv"
create_dir(dir_path)
create_file(file_path)
f = open(file_path, "a")Here, we create the proper directory and files for saving the images and alt attribute information. After that we open the file that we have created.
for tag in soup.find_all("a", class_="showcase__link"):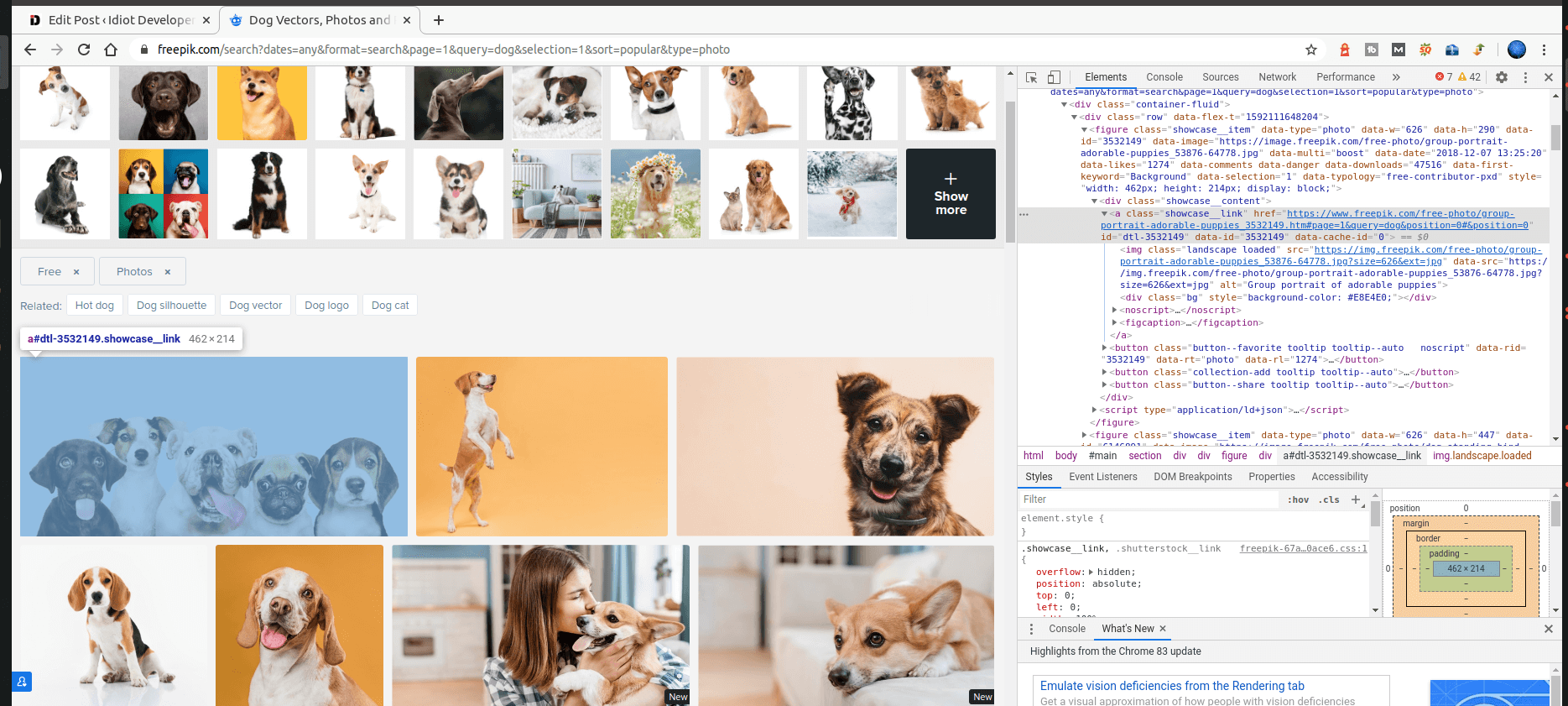
As we have to extract the images url, so we first extract all the anchor tage with the class showcase__link.
if tag.img:
try:
src = tag.img["data-src"]
alt = tag.img["alt"]
except Exception as e:
alt = NoneNow we check the if there is any img tag inside the anchor tag. If an img tag is found we extract the src of the image. In our case, we are using the data-src attribute, generally the src attribute is used with img tag. We also extract the alt attribute information.
try:
if alt:
image = io.imread(src)
name = src.split("/")[-1].split("?")[0]
data = f"{name},{alt}\n"
f.write(data)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
cv2.imwrite(dir_path + name, image)
print(name, ": ", alt)
except Exception as e:
passAfter extracting image url and alt attribute information, we try to save it.
First we check the alt variable, if it contains any information or it is blank or null. If it contains some information, then we read the image from the src variable containing the image url and then storing the image (numpy array) the image variable.
We take the src variable and extract the image name that we are going to use while saving the image in the appropriate directory and also when writing in the CSV file.
Next, we write the image name and alt attribute information in the CSV file.
After this, we convert the image channels from BGR to RGB format using the cv2.cvtColor function and then save it in the appropriate folder.
Till now we have learned about the main part of the program. Now we will use the save_image function to extract and save image and alt attribute information.
if __name__ == "__main__":
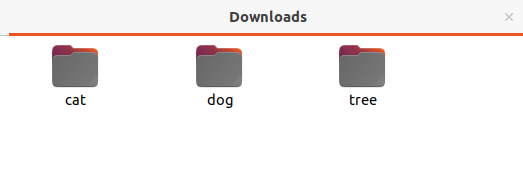
terms = ['dog', 'cat', 'tree']
for term in terms:
save_image(term, page_num=1)
save_image(term, page_num=2)The program will save the images and alt attribute information for all the three terms in the appropriate directories and in the CSV file. the CSV file for a search term will be inside the search term directory.
Conclusion
This is all about scraping images with python. I hope that you find this tutorial useful and make sure that you also subscribe to my YouTube channel.
More:
- U-Net segmentation: https://idiotdeveloper.com/unet-segmentation-in-tensorflow/
- Polyp segmentation using U-Net: https://idiotdeveloper.com/polyp-segmentation-using-unet-in-tensorflow-2/
- Convolutional autoencoder in TensorFlow 2.0: https://idiotdeveloper.com/building-convolutional-autoencoder-using-tensorflow-2/