
In this article, we are going to implement the most widely used image segmentation architecture called UNET. We are going to replace the UNET encoder with the VGG16 implementation from the TensorFlow library. The UNET encoder would learn the features from scratch, while the VGG16 is already trained on the Image ImageNet classification dataset. Therefore VGG16 has already learned enough features, which improves the overall performance of the network.
What is UNET?
UNET is an image segmentation architecture developed by Olaf Ronneberger et al. for Biomedical Image Segmentation in 2015 at the University of Freiburg, Germany. It is a fully convolutional neural network that is designed to learn from fewer training samples. It is an improvement over the existing FCN – “Fully convolutional networks for semantic segmentation” developed by Jonathan Long et al. in (2014). The UNET architecture is primarily used as the baseline architecture for any semantic segmentation task.
UNET Research Paper (Arxiv): U-Net: Convolutional Networks for Biomedical Image Segmentation
READ MORE: What is UNET?

What is VGG16?
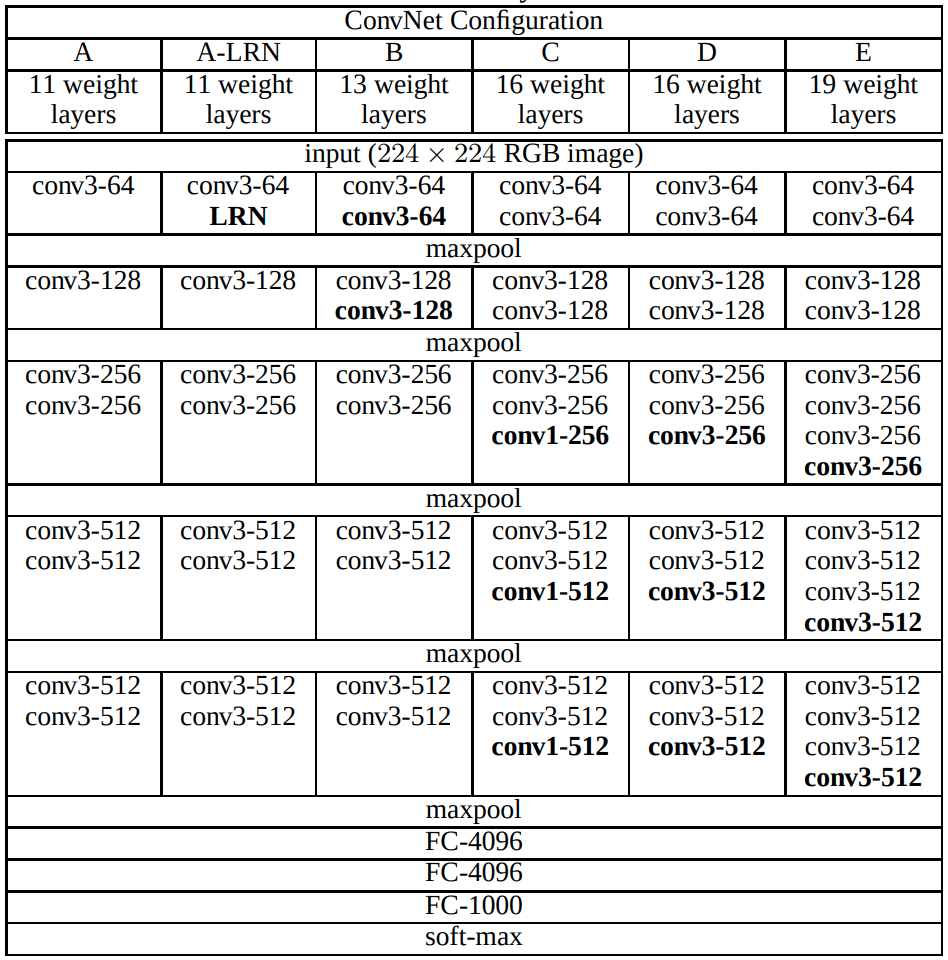
VGG16 is an image classification architecture developed by Karen Simonyan and Andrew Zisserman in 2014. The architecture was published in the paper “Very Deep Convolutional Networks for Large-Scale Image Recognition”. VGG16 achieves 1st position in object localisation and 2nd position in the image classification task.

VGG16 Research Paper (Arxiv): Very Deep Convolutional Networks for Large-Scale Image Recognition
The main contribution of the VGG16 is the extensive study of the increasing depth using the 3×3 convolutional filters. In particular, significant improvement has from VGG16 to VGG19. The number 16 and 19 denotes the depth of the VGG16 and VGG19 network respectively.
VGG16 UNET Implementation
We are going to implement the VGG UNET in TensorFlow version 2.5 using the python programming language. The complete code can be downloaded from the link below.
Import
In the beginning, we are going to import all the required layers and the VGG16 architecture.
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Conv2DTranspose, Concatenate, Input
from tensorflow.keras.models import Model
from tensorflow.keras.applications import VGG16
Convolution Block
Here, we are going to define the convolution block, which consists of two 3×3 convolution layers. Each convolution layer is followed by a batch normalization layer and a ReLU activation function.
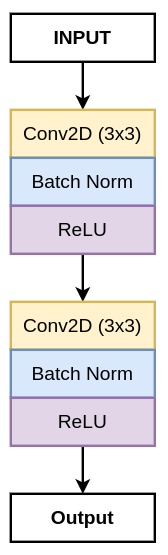
The block diagram of the convolution block
def conv_block(input, num_filters):
x = Conv2D(num_filters, 3, padding="same")(input)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv2D(num_filters, 3, padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
return x
The conv_block function takes the following arguments:
- input: It is the output of the previous block.
- num_filters: The number of feature channel for the convolution layers.
Decoder Block
After, the convolution block, we are going to define the decoder block, which consists of a 2×2 Transpose Convolution layer followed by the skip connection taken the VGG16 pre-trained encoder. Next, it is followed by a conv_block function.
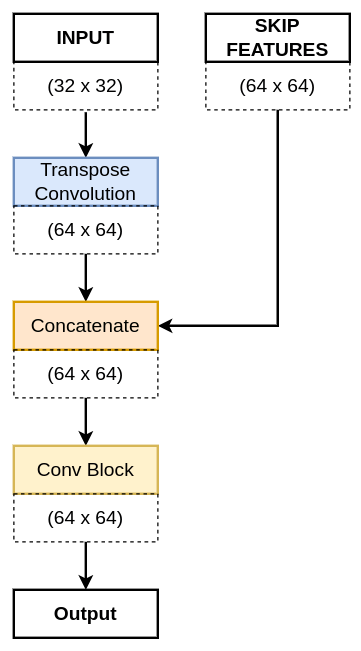
The above diagram of the decoder block shows the flow of information inside it. The dotted box shows the height and width of the different feature maps. The above diagram represents the first decoder, where the INPUT is the b1 and the SKIP FEATURES is the s4.
def decoder_block(input, skip_features, num_filters):
x = Conv2DTranspose(num_filters, (2, 2), strides=2, padding="same")(input)
x = Concatenate()([x, skip_features])
x = conv_block(x, num_filters)
return x
The decoder_block takes the following arguments:
- input: It is the output of the previous block.
- skip_features: These are the appropriate size feature maps from the pre-trained VGG16 encoder.
- num_filters: These represent the number of feature channels for the conv_block.
VGG16 UNET
Now, we are going to build the VGG16 UNET architecture. Here, we will begin by defining the following:
- Input layer
- Pre-trained VGG16 encoder
- Decoder
- Finally, VGG16 UNET.
- Run the model.
Input Layer
We begin by defining the build_vgg16_unet function. The function takes only one argument:
- input_shape: It is tuple consisting of height, width and the number of channels. For example: (512, 512, 3).
def build_vgg16_unet(input_shape):
""" Input """
inputs = Input(input_shape)
Pre-trained VGG16 Encoder
vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=inputs)
We use the VGG16 architecture defined by the TensorFlow library. It takes the following arguments:
- include_top: We set its value to False, as we do not want to include the fully-connected layer on the top. We just want to load the convolutional layers.
- weights: The value for this argument isa string called imagenet. The string imagenet denotes the weights that need to loaded in the VGG16 architecture. If you do not want to load any weight in the network, then you can say weights=None.
- input_tensor: The input_tensor takes the input image represented by the inputs variable.
So, now we are going to extract the required feature maps from the specific layers from the pre-trained encoder. Now, these features would be used as the skip connections and the output of this encoder.
s1 = vgg16.get_layer("block1_conv2").output ## (512 x 512)
s2 = vgg16.get_layer("block2_conv2").output ## (256 x 256)
s3 = vgg16.get_layer("block3_conv3").output ## (128 x 128)
s4 = vgg16.get_layer("block4_conv3").output ## (64 x 64)
The s1, s2, s3 and s4 represent the skip connection from the pre-trained encoder and these are going to be used in the appropriate decoder blocks.
The original UNET architecture consists of a convolution block connecting the encoder and the decoder. Here, we are going to use the pre-trained VGG16 features as the bridge.
""" Bridge """
b1 = vgg16.get_layer("block5_conv3").output ## (32 x 32)
Decoder
Till now we have built the encoder and now we are going to use the b1 as the input for the first decoder block.
d1 = decoder_block(b1, s4, 512) ## (64 x 64)
d2 = decoder_block(d1, s3, 256) ## (128 x 128)
d3 = decoder_block(d2, s2, 128) ## (256 x 256)
d4 = decoder_block(d3, s1, 64) ## (512 x 512)
Here, we have built the decoder network consisting of four decoder blocks, where the output of the decoder is passed through a 1×1 convolution layer with sigmoid activation.
""" Output """
outputs = Conv2D(1, 1, padding="same", activation="sigmoid")(d4)
VGG16 UNET Model
So, now we have got the output of the network in the outputs variable. We are going to build the complete model using the Model class imported from the TensorFlow library.
model = Model(inputs, outputs, name="VGG16_U-Net")
return model
Run the Model
Now we have built the VGG16 UNET architecture, we need to run give it input and see the results.
if __name__ == "__main__":
input_shape = (512, 512, 3)
model = build_vgg16_unet(input_shape)
model.summary()
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 512, 512, 3) 0
__________________________________________________________________________________________________
block1_conv1 (Conv2D) (None, 512, 512, 64) 1792 input_1[0][0]
__________________________________________________________________________________________________
block1_conv2 (Conv2D) (None, 512, 512, 64) 36928 block1_conv1[0][0]
__________________________________________________________________________________________________
block1_pool (MaxPooling2D) (None, 256, 256, 64) 0 block1_conv2[0][0]
__________________________________________________________________________________________________
block2_conv1 (Conv2D) (None, 256, 256, 128 73856 block1_pool[0][0]
__________________________________________________________________________________________________
block2_conv2 (Conv2D) (None, 256, 256, 128 147584 block2_conv1[0][0]
__________________________________________________________________________________________________
block2_pool (MaxPooling2D) (None, 128, 128, 128 0 block2_conv2[0][0]
__________________________________________________________________________________________________
block3_conv1 (Conv2D) (None, 128, 128, 256 295168 block2_pool[0][0]
__________________________________________________________________________________________________
block3_conv2 (Conv2D) (None, 128, 128, 256 590080 block3_conv1[0][0]
__________________________________________________________________________________________________
block3_conv3 (Conv2D) (None, 128, 128, 256 590080 block3_conv2[0][0]
__________________________________________________________________________________________________
block3_pool (MaxPooling2D) (None, 64, 64, 256) 0 block3_conv3[0][0]
__________________________________________________________________________________________________
block4_conv1 (Conv2D) (None, 64, 64, 512) 1180160 block3_pool[0][0]
__________________________________________________________________________________________________
block4_conv2 (Conv2D) (None, 64, 64, 512) 2359808 block4_conv1[0][0]
__________________________________________________________________________________________________
block4_conv3 (Conv2D) (None, 64, 64, 512) 2359808 block4_conv2[0][0]
__________________________________________________________________________________________________
block4_pool (MaxPooling2D) (None, 32, 32, 512) 0 block4_conv3[0][0]
__________________________________________________________________________________________________
block5_conv1 (Conv2D) (None, 32, 32, 512) 2359808 block4_pool[0][0]
__________________________________________________________________________________________________
block5_conv2 (Conv2D) (None, 32, 32, 512) 2359808 block5_conv1[0][0]
__________________________________________________________________________________________________
block5_conv3 (Conv2D) (None, 32, 32, 512) 2359808 block5_conv2[0][0]
__________________________________________________________________________________________________
conv2d_transpose (Conv2DTranspo (None, 64, 64, 512) 1049088 block5_conv3[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 64, 64, 1024) 0 conv2d_transpose[0][0]
block4_conv3[0][0]
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 64, 64, 512) 4719104 concatenate[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 64, 64, 512) 2048 conv2d[0][0]
__________________________________________________________________________________________________
activation (Activation) (None, 64, 64, 512) 0 batch_normalization[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 64, 64, 512) 2359808 activation[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 64, 64, 512) 2048 conv2d_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 64, 64, 512) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
conv2d_transpose_1 (Conv2DTrans (None, 128, 128, 256 524544 activation_1[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 128, 128, 512 0 conv2d_transpose_1[0][0]
block3_conv3[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 128, 128, 256 1179904 concatenate_1[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 128, 128, 256 1024 conv2d_2[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 128, 128, 256 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 128, 128, 256 590080 activation_2[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 128, 128, 256 1024 conv2d_3[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, 128, 128, 256 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
conv2d_transpose_2 (Conv2DTrans (None, 256, 256, 128 131200 activation_3[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 256, 256, 256 0 conv2d_transpose_2[0][0]
block2_conv2[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 256, 256, 128 295040 concatenate_2[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 256, 256, 128 512 conv2d_4[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 256, 256, 128 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 256, 256, 128 147584 activation_4[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 256, 256, 128 512 conv2d_5[0][0]
__________________________________________________________________________________________________
activation_5 (Activation) (None, 256, 256, 128 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
conv2d_transpose_3 (Conv2DTrans (None, 512, 512, 64) 32832 activation_5[0][0]
__________________________________________________________________________________________________
concatenate_3 (Concatenate) (None, 512, 512, 128 0 conv2d_transpose_3[0][0]
block1_conv2[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 512, 512, 64) 73792 concatenate_3[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 512, 512, 64) 256 conv2d_6[0][0]
__________________________________________________________________________________________________
activation_6 (Activation) (None, 512, 512, 64) 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 512, 512, 64) 36928 activation_6[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 512, 512, 64) 256 conv2d_7[0][0]
__________________________________________________________________________________________________
activation_7 (Activation) (None, 512, 512, 64) 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 512, 512, 1) 65 activation_7[0][0]
==================================================================================================
Total params: 25,862,337
Trainable params: 25,858,497
Non-trainable params: 3,840
Complete VGG16 UNET Code
Here is the complete code for the implementation of the VGG16 UNET architecture in TensorFlow.
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Conv2DTranspose, Concatenate, Input
from tensorflow.keras.models import Model
from tensorflow.keras.applications import VGG16
def conv_block(input, num_filters):
x = Conv2D(num_filters, 3, padding="same")(input)
x = BatchNormalization()(x)
x = Activation("relu")(x)
x = Conv2D(num_filters, 3, padding="same")(x)
x = BatchNormalization()(x)
x = Activation("relu")(x)
return x
def decoder_block(input, skip_features, num_filters):
x = Conv2DTranspose(num_filters, (2, 2), strides=2, padding="same")(input)
x = Concatenate()([x, skip_features])
x = conv_block(x, num_filters)
return x
def build_vgg16_unet(input_shape):
""" Input """
inputs = Input(input_shape)
""" Pre-trained VGG16 Model """
vgg16 = VGG16(include_top=False, weights="imagenet", input_tensor=inputs)
""" Encoder """
s1 = vgg16.get_layer("block1_conv2").output ## (512 x 512)
s2 = vgg16.get_layer("block2_conv2").output ## (256 x 256)
s3 = vgg16.get_layer("block3_conv3").output ## (128 x 128)
s4 = vgg16.get_layer("block4_conv3").output ## (64 x 64)
""" Bridge """
b1 = vgg16.get_layer("block5_conv3").output ## (32 x 32)
""" Decoder """
d1 = decoder_block(b1, s4, 512) ## (64 x 64)
d2 = decoder_block(d1, s3, 256) ## (128 x 128)
d3 = decoder_block(d2, s2, 128) ## (256 x 256)
d4 = decoder_block(d3, s1, 64) ## (512 x 512)
""" Output """
outputs = Conv2D(1, 1, padding="same", activation="sigmoid")(d4)
model = Model(inputs, outputs, name="VGG16_U-Net")
return model
if __name__ == "__main__":
input_shape = (512, 512, 3)
model = build_vgg16_unet(input_shape)
model.summary()
Summary
In this article or tutorial, we have learned to build the VGG16 UNET. We have learned to replace the UNET encoder with a pre-trained encoder.
Hopefully, I was able to give you some new information and you learn something from this article.
If YES, then, Follow me:





One thought on “VGG16 UNET Implementation in TensorFlow”