MultiResUNET is an architecture developed by Nabil Ibtehaz et al. for the purpose of multimodal biomedical image segmentation at the Bangladesh University of Engineering and Technology. It is an improvement over the existing UNET architecture as it outperforms U-Net on the five biomedical datasets. The high performance of MultiResUNET is due to the introduction of MultiRes Block and the Res Path in the network.
Research Paper (Arxiv): MultiResUNet: Rethinking the U-Net Architecture for Multimodal Biomedical Image Segmentation
The paper is published in the 2020 Journal of Neural Networks with a high impact factor.

Related Post
MultiResUNET – Architecture
MultiResUNET is an encoder-decoder architecture consisting of four encoder blocks and four decoder blocks. Both the encoder and the decoder are connected via a bridge. The encoder network takes the input image, which passes through the entire encoder network where its spatial dimensions are reduced by half and the number of filters increases. While in the decoder network, the number of filters is decreased and feature maps are upsampled by a factor of two. Finally, the output of the last decoder block is passed to a 1×1 convolution with a sigmoid activation function. This generates a binary segmentation mask for the input image.
Before discussing the encoder and the decoder block, we are going to understand the MultiRes Block and the Res Path.
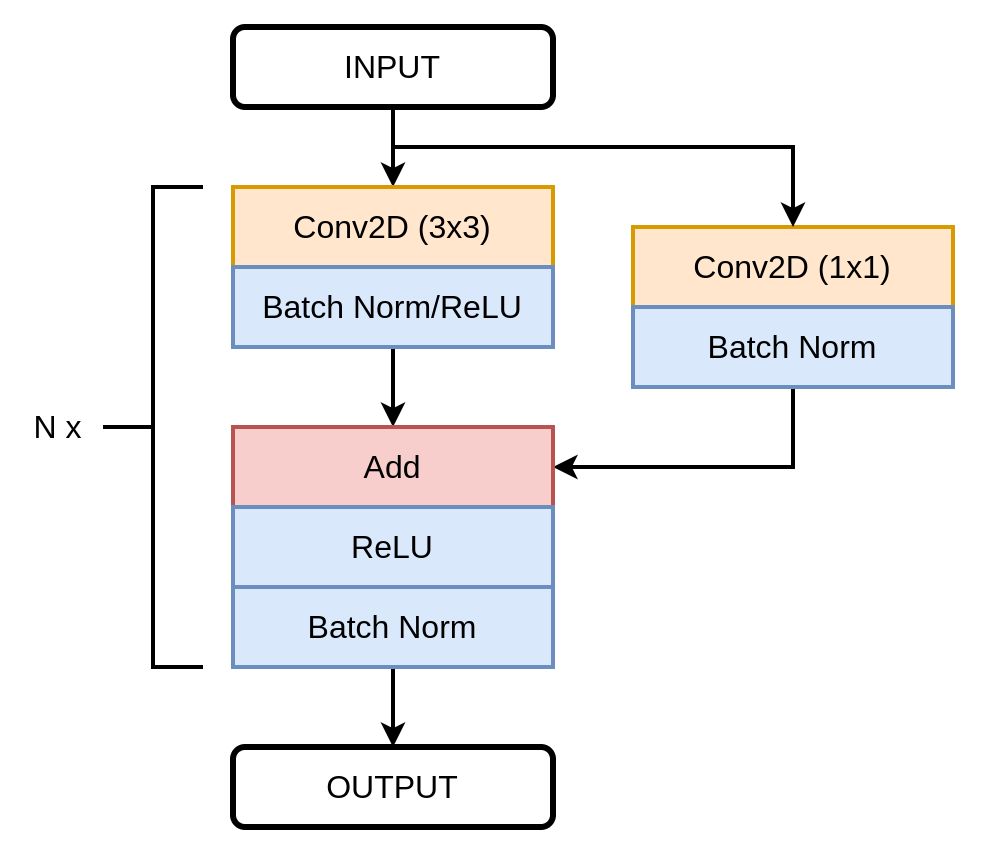
MultiRes Block
The MultiRes Block is a replacement of the convolutional block used in the UNET architecture, where it consists of two 3×3 convolutional layers followed by batch normalization and ReLU activation function.
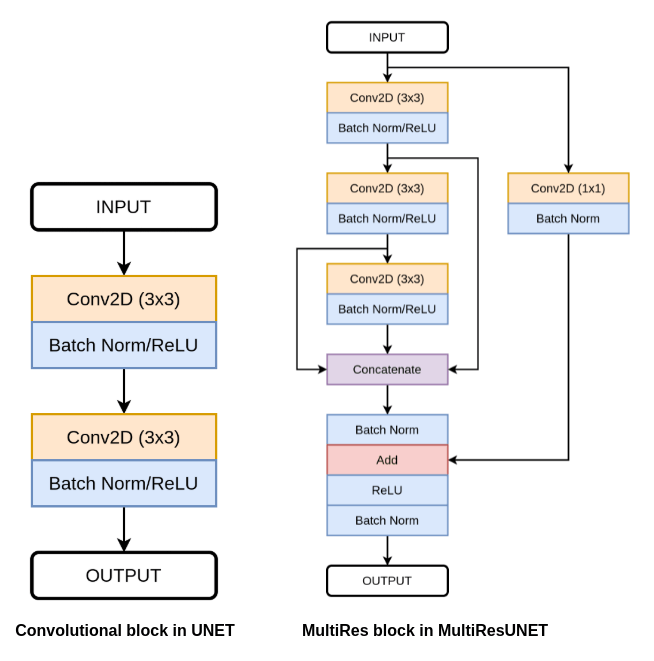
From the above figure, you can see the difference between the convolutional block used in UNET and the MultiRes block used in the MultiResUNET.
The MultiResUNET begins with the three 3×3 convolutional layers connected in series. Each convolutional layer is followed by batch normalization and ReLU. Next, we concatenate the output of all three convolutional layers.
Here, the use of two 3×3 convolutional layers in a sequence resembles a 5×5 convolution. While three 3×3 convolutional layer resembles a 7×7 convolutional layer. So, the author factorizes the bigger convolutional layer into a sequence of smaller 3×3 convolutional layers.
After this, it is followed by a residual connection (identity mapping or shortcut connection) to perform an element-wise addition of the input and concatenated features. Identity mapping helps in better flow of gradients and solves the issue of vanishing gradients. Next, it is followed by a ReLU activation function and Batch Normalization layer.
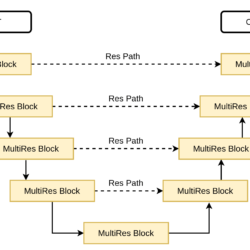
Res Path
The Res Path is a replacement for the simple skip connection present in the U-Net architecture. According to the author, there is a semantic gap between the features of the encoder and the decoder. So, simple concatenation might not work and leads to performance degradation.
To reduce the semantic gap between the features of encoders and the decoders, the Res Path is used. The encoder features are passed through a sequence of Res Path and then the output of Res Path is concatenated with the decoder features.
Encoder Block
The encoder block begins with an input feature map, which is passed to the MultiRes block. The output from the MultiRes block is passed to the two layers:
- Res Path – which passes this feature to the decoder.
- Max-pooling – a 2×2 max-pooling operation is applied and then this feature map is passed to the next block.
Decoder Block
The decoder block begins with a Transpose Convolution layer, which learns and increases the height and width of the input feature map by a factor of 2. The upsampled feature map is then concatenated with the output of the Res Path. Next, the concatenated feature map is then passed through a MultiRes block. The output of the MultiRes block acts as the output of the decoder block.
Summary
In this article, we learn about the MultiResUNET architecture and how it is different from the UNET. The main highlight of this architecture is the introduction of the multiple 3×3 convolution layers in the MultiRes block and the use of Res Path to reduce the semantic gap between the feature of encoder and the decoder.
If you have any questions or queries. Contact me:
IDIOT DEVELOPER – https://www.youtube.com/c/IdiotDeveloper/?sub_confirmation=1




