Transformer-based models have shown remarkable progress in the field of medical image segmentation. However, the existing methods still suffer from limitations such as loss of information and inaccurate segmentation label maps. In this article, we will discuss a new type of adversarial transformer, the Class-Aware Adversarial Transformer (CASTformer), which overcomes these limitations and provides better results for medical image segmentation.
Research paper: Class-Aware Adversarial Transformers for Medical Image Segmentation
Problems with Existing Transformer-based Models
- Naive tokenization scheme: The existing methods fail to capture the important features of the images due to the naive tokenization scheme.
- Single-scale feature representations: The models suffer from information loss because they only consider single-scale feature representations.
- Inaccurate segmentation label maps: The segmentation label maps generated by the models are not accurate enough without considering rich semantic contexts and anatomical textures.
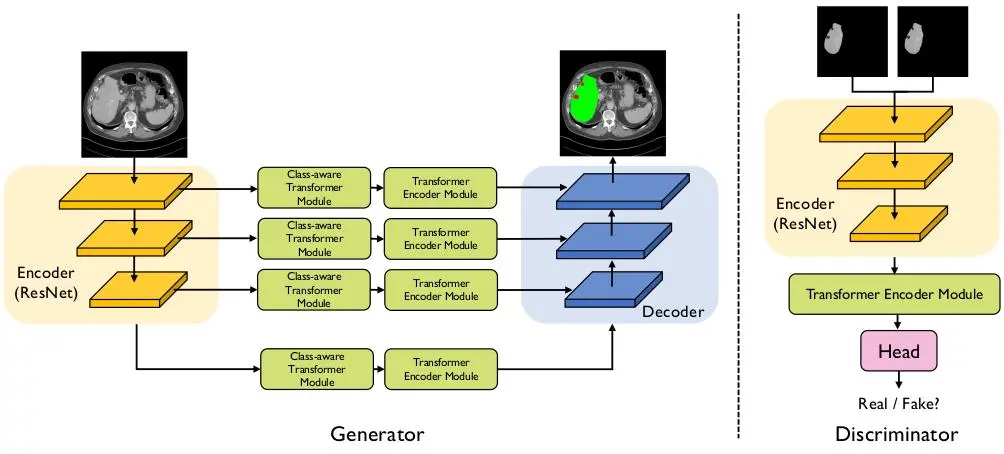
and a discriminator.
Related Post
- GAN – What is Generative Adversarial Network?
- Vision Transformer – An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
Class-Aware Adversarial Transformer
To tackle the limitations of existing transformer-based models, the authors proposed a new type of adversarial transformer called CASTformer. The CASTformer uses a pyramid structure to construct multi-scale representations and handle multi-scale variations. The authors also designed a novel class-aware transformer model to better learn the discriminative regions of objects within semantic structures. Lastly, the authors utilized an adversarial training strategy to boost segmentation accuracy.
The CASTformer consists of two main components:
- Generator Network – CATformer
- Encoder module – feature extractor
- Class-aware Transformer module
- Transformer Encoder module
- Decoder module
- Discriminator Network
Encoder Module
The encoder module is built using a CNN-Transfromer hybrid. Here, a pre-trained ResNet50 is used to generate multi-scale feature maps. The use of a CNN provides the following advantages:
- The CNN helps transformers to perform better in downstream tasks.
- It provides different resolution feature maps, i.e., high, medium to low resolution. These multi-scale feature maps provide better feature representations.
The authors utilized a feature pyramid for the Transformers and utilize the multi-scale feature maps for the downstream medical segmentation task.
Class-Aware Transformer Module
The Class-Aware Transformer (CAT) Module is designed to focus on the important regions of objects. The CAT module uses 4 separate Transformer Encoder Modules (TEM).
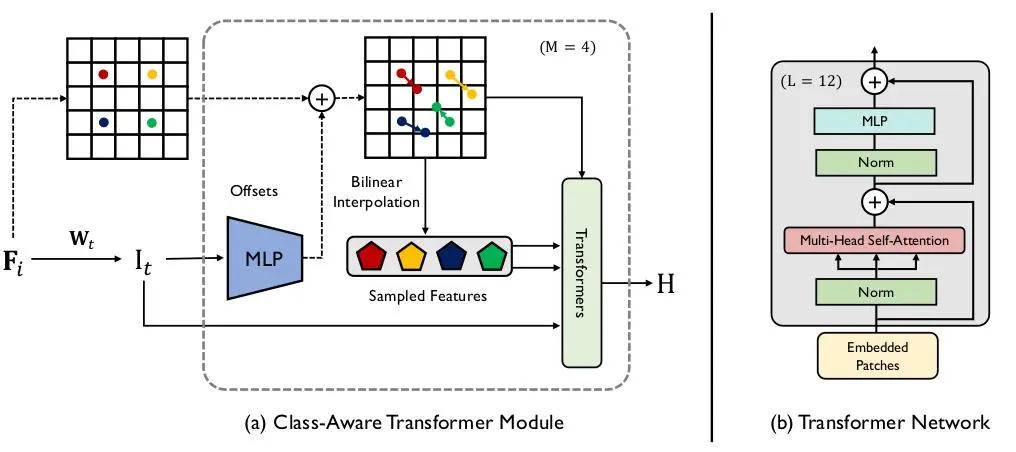
It is an iterative optimization process that updates the sampling locations of the feature map using predicted offset vectors. The CAT module uses bilinear interpolation as the sampling function and the final tokens are obtained through an element-wise addition of the current positional embedding, initial tokens, and estimated tokens from the previous step.
Transformer Encoder Module
The Transformer Encoder Module (TEM) is designed to model long-range contextual information by aggregating global contextual information from the complete sequences of input image patch embedding. Its implementation is the same as the ViT.
Decoder Module
The Decoder Module uses four output feature maps from the Transformer Encoder Module (TEM) and incorporates a lightweight All-MLP decoder for efficiency. The module unifies the channel dimension of the features through MLP layers, up-samples the features, concatenates them, and then uses an MLP layer to predict the segmentation mask.
Discriminator Network
The discriminator network is built using a pre-trained ResNet50+ViTB/16 hybrid model. In the end, a two-layer MLP is added to make a prediction to identify of the class-aware image. The discriminator is used to classify between real and fake samples.
Implementation
The proposed CASTformer is trained using a combination of multiple loss functions. These loss functions are:
- Segmentation loss – dice loss (DL) and cross-entropy loss (CE)
- WGAN-GP Loss – Wasserstein Gradient Penalty Loss
The complete loss function is as follows:
loss = (lambda1 * CE) + (lambda2 * DL) + (lambda3 * WGAN-GP).
- lambda1 = 0.5
- lambda2 = 0.5
- lambda3 = 0.1
The other hyperparameters are as follows:
- Optimizer: Adam
- Learning rate: 5e-4
- Batch size: 6
- Number of epochs: 300
- Input resolution: 224 x 224 x 3
- Patch size: 14 x 14
All our experiments are implemented in PyTorch 1.7.0. We train all models on a single NVIDIA GeForce RTX 3090 GPU with 24GB of memory.
Results
The authors have experimented with three datasets.
1. Synapse multi-organ CT dataset
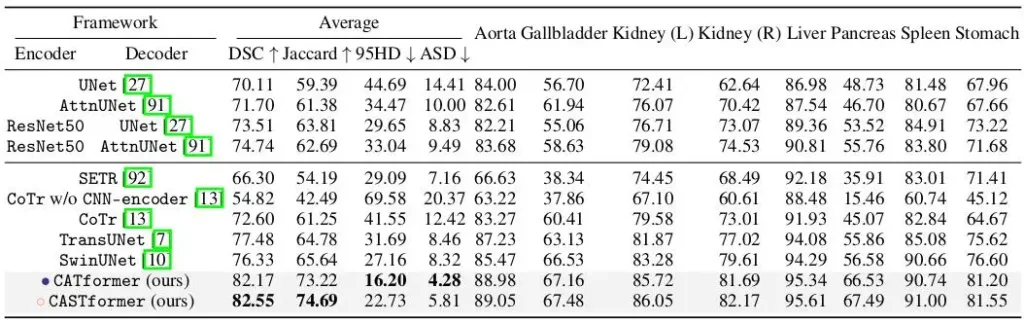

As observed, CASTformer achieves superior performance with detailed anatomical features and the boundary information of different organs.
2. LiTS CT dataset

3. MP-MRI dataset

Ablation Study
Most of the components used in the proposed architecture are pre-trained. According to the authors using pre-trained components helps in achieving better performance with less training dataset.

In the next table, we will see the effectiveness of each component of the Class-Aware Adversarial Transformer (CASTformer).

Conclusion
The Class-Aware Adversarial Transformer (CASTformer) is a novel method for medical image segmentation that overcomes the limitations of existing transformer-based models. By incorporating a pyramid structure and a class-aware transformer model, the CASTformer is able to capture rich global spatial information and local multi-scale context information. The results show that the CASTformer outperforms existing methods and holds promise for future applications in the medical industry.