
This tutorial will teach you how to implement basic Generative Adversarial Networks (GANs) in TensorFlow using Keras API. For this purpose, we will utilize the Anime Face Dataset and try to generate realistic anime faces. What is GAN GAN stands for Generative Adversarial Network, a framework in which two neural Continue Reading
computer vision
Read 3D NIFTI Images in Python3

Medical imaging is an essential tool in the diagnosis, treatment, and monitoring of various medical conditions. One of the most widely used medical imaging techniques is Magnetic Resonance Imaging (MRI), which produces three-dimensional images of the human body. These images are saved in a standard file format called NIFTI, which Continue Reading
Attention UNET in PyTorch
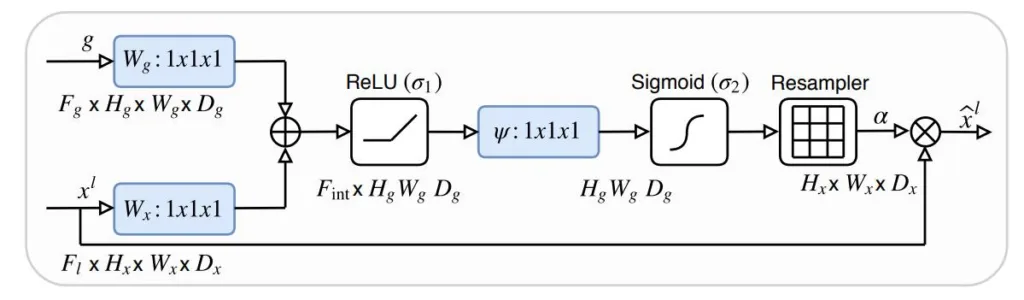
In this article, we are going to learn about the Attention UNET and then implement it in the PyTorch framework. Attention UNET is a type of Convolutional Neural Network (CNN) that is commonly used for image segmentation tasks. It is an extension of the original U-Net architecture, which was proposed Continue Reading
DeepLabV3+ ResNet50 Architecture in TensorFlow using Keras
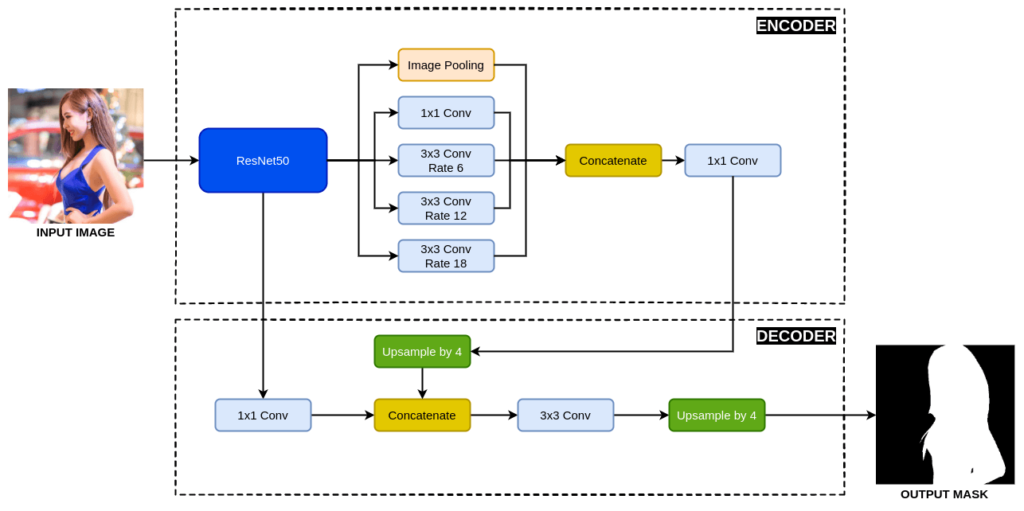
In today’s tutorial, we will be looking at the DeepLabV3+ (ResNet50) architecture implementation in TensorFlow using Keras high-level API. Within this architecture, ResNet50 would be used as the encoder, which is pre-trained on the ImageNet classification dataset. We will begin with the overall architectural understanding of the DeepLabV3+ and ResNet50. Continue Reading
Image Segmentation-based Background Removal in TensorFlow

Image segmentation is an important area of computer vision that involves dividing an image into multiple segments, each of which corresponds to a different object. Background removal is one of the crucial applications of image segmentation that involves separating foreground objects from the background. This can be useful in various Continue Reading
Exploring Bounding Boxes and Different Annotation Formats in Object Detection

Bounding boxes play a critical role in the object detection process, a fundamental task in computer vision. Object detection entails the identification and precise localization of objects within an image. These bounding boxes serve to define the position of an object within the image, allowing for the creation of a Continue Reading
What is MultiResUNET?

MultiResUNET is an architecture developed by Nabil Ibtehaz et al. for the purpose of multimodal biomedical image segmentation at the Bangladesh University of Engineering and Technology. It is an improvement over the existing UNET architecture as it outperforms U-Net on the five biomedical datasets. The high performance of MultiResUNET is Continue Reading
What is Intersection over Union (IoU) in Object Detection?
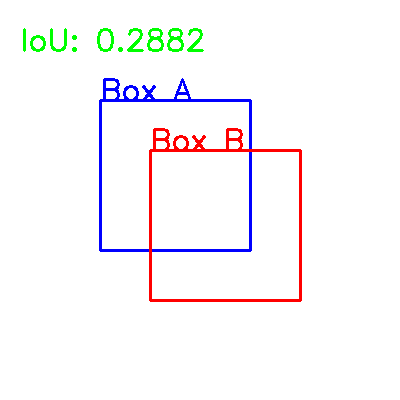
Intersection over Union (IoU) is a popular evaluation metric used in the field of computer vision and object detection. It is used to calculate the overlap between two bounding boxes and is used to evaluate the accuracy of object detection algorithms. IoU is a value between 0 and 1 that Continue Reading
Human Face Detection using Multi-task Cascaded Convolutional Networks in TensorFlow

In recent years, advances in machine learning and deep learning techniques have revolutionized the field of computer vision. With the help of these techniques, we can now detect and identify objects in real time with remarkable accuracy. One of the most popular tasks in computer vision is human face detection, Continue Reading
[Paper Summary] Class-Aware Adversarial Transformers for Medical Image Segmentation
![[Paper Summary] Class-Aware Adversarial Transformers for Medical Image Segmentation](https://idiotdeveloper.com/wp-content/uploads/2023/02/castformer-architecture.webp)
Transformer-based models have shown remarkable progress in the field of medical image segmentation. However, the existing methods still suffer from limitations such as loss of information and inaccurate segmentation label maps. In this article, we will discuss a new type of adversarial transformer, the Class-Aware Adversarial Transformer (CASTformer), which overcomes Continue Reading