Artificial Intelligence (AI) has become an indispensable aspect of modern technology, primarily due to the learning capabilities of AI algorithms from a dataset. This has led to the growth of machine learning, a branch of AI that enables machines to learn and improve from experience without explicit programming. Machine learning is broadly categorized into three types – supervised learning, unsupervised learning, and reinforcement learning, each with its own set of advantages and disadvantages. In this article, we will discuss each of these types of learning, along with their advantages and disadvantages.

Supervised Learning
In supervised learning, we feed the algorithm with the labelled dataset, i.e., input data with its respective output or label. The algorithm is trained on this labelled data and learns to identify patterns in the data and then make predictions on the new input data.
Supervised learning is classified into:
- Classification
- Regression

Classification
- In classification, we predict a categorical or discrete output based on input.
- Some common applications of classification include spam filtering, sentiment analysis, and image recognition.
- Classification algorithms include logistic regression, decision trees, support vector machines, and neural networks.
Regression
- In regression, we predict a continuous output based on input.
- Some common applications of regression include predicting stock prices, estimating housing prices, and forecasting weather.
- Regression algorithms include linear regression, polynomial regression, support vector regression, etc.
Advantages of Supervised Learning
- Supervised learning algorithms are easy to implement.
- With labelled data, the algorithm can quickly learn and make accurate predictions.
- Supervised learning is useful in applications where a large amount of labelled data is available.
Disadvantages of Supervised Learning
- Supervised learning algorithms require labelled data, which can be time-consuming and costly.
- Sometimes, the labelled data is biased or incomplete which can lead to a decline in performance.
- Supervised learning algorithms may not perform well on data which is significantly different from the labelled data they were trained on.
Unsupervised Learning
In unsupervised learning, the algorithm is fed with unlabeled data, it does not require any supervision. The algorithm learns to identify patterns and relationships in the data without being explicitly told what to look for. Unsupervised learning is commonly used in applications such as anomaly detection, clustering, and dimensionality reduction.
Unsupervised learning is classified into:
- Clustering
- Association
- Dimensionality reduction
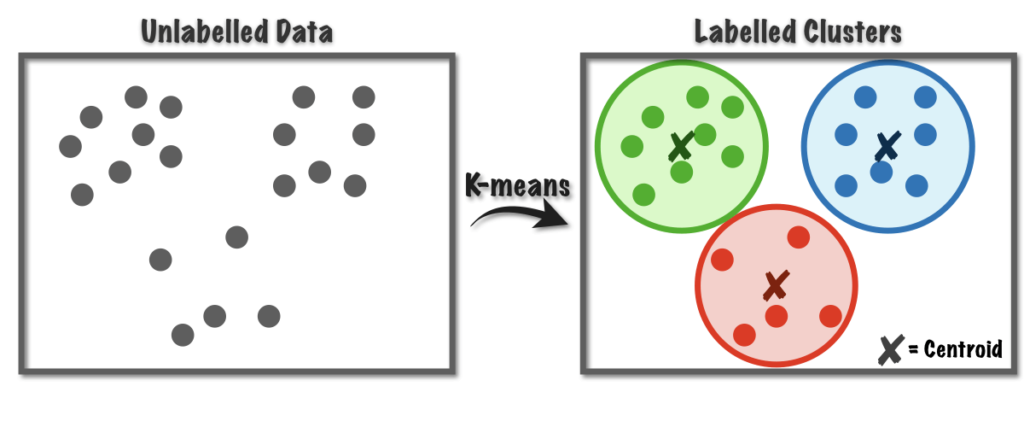
Clustering
- Clustering is the process of grouping similar data points together based on their attributes or features.
- The goal of clustering is to find natural groupings or clusters within the data without prior knowledge of the labels or categories.
- Some examples of clustering algorithms include k-means, hierarchical clustering, and DBSCAN.
Association
- The association is the process of identifying relationships or associations between items in a dataset.
- The goal of association analysis is to find patterns in the data such as frequent itemsets or rules that can be used to make predictions or recommendations.
- Association rules are often used in recommendation systems, market basket analysis, and web log analysis.
Dimensionality Reduction
- Dimensionality reduction is the process of reducing the number of variables or features in a dataset while retaining the most important information.
- The goal of dimensionality reduction is to simplify the data and make it easier to analyze and visualize.
- Some examples of dimensionality reduction techniques include principal component analysis (PCA), t-SNE, and autoencoders.

Advantages of Unsupervised Learning
- Unsupervised learning algorithms can identify patterns and relationships in data that may not be obvious to humans.
- Unsupervised learning is useful in applications where there is a large amount of unlabeled data available.
Disadvantages of Unsupervised Learning
- Unsupervised learning algorithms can be difficult to evaluate, as there is no correct output.
- Unsupervised learning algorithms may not be as accurate as supervised learning algorithms, as they do not have any labels.
Reinforcement Learning
Reinforcement learning involves an agent interacting with an environment to learn how to perform a task. The agent receives feedback in the form of rewards or punishments based on its actions, and it learns to maximize its rewards over time. Reinforcement learning is commonly used in applications such as game playing, robotics, and autonomous driving.
Advantages of Reinforcement Learning
- Reinforcement learning algorithms can learn to perform complex tasks that may be difficult to program explicitly.
- Reinforcement learning algorithms can adapt to changes in the environment or task.
- Reinforcement learning can be used in situations where the optimal solution is not known.
Disadvantages of Reinforcement Learning
- Reinforcement learning algorithms can require a huge amount of computational resources and time to train.
- Reinforcement learning algorithms can be difficult to optimize, as they require balancing exploration (trying new things) with exploitation (using what has already been learned).
- Reinforcement learning algorithms can be sensitive to the rewards or punishments given, and they may not perform well if the feedback is not well designed.
Conclusion
In conclusion, there are three main types of machine learning algorithms: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning involves learning from a labelled dataset, unsupervised learning involves finding structure in an unlabeled dataset, and reinforcement learning involves learning through trial and error. Each type of learning has its own strengths and weaknesses, and they can be used in different applications depending on the nature of the problem at hand.