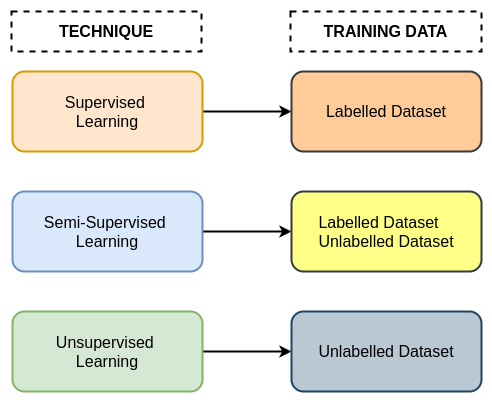
Semi-supervised learning is a type of machine learning where we use a combination of a large amount of unlabelled data and a small amount of labelled data to train the model. It is a hybrid approach between supervised learning and unsupervised learning. The basic difference between the two is that supervised learning algorithms use labelled datasets, while unsupervised learning algorithms use unlabeled datasets.
To learn more about it, we first need to dive into supervised learning and unsupervised learning.
Supervised Learning
In supervised learning, we use a labelled dataset to train a model. The advantage of supervised learning is that we get really good performance, which is the main goal of most machine learning researchers. The drawback is that we have to manually annotate the data to create labels, which is a tedious process. The annotation requires domain expertise and often comes with a high cost, which makes it very expensive and time-consuming.
Unsupervised Learning
In unsupervised learning, we use the unlabelled dataset to discover the hidden patterns and features which are crucial. Unsupervised learning is generally used for clustering, association, dimensionality reduction, and many more. The main advantage is that we do not have to spend time and resources on data annotation since the algorithm uses unlabelled data which is easily available.
READ MORE
Semi-supervised learning
In a semi-supervised learning approach, we take the advantage of both supervised learning and unsupervised learning to train the model. We use the unlabelled dataset to understand the underlying structure of the data and learn the necessary features to better represent the data.
In many real-world applications, the availability of labelled data is limited, and sometimes it is often too expensive to annotate a large amount of data that is necessary. In such cases, it is better to utilize the unlabelled dataset, which offers both lower costs and easier availability.
Why can’t we train a model on the smaller dataset using supervised learning? Supervised learning algorithms are data-hungry by nature, and often require large amounts of training datasets. As we know the deep neural networks have a large number of parameters ranging from a few million to over 10 billion. When such deep models are trained on the smaller dataset, they are prone to overfitting. Instead of generalizing the model starts to memorize the entire dataset, leading to poor performance. Therefore, we cannot train a model on the smaller dataset using a supervised learning approach.
Semi-supervised learning solves the above problems in a more efficient manner. As it uses the large unlabelled dataset to first learn the relevant features and then uses a smaller labelled dataset to finetune the model for the particular task. in this way, we take the advantage of both the supervised learning and unsupervised learning techniques.
Advantages of semi-supervised learning
- It requires a small amount of labelled datasets.
- It is less expensive as we don’t need to annotate the learning amount of data.
Disadvantages of semi-supervised learning
- It is more complex as compared to the supervised learning approach.
- It is a powerful approach, but it may not work always we have to be careful.
For more read the paper: Unlabeled data: Now it helps, now it doesn’t
Summary
In this article, we have learned about the semi-supervised and how it addresses the issue of lack of labelled dataset. We have also discussed how semi-supervised learning is related to supervised and unsupervised learning.
If you still have some questions or queries? Just comment below. For more updates.
Follow me.