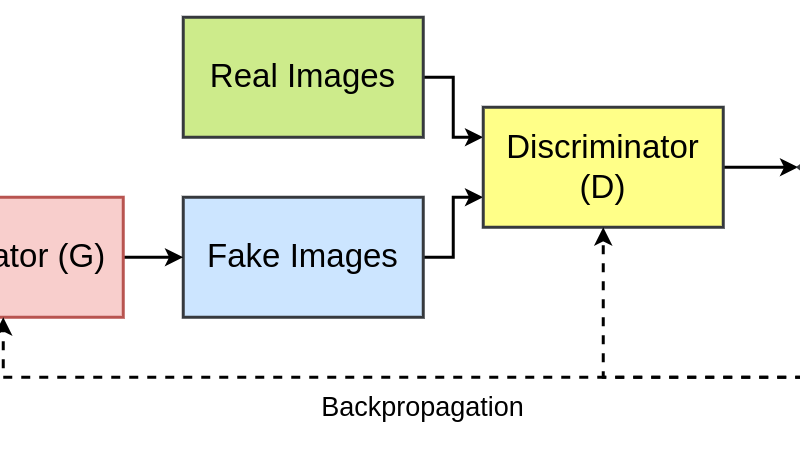
In the realm of generative models, the emergence of Deep Convolutional Generative Adversarial Networks (DCGAN) has marked a significant breakthrough. DCGAN represent an evolution of the traditional Generative Adversarial Networks (GAN), enhancing their capabilities in generating high-quality, realistic images.
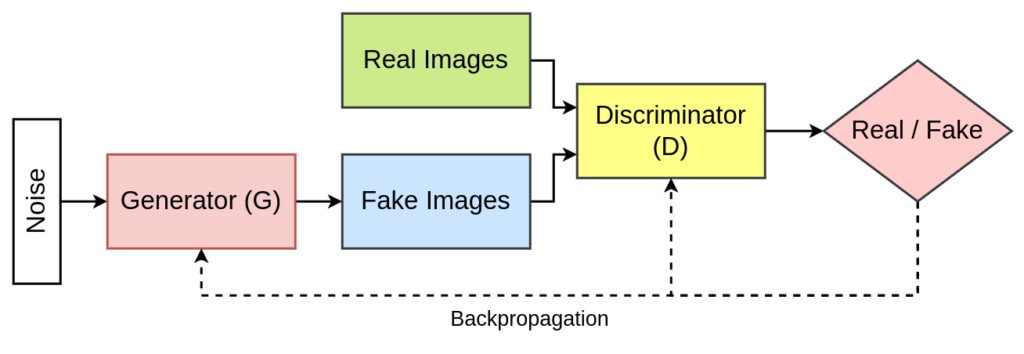
What is DCGAN?
DCGANs are a class of neural networks that leverage convolutional layers for both the generator and discriminator networks. The generator generates images from random noise, while the discriminator aims to differentiate between real and generated images. Through a competitive training process, these networks improve iteratively, with the generator aiming to create more realistic images while the discriminator hones its ability to distinguish between real and synthetic images.
Need for DCGAN
The need for DCGANs stemmed from the limitations of Vanilla GANs in handling complex image data. Traditional GANs struggled to capture spatial dependencies and fine-grained details in images, leading to outputs that lacked coherence and fidelity. DCGANs addressed this need by employing convolutional architectures, enabling them to learn hierarchical representations and generate more compelling visual outputs.
Architecture of DCGAN
DCGAN also consists of two parts: Generator and Discriminator.
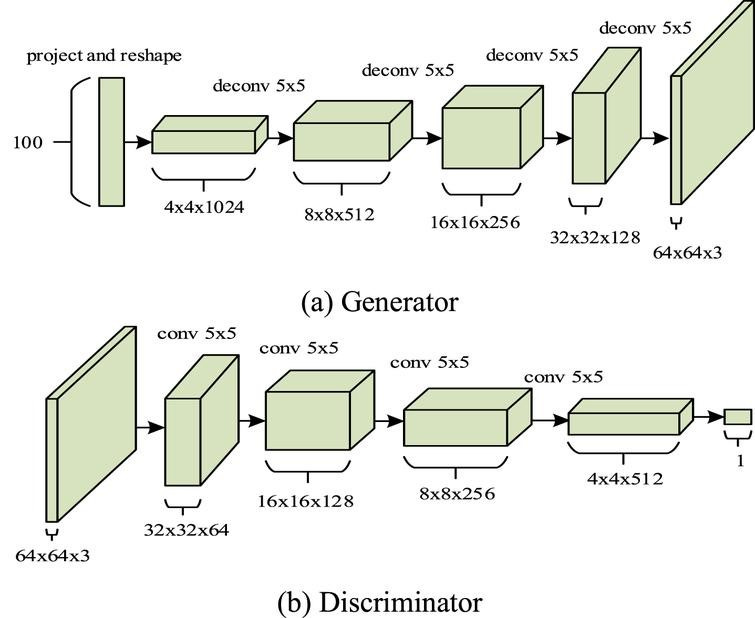
Generator Architecture
The DCGAN generator is designed to synthesize realistic images from random noise. It typically comprises several layers of transposed convolutions, also known as deconvolutions or upsampling layers. Starting with a random noise vector as input, often drawn from a standard normal distribution, this vector is projected through a fully connected layer to a higher-dimensional space. The subsequent layers use transposed convolutions to progressively upsample the features, gradually transforming the initial noise into a complex image representation. Batch normalization, introduced in each layer, helps stabilize the learning process by normalizing the input to each layer and reducing internal covariate shifts.
Moreover, the generator architecture avoids using fully connected layers and replaces them with convolutional and fractional-strided convolutional layers. This alteration allows for the generation of high-resolution images while preserving spatial information. As the network progresses, the spatial dimensions increase while the number of channels decreases, ultimately generating an image that matches the target resolution. Typically, activation functions like ReLU are employed between layers to introduce non-linearity, while the final layer often utilizes a suitable activation function such as tanh to ensure the pixel values of the generated image fall within a specific range, such as [-1, 1].
Discriminator Architecture
In contrast, the discriminator network within a DCGAN functions as a binary classifier, distinguishing between real and generated images. It comprises a series of convolutional layers, each followed by batch normalization and activation functions like LeakyReLU to introduce non-linearity. Strided convolutions are employed to reduce the spatial dimensions of the input, gradually extracting high-level features to discern real images from synthetic ones. The discriminator’s architecture does not include fully connected layers, aligning with the principles of convolutional networks to capture spatial hierarchies effectively.
The discriminator ends with a sigmoid activation function, producing a probability score indicating the authenticity of the input image. During training, the discriminator aims to correctly classify images as real or fake, while the generator strives to produce images that can fool the discriminator into believing they are authentic. This adversarial interplay drives both networks to improve iteratively, resulting in the generation of increasingly realistic images as training progresses.
Advantages of DCGAN
- Feature Learning: DCGANs learn hierarchical representations, capturing features at various levels, facilitating the generation of more realistic images.
- Stability in Training: The architectural constraints imposed in DCGANs, such as using convolutional layers, batch normalization, and avoiding fully connected layers, contribute to a more stable training process.
- Image Quality: DCGANs often produce sharper and more coherent images compared to traditional GANs, making them invaluable in various applications.
Applications of DCGAN
- Image Generation: DCGANs excel in generating high-resolution, photorealistic images across diverse domains, from human faces to landscapes and artworks.
- Data Augmentation: They find utility in augmenting training datasets, especially in scenarios with limited data, enhancing the generalization capability of machine learning models.
- Image-to-Image Translation: DCGANs can aid in tasks like converting sketches to realistic images or altering images in ways that preserve their content while changing aspects like colors or textures.
Conclusion
Deep Convolutional Generative Adversarial Networks stand as a testament to the power of combining adversarial training with convolutional neural networks. Their ability to generate high-fidelity images has propelled advancements in artificial intelligence, promising exciting prospects for image generation, data augmentation, and image manipulation across industries.




