Today, we are going to implement a simple file transfer TCP client-server program in the python programming language. Here, the server is able to handle multiple clients simultaneously by using multiple threads. The server assigns each client a thread to handle communication with that client. Outline Architecture Functions of the Continue Reading
Human Face Landmark Detection in TensorFlow using Pre-trained MobileNetv2

Today, in this blog post, we will learn how to train a Convolutional Neural Network (CNN) to detect human facial landmarks, such as eyes, mouth, nose, jawline and more. We will use the pre-trained MobileNetv2 from TensorFlow to build our model and then train it on Landmark Guided Face Parsing Continue Reading
What is MobileViT?

This article covers an overall summary of the MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformers research paper. MobileViT is a lightweight and general-purpose vision transformer for mobile vision tasks. It combines the strength of the standard CNN (Convolutional Neural Network) and the Vision Transformers. It has outperformed several CNNs and Continue Reading
Vision Transformer – An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale

In this blog post, we are going to learn about the Vision Transformer (ViT). It is a pure Transformer based architecture used for image classification tasks. Vision Transformer (ViT) has the ability to replace the standard CNNs while achieving excellent results. The Vision Transformer (ViT) attains excellent results when pre-trained Continue Reading
MODNet: Real-Time Trimap-Free Portrait Matting via Objective Decomposition
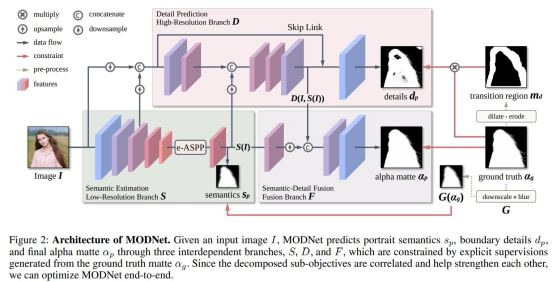
In this work, we present a lightweight matting objective decomposition network (MODNet) for portrait matting in real-time with a single input image. MODNet inputs a single RGB image and applies explicit constraints to solve matting sub-objectives simultaneously in one stage. The research paper is accepted at AAAI 2022 conference. Research Continue Reading
VGG19 UNET Implementation in TensorFlow

In this tutorial, we are going to implement the U-Net architecture in TensorFlow, where we will replace its encoder with a pre-trained VGG19 architecture. The VGG19 is already trained on the ImageNet classification dataset. Therefore, it would have already learned the required features, which would help to boost the overall Continue Reading
Why Deep Learning is not Artificial General Intelligence (AGI)

With the development in the field of deep learning, it has become a frontier in solving multiple challenging problems in computer vision, games, self-driving cars and many more. Deep learning has even achieved superhuman performance in some tasks, but still, it lacks some fundamental features which are required for a Continue Reading
PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
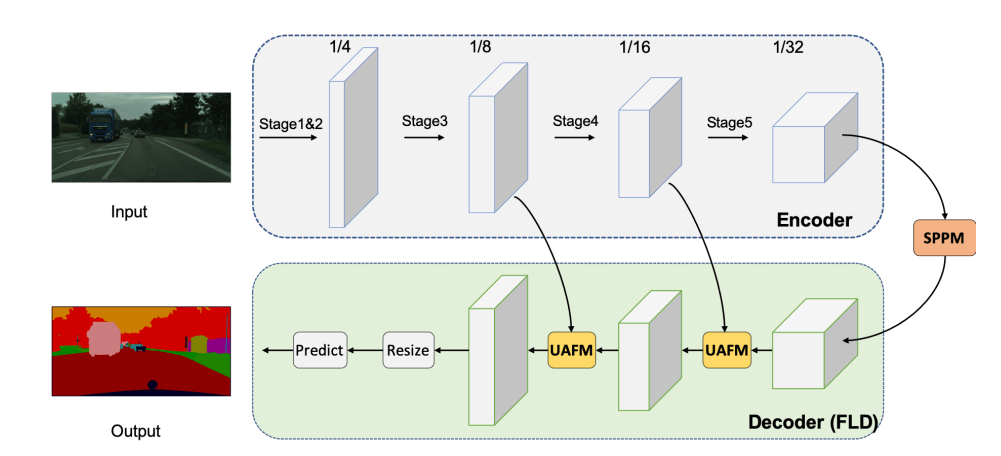
PP-LiteSeg is a lightweight encoder-decoder architecture designed for real-time semantic segmentation. It consists of three modules: Encoder: Lightweight network Aggregation: Simple Pyramid Pooling Module (SPPM) Decoder: Flexible and Lightweight Decoder (FLD) and Unified Attention Fusion Module (UAFM) Encoder The STDCNet is the encoder for the proposed PP-LiteSeg for its high Continue Reading
Deep Learning based Background Removal from Images using TensorFlow and Python

In this tutorial, we are going to learn how to use deep learning to remove background from images with TensorFlow. In short, we’ll use DeepLabV3+, a semantic segmentation based model to extract the background and foreground mask from the image. We are going to use these masks to extract the Continue Reading