
Test Time Augmentation (TTA) is a simple yet powerful technique to improve image segmentation results by applying multiple transformations to an input image during inference and combining the outputs. When paired with models like U-Net, it often boosts performance without retraining. But what if we could go one step further Continue Reading
Computer Vision
Uncertainty Estimation in Image Segmentation using Monte Carlo Dropout in PyTorch

In high-stakes fields like medical imaging, autonomous driving, and remote sensing, a wrong prediction made with high confidence can be catastrophic. That’s where Uncertainty Estimation steps in—empowering your model to express doubt. And with techniques like Monte Carlo Dropout, you can transform any deterministic deep network into a model that Continue Reading
Test Time Augmentation (TTA) for Segmentation in PyTorch

In recent posts, we’ve built a strong foundation around multiclass image segmentation using PyTorch. From creating segmentation masks, converting RGB to class index masks, overlaying results using OpenCV, to training a full-fledged UNet model and visualizing it with GradCAM, we’ve covered the full training pipeline. But what happens when your Continue Reading
GradCAM Heatmaps for Segmentation with UNet in PyTorch

In semantic segmentation, understanding how a deep learning model arrives at its decisions is crucial—especially in fields like medical imaging, agriculture, and autonomous systems. While U-Net and other architectures can deliver high accuracy, they often act as black boxes. In this blog post, we go beyond prediction accuracy. We’ll visualize Continue Reading
Multiclass Segmentation in PyTorch using U-Net
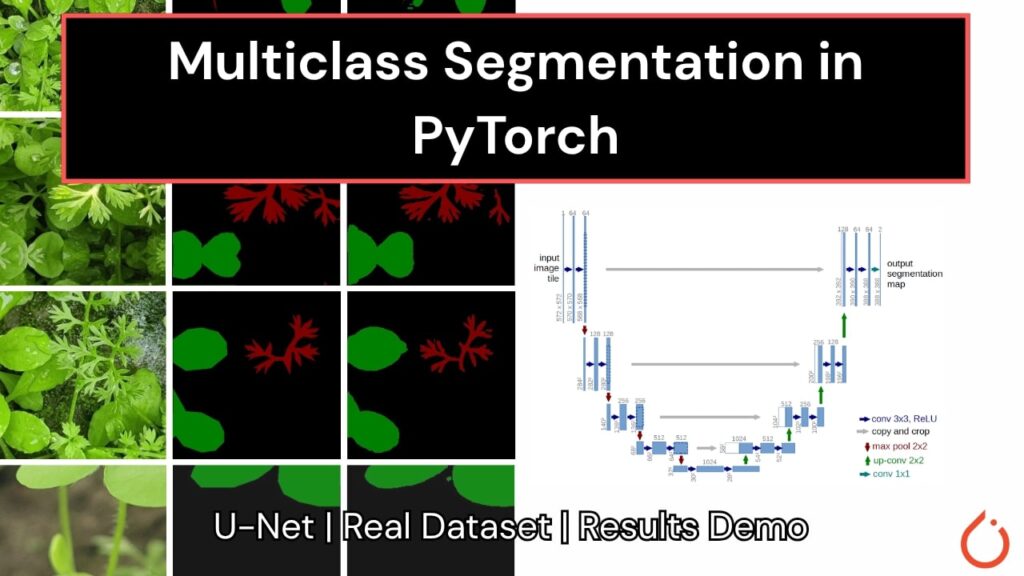
Semantic segmentation is a crucial task in computer vision that involves labeling each pixel in an image with its corresponding class. In this blog post, we’ll dive into building a multiclass semantic segmentation pipeline using the U-Net architecture with PyTorch. Our goal is to segment different types of weeds from Continue Reading
Converting RGB Mask to Class Index Masks in Python
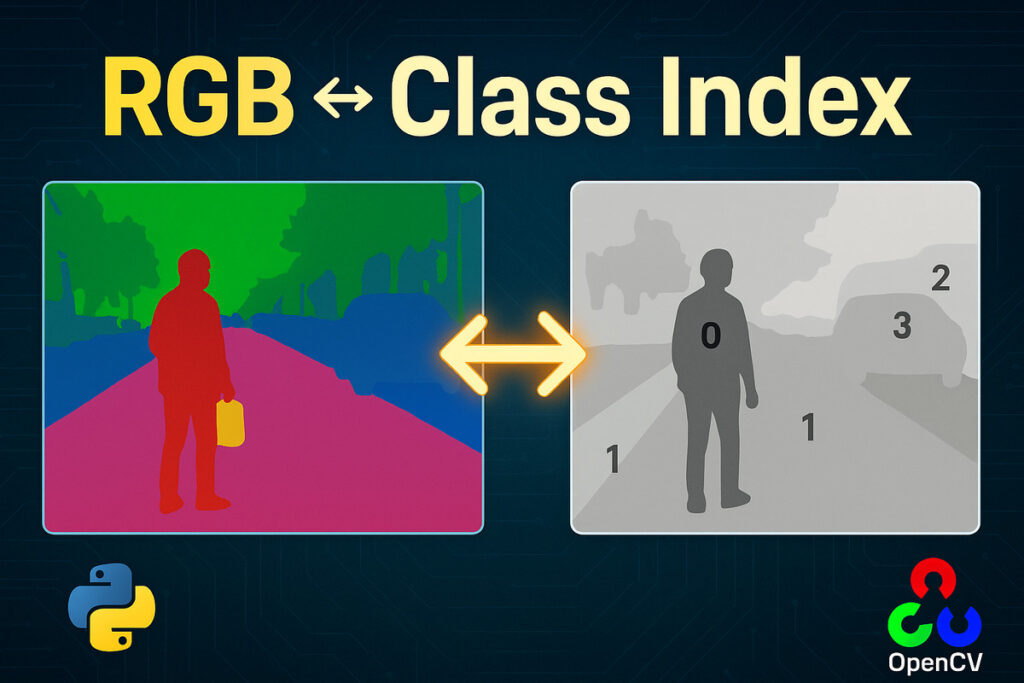
In the world of semantic segmentation, each pixel in an image carries a meaning — a class label that represents an object or region. These labels can be stored in various formats, and one common way is using a multi-class RGB mask, where each class is represented by a unique Continue Reading
Extracting RGB Codes from Multi-Class Segmentation Masks with Python

Imagine you’re training a deep learning model for multi-class segmentation, and you have a bunch of segmentation masks where a unique RGB color represents each class (like sky, road, car, etc.). But here’s the catch — how do you know what RGB codes are being used? What if you need Continue Reading
ViTPose: Human Pose Estimation with (ViT) Vision Transformers
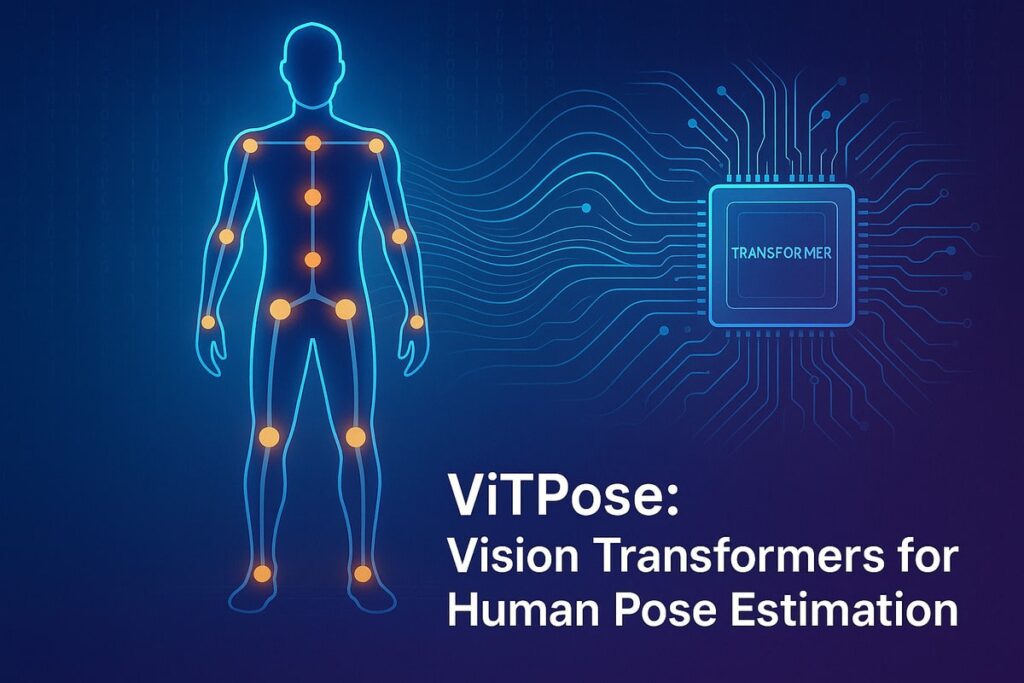
Human pose estimation is one of the most critical tasks in computer vision. It aims to localize anatomical key points (like shoulders, knees, and wrists) on the human body. Traditional convolutional neural networks (CNNs) have long dominated this field, but a new horizon has emerged with the advent of transformers Continue Reading
YOLO: From Real-Time to State-of-the-Art Object Detection
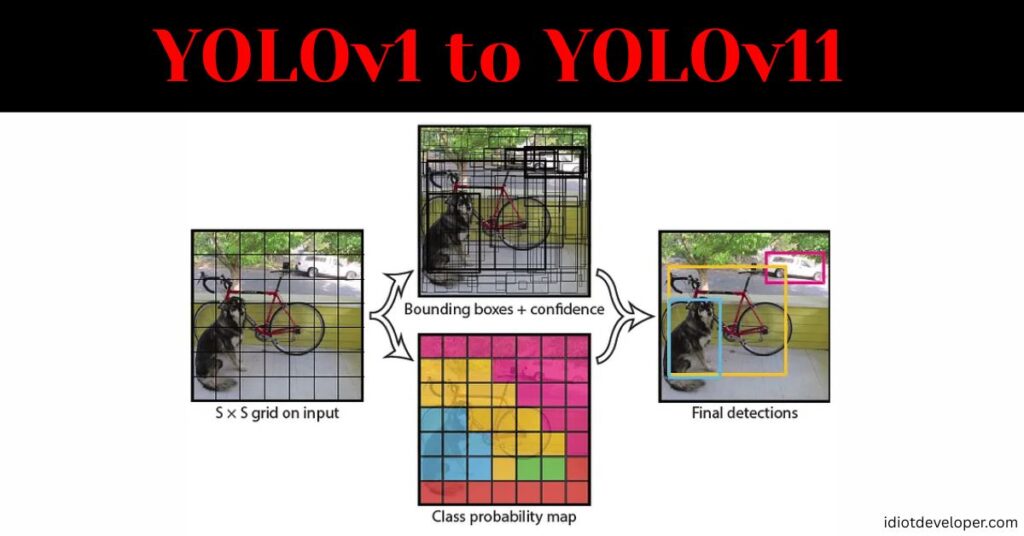
The You Only Look Once (YOLO) series has revolutionized object detection since its inception in 2015. Developed initially by Joseph Redmon and colleagues, YOLO redefined speed and efficiency in computer vision by transforming detection into a single regression problem. Unlike earlier two-stage detectors (e.g., R-CNN), which required multiple passes over Continue Reading
GradCAM and its Implementation in PyTorch

Deep learning models, especially convolutional neural networks (CNNs), often function as black boxes, making it difficult to interpret their decision-making processes. Gradient-weighted Class Activation Mapping (GradCAM) is a powerful technique used to visualize and understand these models by highlighting the regions of an image that contribute most to a prediction. Continue Reading