
Large language models (LLMs) have come to dominate natural‑language AI, and a new generation—Large Reasoning Models (LRMs)—now claims to “think” via extended chain‑of‑thought (CoT) outputs. But is this genuine reasoning or merely a high‑tech parlor trick? In their paper “The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Continue Reading
Deep Learning
Converting RGB Mask to Class Index Masks in Python
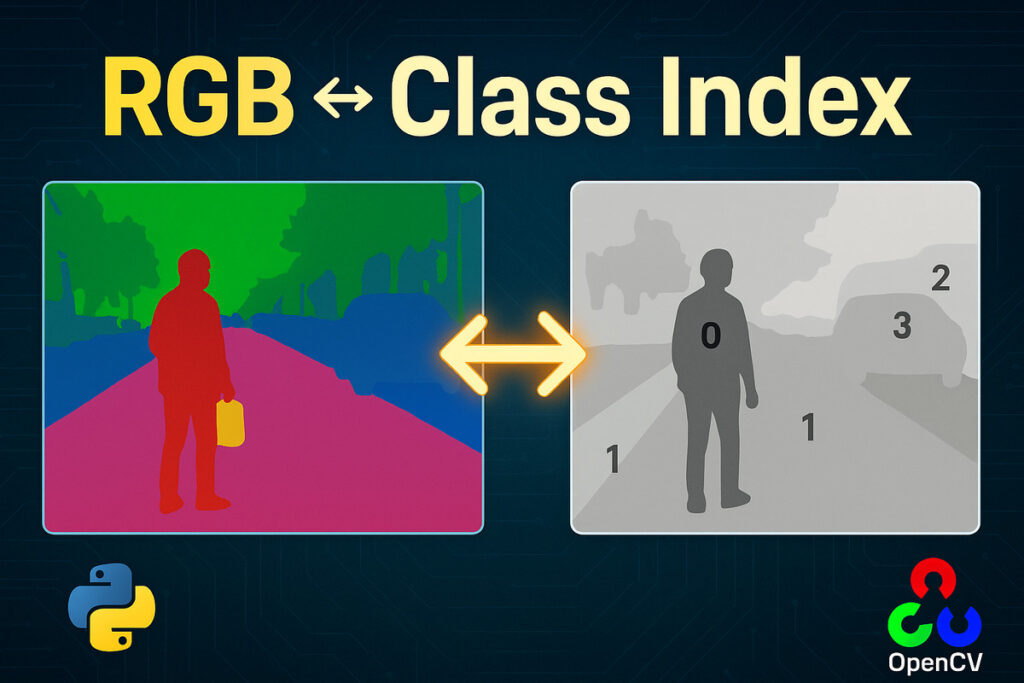
In the world of semantic segmentation, each pixel in an image carries a meaning — a class label that represents an object or region. These labels can be stored in various formats, and one common way is using a multi-class RGB mask, where each class is represented by a unique Continue Reading
Extracting RGB Codes from Multi-Class Segmentation Masks with Python

Imagine you’re training a deep learning model for multi-class segmentation, and you have a bunch of segmentation masks where a unique RGB color represents each class (like sky, road, car, etc.). But here’s the catch — how do you know what RGB codes are being used? What if you need Continue Reading
ViTPose: Human Pose Estimation with (ViT) Vision Transformers
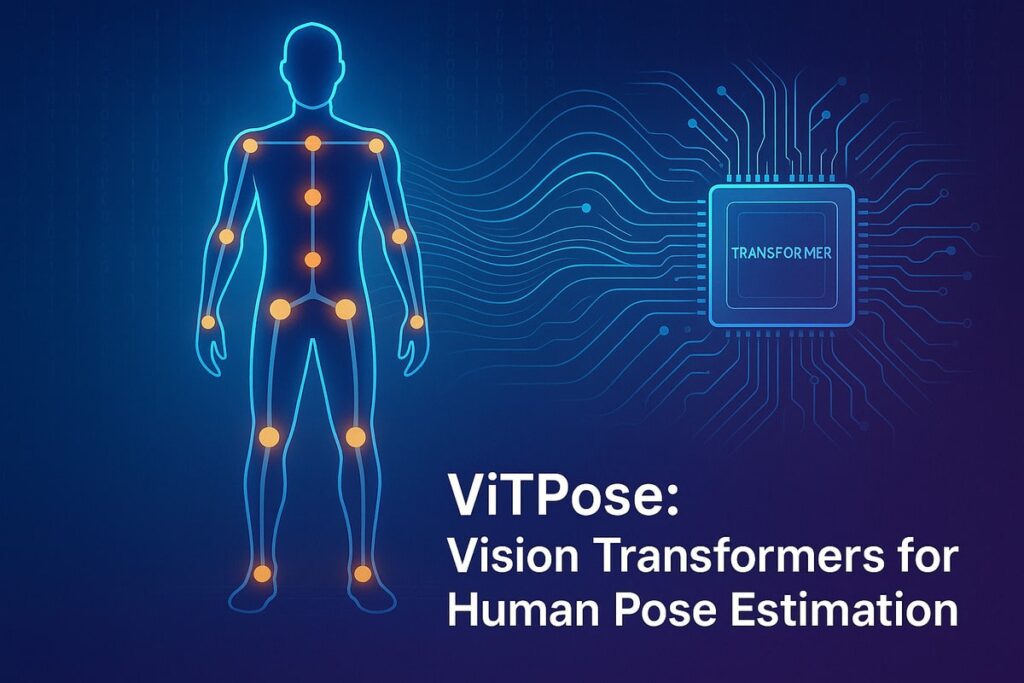
Human pose estimation is one of the most critical tasks in computer vision. It aims to localize anatomical key points (like shoulders, knees, and wrists) on the human body. Traditional convolutional neural networks (CNNs) have long dominated this field, but a new horizon has emerged with the advent of transformers Continue Reading
YOLO: From Real-Time to State-of-the-Art Object Detection
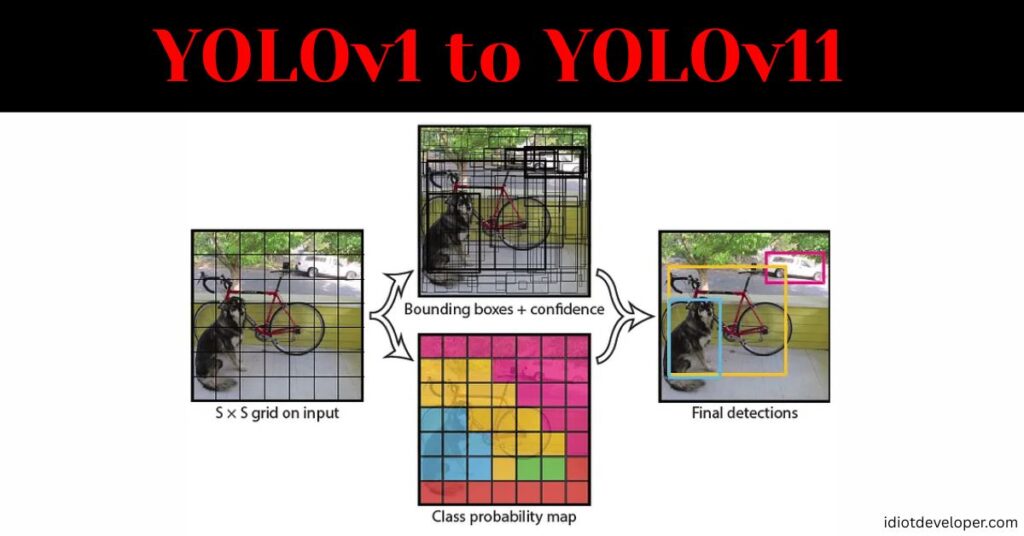
The You Only Look Once (YOLO) series has revolutionized object detection since its inception in 2015. Developed initially by Joseph Redmon and colleagues, YOLO redefined speed and efficiency in computer vision by transforming detection into a single regression problem. Unlike earlier two-stage detectors (e.g., R-CNN), which required multiple passes over Continue Reading
Automating Generative AI Optimization with TextGrad: A Breakthrough in AI System Refinement

TextGrad is revolutionizing AI optimization by automating system refinement using natural language feedback. AI systems now rely on multiple large language models (LLMs) and external tools for complex tasks. Traditionally, optimizing these systems required manual tuning, making the process slow and inefficient. TextGrad eliminates this bottleneck by introducing an automated Continue Reading
GradCAM and its Implementation in PyTorch

Deep learning models, especially convolutional neural networks (CNNs), often function as black boxes, making it difficult to interpret their decision-making processes. Gradient-weighted Class Activation Mapping (GradCAM) is a powerful technique used to visualize and understand these models by highlighting the regions of an image that contribute most to a prediction. Continue Reading
Visual Question Answering from Scratch using TensorFlow
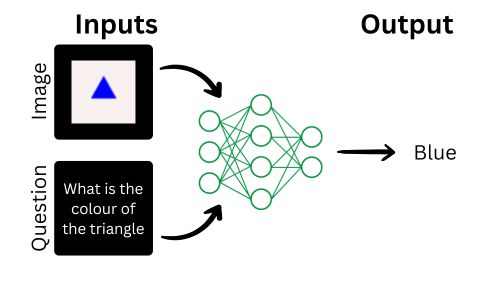
Visual Question Answering (VQA) is a fascinating field in artificial intelligence where a system answers questions about an image. This combines natural language processing (NLP) to understand the question and computer vision to analyze the image. For example, given an image of a red apple and the question “What color Continue Reading
Key Components of Large Language Models (LLMs)

Large Language Models (LLMs) have become the backbone of modern Natural Language Processing (NLP), pushing the boundaries of tasks like text generation, summarization, machine translation, and question-answering. These models are designed to process vast amounts of textual data, enabling them to generate human-like responses. The core strength of LLMs lies Continue Reading
[Paper Summary] EMCAD: Efficient Multi-scale Convolutional Attention Decoding for Medical Image Segmentation
![[Paper Summary] EMCAD: Efficient Multi-scale Convolutional Attention Decoding for Medical Image Segmentation](https://idiotdeveloper.com/wp-content/uploads/2024/09/Paper-Summary-EMCAD-Efficient-Multi-scale-Convolutional-Attention-Decoding-for-Medical-Image-Segmentation-1024x536.jpg)
This post will analyze the research paper “EMCAD: Efficient Multi-scale Convolutional Attention Decoding for Medical Image Segmentation.” We will discuss the problems with existing medical image segmentation methods and how the given method (EMCAD) solves these issues. What is EMCAD? EMCAD is a newly developed efficient multi-scale convolutional attention decoder Continue Reading