
Recent advancement in the field of deep learning has enabled us to develop models that yield impressive results across various fields, from image classification, object detection, to speech recognition. However, developing the architecture for each problem is a challenge in itself. In this paper, the authors present a single deep model or architecture that efficiently works well on many domains, including language translation, image classification, and speech recognition. Instead of using a single model, the authors use a modular approach to accomplish this task. In the paper, it is referred to as the MultiModel.
Multi-task models have been studied in many papers in the past couple of years, but they are generally used within the same domain. For example, language translation tasks are trained with other translation tasks, vision tasks with other vision tasks, speech tasks with other speech tasks. Natural language processing has also shown promising results using multi-task learning. Multi-model learning improves learned representations in an unsupervised manner and which benefits other tasks from the same domain. Till now no model has been trained on the dataset from different domains and have been able to achieve promising results across multiple tasks.
Outline
- Architecture
- Dataset
- Experiment
- Conclusion
Architecture
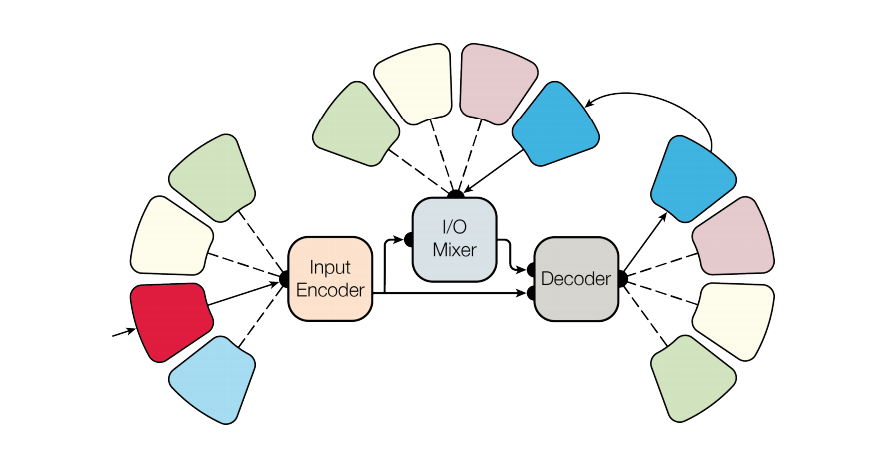
The architecture of the MultiModel consists of the following parts:
- Encoder: The encoder is designed to process the inputs from the different domains into a single representation.
- Input/Output (I/O) Mixer: The input/output mixer is used to mix the encoded inputs with the previous outputs from the auto-regressive part i.e., from the output of the decoder.
- Decoder: The decoder is an auto-regressive part that processes the input and the output from the Input/Output Mixer.
The encoder and the decoder are designed using the three main computational blocks, which helps to achieve the desired outcome:
- Convolution: It allows the encoder and decoder to detect and generalize patterns across the input feature maps and to transform the encoded input feature maps into a new output that consists of the previously accumulated features.
- Attention: The attention allows you to focus on the most important elements of the input feature maps and produce an output that is specific to your domain. This helps to achieve high performance and ensure the desired quality of the result.
- Sparsely-Gated Mixtures-of-Experts: Mixtures-of-Experts are special types of neural network that consists of a large number of sub-networks, where each sub-network is only active under special circumstances. Lower layers of the network extract features and experts are called upon to evaluate those features — for each case, only some of the experts are called upon. It gives the model capacity without excessive computation cost.
Modality Nets:
As we are using the dataset from different domains to train the MultiModel, we need to take care of the input data size and dimensionality. We need sub-networks to process the different inputs such as images, sound waves, etc, into a joint representation space. These sub-networks are known as Modality Nets.
These modality nets act like specialized experts to extract features from a specific domain. They help the encoder in mapping each input into a unified representation which is then mixed with the previous output by the Input/Output Mixer and then the result is sent to the auto-regressive decoder to compute the final output.
There are different modality nets which are used by the MultiModel which are:
- Language
- Image
- Categorical
- Audio
Dataset
The MultiModel was trained simultaneously on the following 8 datasets:
- WSJ speech corpus
- ImageNet dataset
- COCO image captioning dataset
- WSJ parsing dataset
- WMT English-German translation corpus
- The reverse of the above: German-English translation.
- WMT English-French translation corpus
- The reverse of the above: German-French translation.

language modality while blue depicts a categorical modality.
Experiment
The MultiModel was implemented in TensorFlow and is trained with several configurations to get the most efficient implementation. All the experiments use the same set of hyperparameters which include Adam optimizer with gradient clipping.

Conclusion
The approach is similar to the working of a biological brain as an analogy. As the brain uses a wide variety of input like sight, smell, touch, etc from different senses and sends it the specialized areas of the brain for the processing. Similarly, the MultiModel uses inputs from various modalities which are processed by modality nets and then passed through the sparsely gated mixture of models that selects the best experts that can process that input. The I/O mixer acts like a feedback (recurrent) connection that mixes the outputs from the decoder and encoded inputs. This is analogous to the way we can monitor our own actions. Its powerful transfer learning capabilities help that model to perform well on task with less training data since we are using data from different domains.
Modular approaches are one of the best way toward more intelligent systems.




