In this article, we will study the ResUNet++ architecture and implement it using the TensorFlow framework. ResUNet++ is a medical image segmentation architecture built upon the ResUNet architecture. It takes advantage of Residual Networks, Squeeze and Excitation blocks, Atrous Spatial Pyramidal Pooling (ASPP), and attention blocks.
What is ResUNet++?
Debesh Jha and the team developed the architecture in 2019 and published it in the 21st IEEE International Symposium on Multimedia (ISM). The paper was cited 856 times.
According to the author:
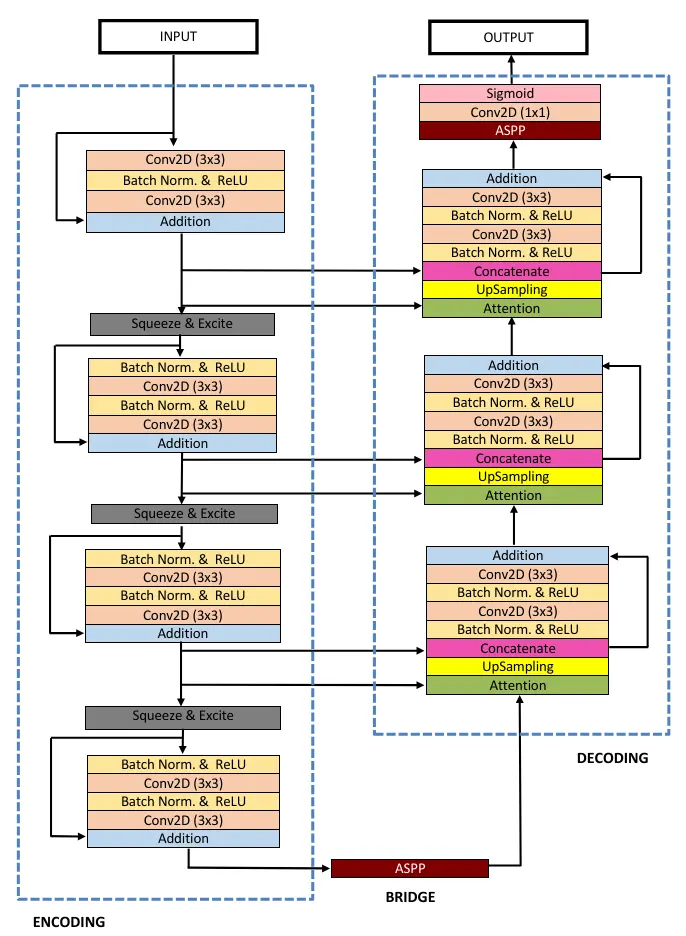
The ResUNet++ architecture is based on the Deep Residual U-Net (ResUNet) [6], which is an architecture that uses the strength of deep residual learning [24] and U-Net [5]. The proposed ResUNet++ architecture takes advantage of the residual blocks, the squeeze and excitation block, ASPP, and the attention block.
RESEARCH PAPER: ResUNet++: An Advanced Architecture for Medical Image Segmentation
ResUNet++ Implementation
Let’s begin by implementing ResUNet++ using the TensorFlow framework.
Step 1: Import Library
import tensorflow as tf
import tensorflow.keras.layers as L
from tensorflow.keras.models import Model
Step 2: Squeeze and Excitation Block
Now, we will implement the channel-wise attention mechanism called Squeeze and Excitation Block.
To improve their channel interdependencies, the Squeeze and Excitation Network introduces a novel channel-wise attention mechanism for CNNs (Convolutional Neural Networks). The network adds a parameter that re-weights each channel accordingly to become more sensitive to significant features while ignoring irrelevant ones.
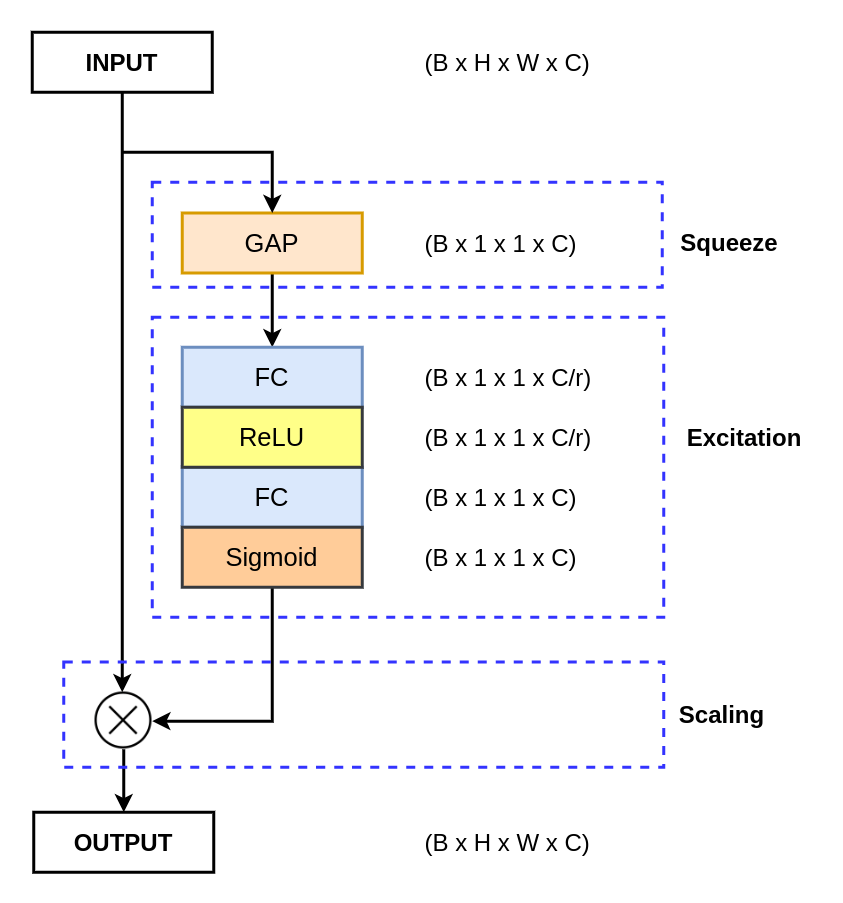
The convolution operator generates a feature map with a different number of channels, treating all the channels equally. This means that every single channel is equally important, and this may not be the best way. The Squeeze and Excitation attention mechanism adds a parameter to each channel that rescales them independently.
def SE(inputs, ratio=8):
channel_axis = -1
num_filters = inputs.shape[channel_axis]
se_shape = (1, 1, num_filters)
x = L.GlobalAveragePooling2D()(inputs)
x = L.Reshape(se_shape)(x)
x = L.Dense(num_filters // ratio, activation='relu', use_bias=False)(x)
x = L.Dense(num_filters, activation='sigmoid', use_bias=False)(x)
x = L.Multiply()([inputs, x])
return x
Step 3: Stem Block
The stem block is basically the first encoder block of the ResUNet++.
It begins with a 3×3 convolution layer, followed by a batch normalization and ReLU activation function. Then, it was followed again by a 3×3 convolution layer and a shortcut connection consisting of a 1×1 convolution layer with batch normalization.
At last, it is followed by the squeeze and excitation attention mechanism to improve the features.
def stem_block(inputs, num_filters, strides=1):
## Conv 1
x = L.Conv2D(num_filters, 3, padding="same", strides=strides)(inputs)
x = L.BatchNormalization()(x)
x = L.Activation("relu")(x)
x = L.Conv2D(num_filters, 3, padding="same")(x)
## Shortcut
s = L.Conv2D(num_filters, 1, padding="same", strides=strides)(inputs)
s = L.BatchNormalization()(s)
## Add
x = L.Add()([x, s])
x = SE(x)
return x
Step 4: ResNet Block
The resnet block is used in both the encoder and decoder parts of the network, and it follows a pre-residual activation.
It begins with batch normalization, ReLU, and a 3×3 convolutional layer. The same set of layers is repeated again. The output of this layer is then added with a shortcut connection consisting of a 1×1 convolution layer with batch normalization.
Similar to stem block, it is also followed by a squeeze and excitation mechanism.
def resnet_block(inputs, num_filter, strides=1):
## Conv 1
x = L.BatchNormalization()(inputs)
x = L.Activation("relu")(x)
x = L.Conv2D(num_filter, 3, padding="same", strides=strides)(x)
## Conv 2
x = L.BatchNormalization()(x)
x = L.Activation("relu")(x)
x = L.Conv2D(num_filter, 3, padding="same", strides=1)(x)
## Shortcut
s = L.Conv2D(num_filter, 1, padding="same", strides=strides)(inputs)
s = L.BatchNormalization()(s)
## Add
x = L.Add()([x, s])
x = SE(x)
return x
Step 5: ASPP Block
The Atrous Spatial Pyramidal Pooling (ASPP) block adds dilated convolution to the network. These dilated convolutional layers help to increase the receptive field of the convolutional kernel, thereby capturing features at different scales.
ASPP is utilized in two places: first, at the end of the encoder, i.e., between the encoder and decoder network, and second, at the end of the decoder network.
def aspp_block(inputs, num_filters):
x1 = L.Conv2D(num_filters, 3, dilation_rate=6, padding="same")(inputs)
x1 = L.BatchNormalization()(x1)
x2 = L.Conv2D(num_filters, 3, dilation_rate=12, padding="same")(inputs)
x2 = L.BatchNormalization()(x2)
x3 = L.Conv2D(num_filters, 3, dilation_rate=18, padding="same")(inputs)
x3 = L.BatchNormalization()(x3)
x4 = L.Conv2D(num_filters, (3, 3), padding="same")(inputs)
x4 = L.BatchNormalization()(x4)
y = L.Add()([x1, x2, x3, x4])
y = L.Conv2D(num_filters, 1, padding="same")(y)
return y
Step 6: Attention Block
The attention block is used in the decoder part of ResUNet++. It provides spatial attention to features using the skip connection features from the encoder, helping to enhance feature representation.
def attetion_block(x1, x2):
num_filters = x2.shape[-1]
x1_conv = L.BatchNormalization()(x1)
x1_conv = L.Activation("relu")(x1_conv)
x1_conv = L.Conv2D(num_filters, 3, padding="same")(x1_conv)
x1_pool = L.MaxPooling2D((2, 2))(x1_conv)
x2_conv = L.BatchNormalization()(x2)
x2_conv = L.Activation("relu")(x2_conv)
x2_conv = L.Conv2D(num_filters, 3, padding="same")(x2_conv)
x = L.Add()([x1_pool, x2_conv])
x = L.BatchNormalization()(x)
x = L.Activation("relu")(x)
x = L.Conv2D(num_filters, 3, padding="same")(x)
x = L.Multiply()([x, x2])
return x
Step 7: ResUNet++
We have implemented various blocks related to ResUNet++ to date. Now, we will implement the ResUNet++ architecture.
def resunet_pp(input_shape):
""" Inputs """
inputs = L.Input(input_shape)
""" Encoder """
c1 = stem_block(inputs, 16, strides=1)
c2 = resnet_block(c1, 32, strides=2)
c3 = resnet_block(c2, 64, strides=2)
c4 = resnet_block(c3, 128, strides=2)
""" Bridge """
b1 = aspp_block(c4, 256)
""" Decoder """
d1 = attetion_block(c3, b1)
d1 = L.UpSampling2D((2, 2))(d1)
d1 = L.Concatenate()([d1, c3])
d1 = resnet_block(d1, 128)
d2 = attetion_block(c2, d1)
d2 = L.UpSampling2D((2, 2))(d2)
d2 = L.Concatenate()([d2, c2])
d2 = resnet_block(d2, 64)
d3 = attetion_block(c1, d2)
d3 = L.UpSampling2D((2, 2))(d3)
d3 = L.Concatenate()([d3, c1])
d3 = resnet_block(d3, 32)
""" Output"""
outputs = aspp_block(d3, 16)
outputs = L.Conv2D(1, 1, padding="same")(outputs)
outputs = L.Activation("sigmoid")(outputs)
""" Model """
model = Model(inputs, outputs)
return model
Decoder Block: The decoder block is used for upsampling the feature from the previous block and learning how to generate the semantic feature representation to generate a required segmentation mask.
The decoder block begins with an attention block, followed by an upsampling block. Next, the upsampled feature is concatenated with the feature from the encoder, i.e., a skip connection. At last, we have a resnet block.
Summary and Conclusion
In this article, we have explained and implemented the ResUNet++ architecture and its blocks. We provided a detailed explanation of each block along with the complete ResUNet++.
If you have any doubts, thoughts, or suggestions, please leave them in the comment section. I will surely address them.
You can contact me using the Contact section. You can also find me on:
Read More




