
Image segmentation is an important area of computer vision that involves dividing an image into multiple segments, each of which corresponds to a different object. Background removal is one of the crucial applications of image segmentation that involves separating foreground objects from the background. This can be useful in various Continue Reading
Computer Vision
Exploring Bounding Boxes and Different Annotation Formats in Object Detection

Bounding boxes play a critical role in the object detection process, a fundamental task in computer vision. Object detection entails the identification and precise localization of objects within an image. These bounding boxes serve to define the position of an object within the image, allowing for the creation of a Continue Reading
What is MultiResUNET?

MultiResUNET is an architecture developed by Nabil Ibtehaz et al. for the purpose of multimodal biomedical image segmentation at the Bangladesh University of Engineering and Technology. It is an improvement over the existing UNET architecture as it outperforms U-Net on the five biomedical datasets. The high performance of MultiResUNET is Continue Reading
What is Intersection over Union (IoU) in Object Detection?
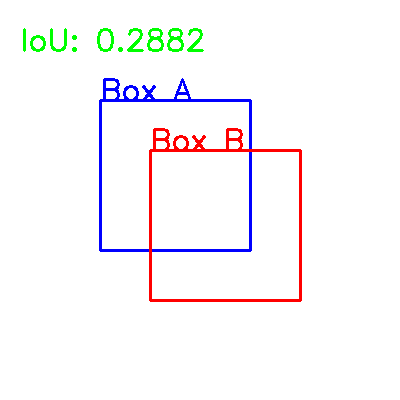
Intersection over Union (IoU) is a popular evaluation metric used in the field of computer vision and object detection. It is used to calculate the overlap between two bounding boxes and is used to evaluate the accuracy of object detection algorithms. IoU is a value between 0 and 1 that Continue Reading
Human Face Detection using Multi-task Cascaded Convolutional Networks in TensorFlow

In recent years, advances in machine learning and deep learning techniques have revolutionized the field of computer vision. With the help of these techniques, we can now detect and identify objects in real time with remarkable accuracy. One of the most popular tasks in computer vision is human face detection, Continue Reading
Human Face Landmark Detection in TensorFlow using Pre-trained MobileNetv2

Today, in this blog post, we will learn how to train a Convolutional Neural Network (CNN) to detect human facial landmarks, such as eyes, mouth, nose, jawline and more. We will use the pre-trained MobileNetv2 from TensorFlow to build our model and then train it on Landmark Guided Face Parsing Continue Reading
What is MobileViT?

This article covers an overall summary of the MobileViT: Light-Weight, General-Purpose, and Mobile-Friendly Vision Transformers research paper. MobileViT is a lightweight and general-purpose vision transformer for mobile vision tasks. It combines the strength of the standard CNN (Convolutional Neural Network) and the Vision Transformers. It has outperformed several CNNs and Continue Reading
Vision Transformer – An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale

In this blog post, we are going to learn about the Vision Transformer (ViT). It is a pure Transformer based architecture used for image classification tasks. Vision Transformer (ViT) has the ability to replace the standard CNNs while achieving excellent results. The Vision Transformer (ViT) attains excellent results when pre-trained Continue Reading
MODNet: Real-Time Trimap-Free Portrait Matting via Objective Decomposition
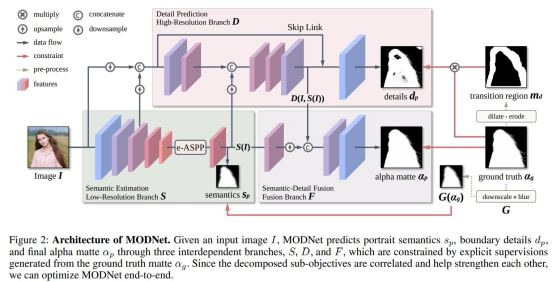
In this work, we present a lightweight matting objective decomposition network (MODNet) for portrait matting in real-time with a single input image. MODNet inputs a single RGB image and applies explicit constraints to solve matting sub-objectives simultaneously in one stage. The research paper is accepted at AAAI 2022 conference. Research Continue Reading
VGG19 UNET Implementation in TensorFlow

In this tutorial, we are going to implement the U-Net architecture in TensorFlow, where we will replace its encoder with a pre-trained VGG19 architecture. The VGG19 is already trained on the ImageNet classification dataset. Therefore, it would have already learned the required features, which would help to boost the overall Continue Reading