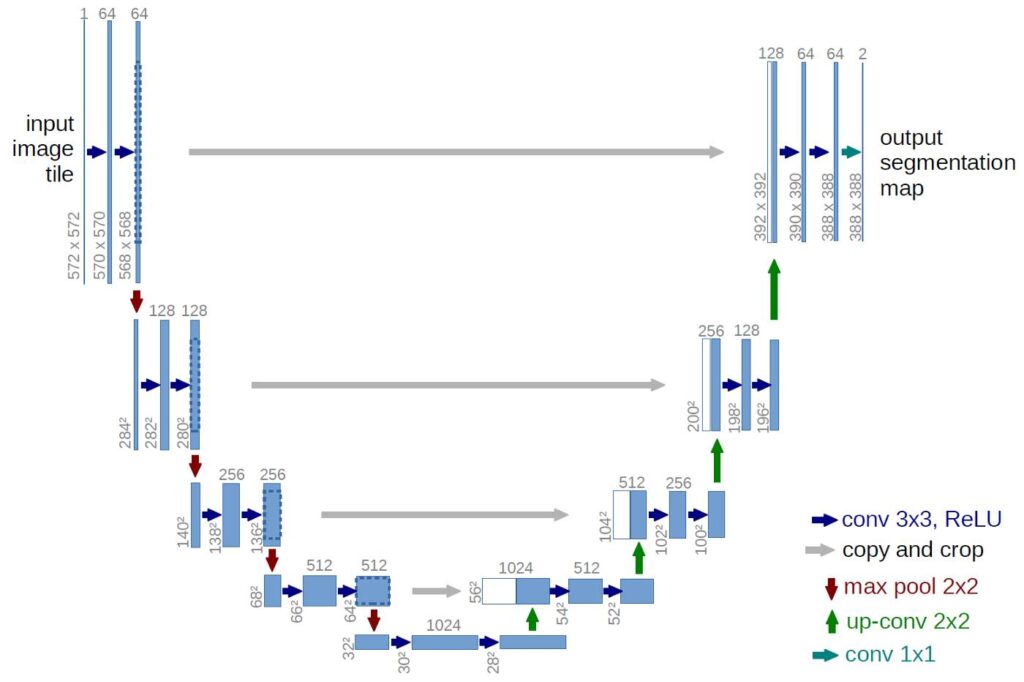
Semantic segmentation, a crucial task in computer vision, plays a pivotal role in various applications such as medical image analysis, autonomous driving, and object recognition. In this tutorial, we will delve into the implementation of ResNet50 UNET using TensorFlow – a powerful combination that leverages the strengths of both the Continue Reading
Computer Vision
What is Conditional DCGAN

Generative Adversarial Networks (GANs) have revolutionized the field of artificial intelligence by introducing a powerful framework for generating realistic data. Among various GAN architectures, Deep Convolutional Generative Adversarial Networks (DCGANs) have gained significant popularity due to their ability to generate high-resolution images. In this article, we delve into the realm Continue Reading
Anime Face Generation with Deep Convolutional GANs (DCGAN)

Generative Adversarial Networks (GANs) have revolutionized the field of artificial intelligence, enabling the creation of realistic images from scratch. In this tutorial, we’ll dive into the implementation of a Deep Convolutional Generative Adversarial Network (DCGAN) specifically designed for generating Anime faces. Whether you’re a coding enthusiast or an anime aficionado, Continue Reading
What is Deep Convolutional Generative Adversarial Networks (DCGANs)
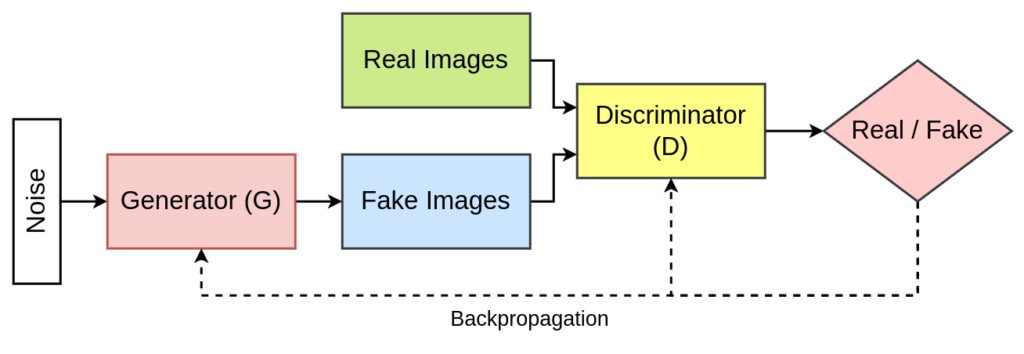
In the realm of generative models, the emergence of Deep Convolutional Generative Adversarial Networks (DCGAN) has marked a significant breakthrough. DCGAN represent an evolution of the traditional Generative Adversarial Networks (GAN), enhancing their capabilities in generating high-quality, realistic images. What is DCGAN? DCGANs are a class of neural networks that Continue Reading
Conditional GAN in TensorFlow

In this tutorial, we will implement the Conditional GAN (Generative Adversarial Network) in TensorFlow using Keras API. For this purpose, we will use the Shoe vs Sandal vs Boot Image dataset. What is Conditional GAN Conditional GAN, known as cGAN, is an extension of the traditional GAN framework introduced by Continue Reading
What is a Conditional GAN: Unleashing the Power of Context in Generative Models
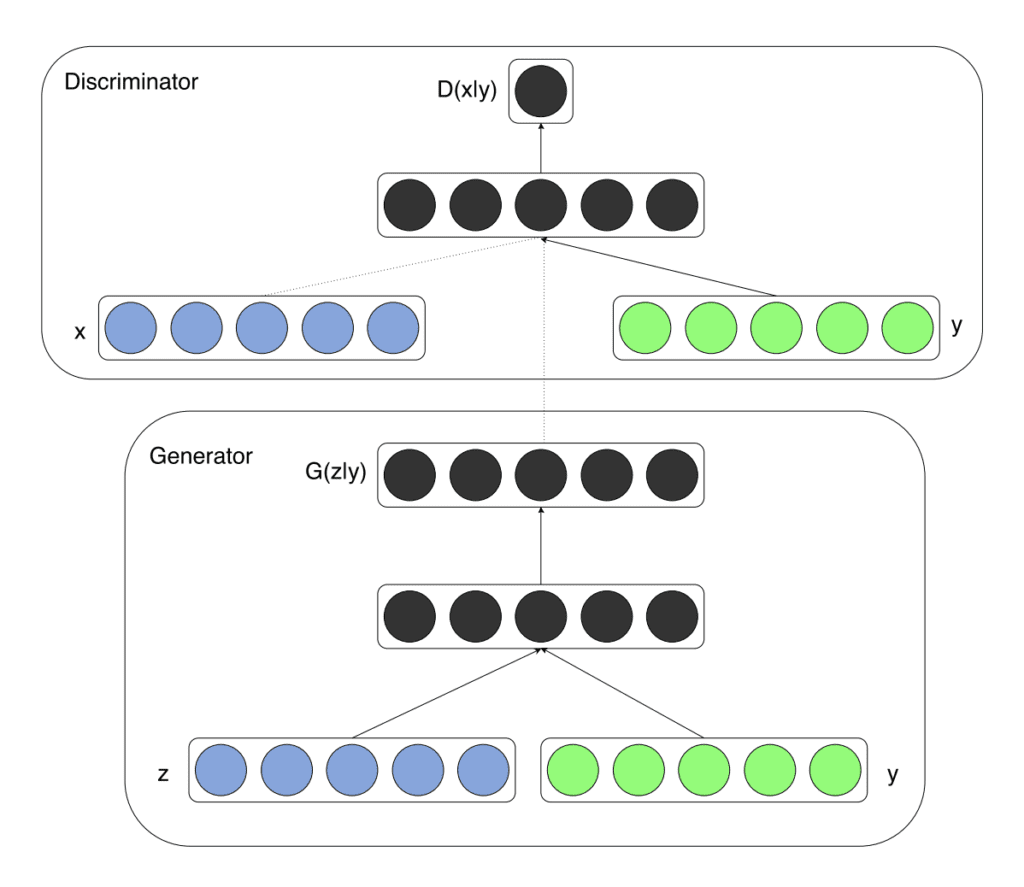
In the rapidly evolving landscape of artificial intelligence and machine learning, Generative Adversarial Networks (GANs) have emerged as a revolutionary approach to generating data that mimics real-world distributions. One intriguing development within this realm is the Conditional GAN, an extension of the classic GAN architecture that introduces the concept of Continue Reading
Vanilla GAN in TensorFlow

This tutorial will teach you how to implement basic Generative Adversarial Networks (GANs) in TensorFlow using Keras API. For this purpose, we will utilize the Anime Face Dataset and try to generate realistic anime faces. What is GAN GAN stands for Generative Adversarial Network, a framework in which two neural Continue Reading
Attention UNET in PyTorch
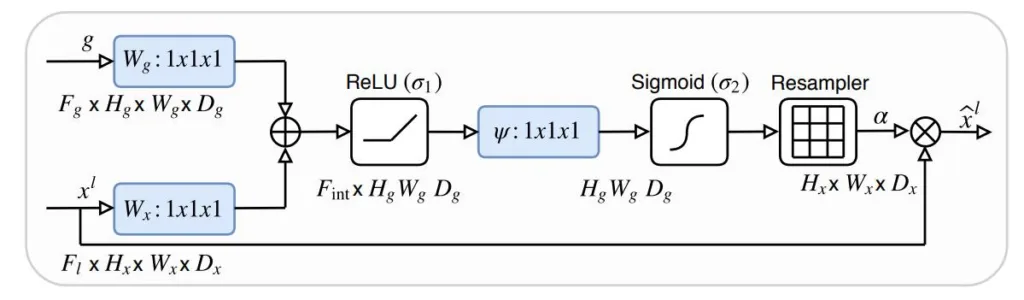
In this article, we are going to learn about the Attention UNET and then implement it in the PyTorch framework. Attention UNET is a type of Convolutional Neural Network (CNN) that is commonly used for image segmentation tasks. It is an extension of the original U-Net architecture, which was proposed Continue Reading
Attention UNET and its Implementation in TensorFlow
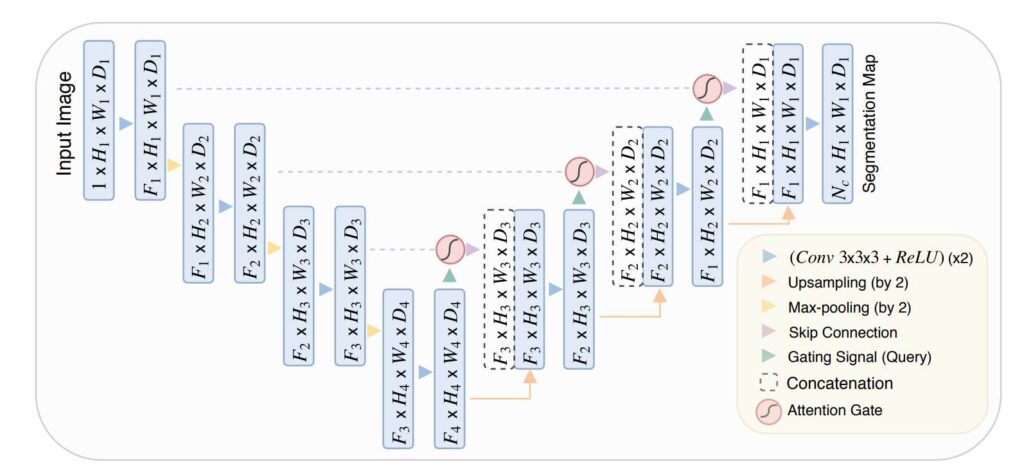
In the article, we will go through the paper Attention U-Net: Learning Where to Look for the Pancreas. It was written by Ozan Oktay et. al in the year 2018 at the MIDL (Medical Imaging with Deep Learning) conference. The Attention UNET introduces a novel Attention Gate that enables the Continue Reading
DeepLabV3+ ResNet50 Architecture in TensorFlow using Keras
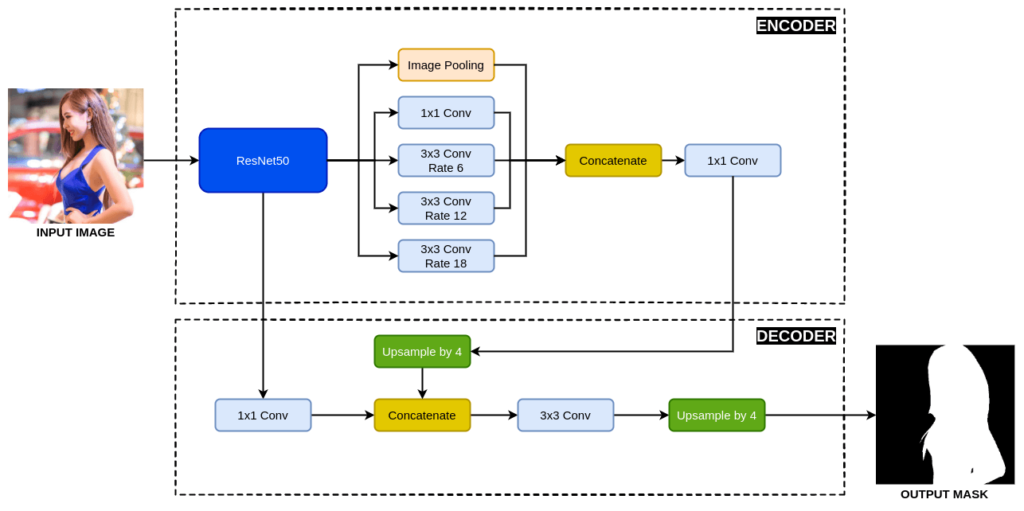
In today’s tutorial, we will be looking at the DeepLabV3+ (ResNet50) architecture implementation in TensorFlow using Keras high-level API. Within this architecture, ResNet50 would be used as the encoder, which is pre-trained on the ImageNet classification dataset. We will begin with the overall architectural understanding of the DeepLabV3+ and ResNet50. Continue Reading