In the ever-evolving landscape of computer vision and medical imaging, achieving real-time performance in segmentation tasks is crucial. ColonSegNet, a novel encoder-decoder architecture, has emerged as a beacon of efficiency, designed for swift and accurate colon polyp segmentation. In this blog post, we’ll delve into the intricacies of ColonSegNet’s architecture and explore why it stands out among other baseline networks.

Research Paper: Real-Time Polyp Detection, Localization and Segmentation in Colonoscopy Using Deep Learning
Architectural Highlights
ColonSegNet adopts an encoder-decoder structure, employing residual blocks with a squeeze and excitation network as its cornerstone. The primary objective is to minimize the number of trainable parameters, setting it apart from conventional networks such as U-Net, PSPNet, and DeepLabV3+.
Encoder Network
The network comprises two encoder blocks, each contributing to extracting essential information from the input image. The first encoder incorporates two residual blocks separated by a 3×3 strided convolution, followed by a 2×2 max-pooling. This strategic design reduces the spatial dimensions of the output feature map to 1/4 of the input image. The second encoder mirrors this structure, reinforcing the network’s ability to capture intricate details.
Residual Block
The residual blocks within ColonSegNet are the building blocks that enable the model to capture intricate features within the colon images. These blocks consist of convolutional layers, batch normalization, and activation functions, allowing the model to learn and retain important details.

The residual block consists of two 3×3 convolution layers, each followed by a batch normalization and a ReLU activation function is added between them. Next, we have a 1×1 convolution layer with batch normalization and Squeeze and Excitation attention mechanism. The output of the attention mechanism is added to the output of the main branch and followed by the ReLU activation function.
Squeeze and Excitation Attention Mechanism
The Squeeze and Excitation Network introduces a novel channel-wise attention mechanism for CNNs (Convolutional Neural Networks) to improve their channel interdependencies. The network adds a parameter that re-weights each channel accordingly so that it becomes more sensitive towards significant features while ignoring the irrelevant features.
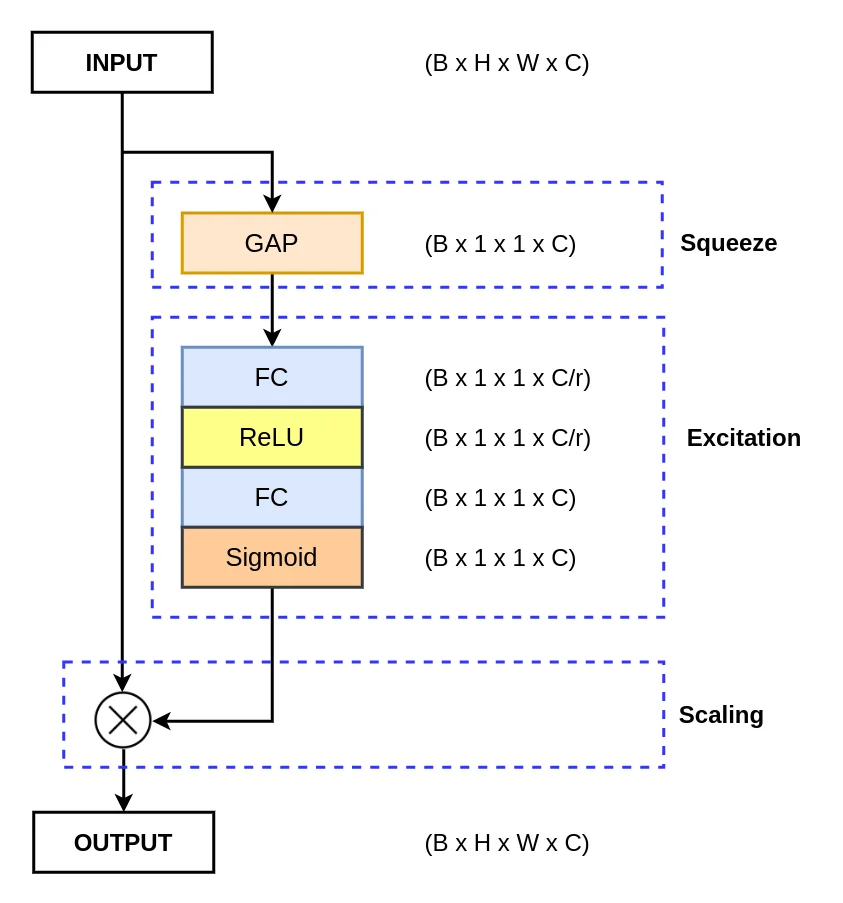
The Squeeze and Excitation basically act as a content-aware mechanism that re-weights each channel adaptively.
Read More: Squeeze and Excitation Networks
Decoder Network
ColonSegNet’s decoder begins with a transpose convolution. The first decoder uses a stride value of 4, magnifying the feature map’s spatial dimensions by 4. Similarly, the second decoder utilizes a stride value of 2, increasing dimensions by 2. What sets ColonSegNet apart is its incorporation of skip connections from the encoder. The first connection involves a simple concatenation, while the second traverses a transpose convolution, integrating multi-scale features into the decoder.
Efficiency in Action
The careful orchestration of operations after skip connection concatenation includes a residual block. This thoughtful design choice contributes to the network’s efficiency. The final decoder block output undergoes a 1×1 convolution and a sigmoid activation function, culminating in the generation of a binary segmentation mask for the input image.
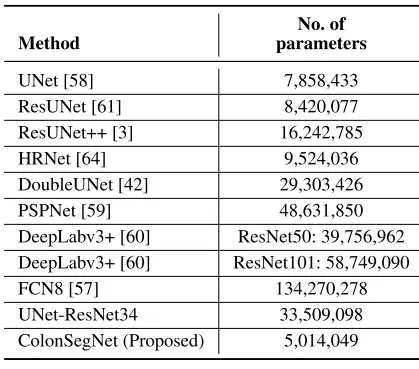
Results

Real-Time Application
ColonSegNet’s lightweight architecture positions it as an ideal candidate for real-time applications, particularly in colon segmentation. By minimizing trainable parameters, the network ensures swift and accurate results without compromising on semantic understanding.
Conclusion
ColonSegNet’s ingenious combination of residual blocks, squeeze and excitation network, and efficient skip connections marks a significant leap in real-time colon segmentation. As the demand for faster and more accurate medical imaging solutions continues to grow, architectures like ColonSegNet pave the way for a future where real-time performance is the norm rather than the exception.