
In recent posts, we’ve built a strong foundation around multiclass image segmentation using PyTorch. From creating segmentation masks, converting RGB to class index masks, overlaying results using OpenCV, to training a full-fledged UNet model and visualizing it with GradCAM, we’ve covered the full training pipeline. But what happens when your Continue Reading
opencv
Multiclass Segmentation in PyTorch using U-Net
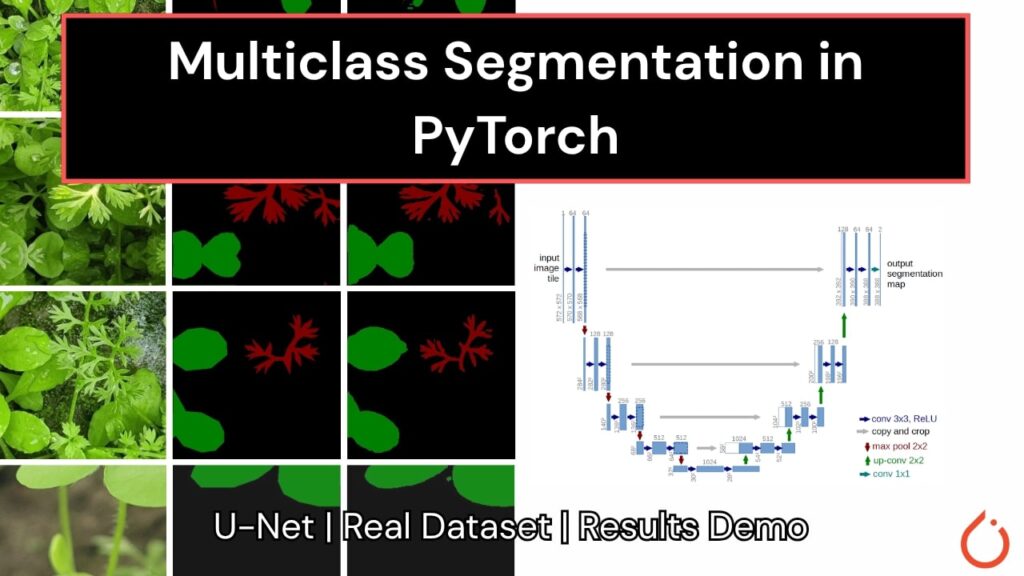
Semantic segmentation is a crucial task in computer vision that involves labeling each pixel in an image with its corresponding class. In this blog post, we’ll dive into building a multiclass semantic segmentation pipeline using the U-Net architecture with PyTorch. Our goal is to segment different types of weeds from Continue Reading
Overlay Mask on Image using OpenCV in Python

Overlaying a mask on top of an image is a common step in visualizing results from computer vision models, especially in tasks like semantic segmentation, object detection, and medical image analysis. This helps developers and researchers easily see which parts of the image the model has identified as belonging to Continue Reading
Converting RGB Mask to Class Index Masks in Python
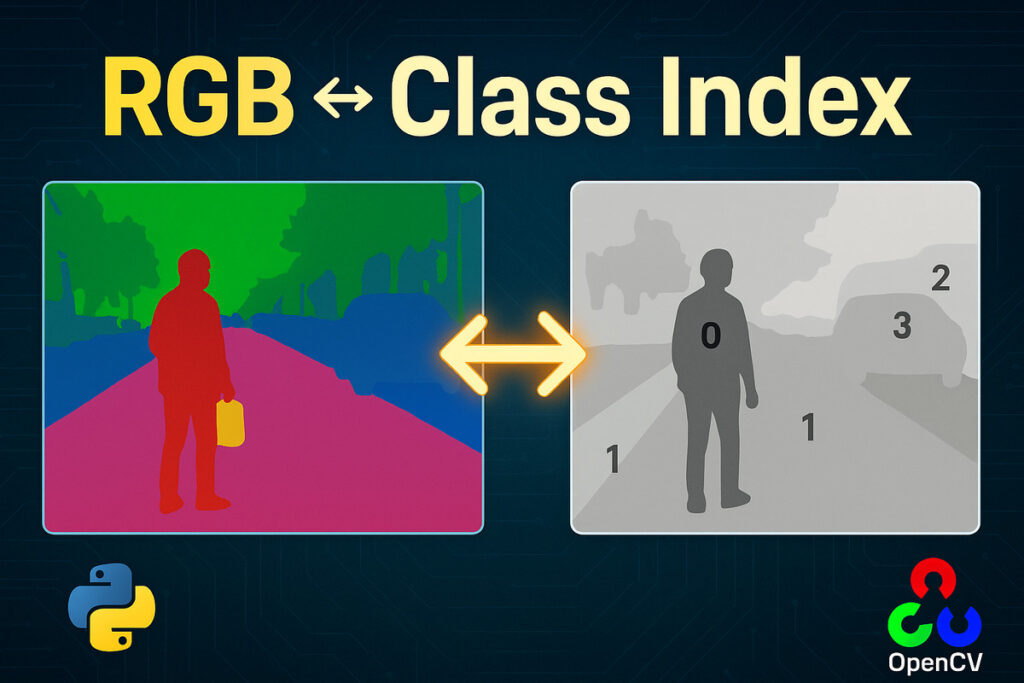
In the world of semantic segmentation, each pixel in an image carries a meaning — a class label that represents an object or region. These labels can be stored in various formats, and one common way is using a multi-class RGB mask, where each class is represented by a unique Continue Reading
GradCAM and its Implementation in PyTorch

Deep learning models, especially convolutional neural networks (CNNs), often function as black boxes, making it difficult to interpret their decision-making processes. Gradient-weighted Class Activation Mapping (GradCAM) is a powerful technique used to visualize and understand these models by highlighting the regions of an image that contribute most to a prediction. Continue Reading
GradCAM with TensorFlow: Interpreting Neural Networks with Class Activation Maps

Deep learning models, particularly convolutional neural networks (CNNs), are widely used for image classification, object detection, and various computer vision tasks. However, these models are often referred to as “black boxes” due to their complex decision-making processes. To interpret these decisions and understand what parts of an image influence the Continue Reading
Read Video Files Using OpenCV Python

Reading and processing video files is a common task in computer vision, and OpenCV makes it easy to work with video data. In this article, we’ll go through the process of reading and displaying video files using OpenCV. Whether you’re working on a video analysis project or want to learn Continue Reading
Image Masking with OpenCV AddWeighted
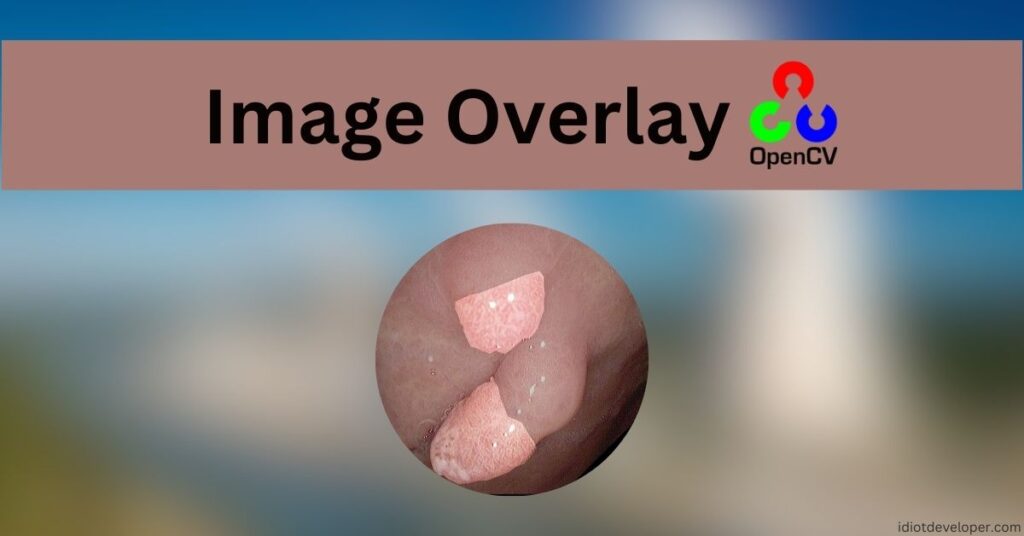
Image masking is a powerful technique used in image processing to manipulate specific parts of an image while leaving other areas untouched. This is particularly useful in applications like object detection, image segmentation, and photo editing. In this tutorial, we’ll explore how to perform image masking using OpenCV addWeighted function. Continue Reading
ResUNET: A TensorFlow Implementation for Semantic Segmentation

In computer vision and medical image analysis, semantic segmentation plays a pivotal role in understanding and interpreting visual data. One of the prominent architectures in this domain is ResUNet, a fusion of U-Net and ResNet architectures, renowned for its ability to efficiently capture local and global features. In this blog Continue Reading
Image Segmentation-based Background Removal in TensorFlow

Image segmentation is an important area of computer vision that involves dividing an image into multiple segments, each of which corresponds to a different object. Background removal is one of the crucial applications of image segmentation that involves separating foreground objects from the background. This can be useful in various Continue Reading