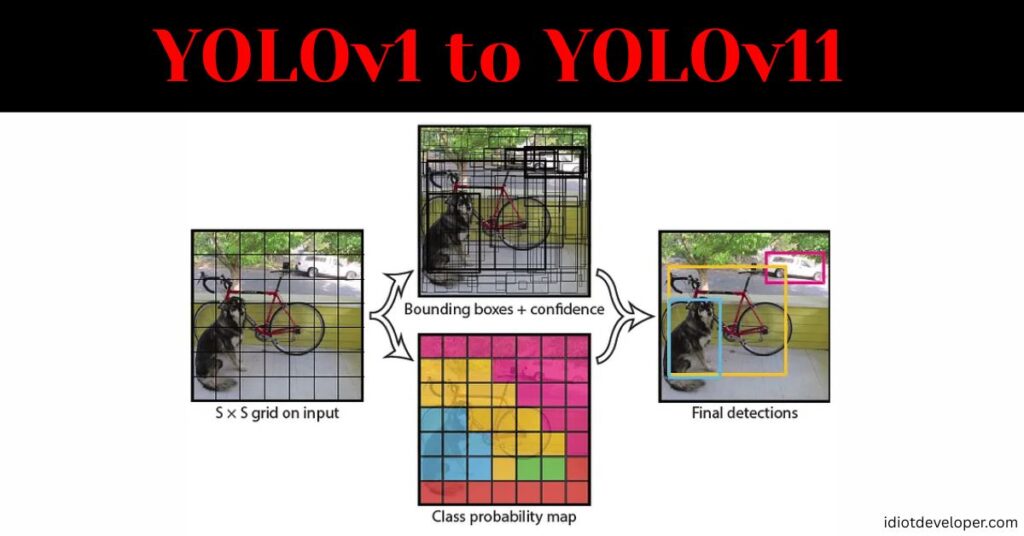
The You Only Look Once (YOLO) series has revolutionized object detection since its inception in 2015. Developed initially by Joseph Redmon and colleagues, YOLO redefined speed and efficiency in computer vision by transforming detection into a single regression problem. Unlike earlier two-stage detectors (e.g., R-CNN), which required multiple passes over Continue Reading
cnn
GradCAM and its Implementation in PyTorch

Deep learning models, especially convolutional neural networks (CNNs), often function as black boxes, making it difficult to interpret their decision-making processes. Gradient-weighted Class Activation Mapping (GradCAM) is a powerful technique used to visualize and understand these models by highlighting the regions of an image that contribute most to a prediction. Continue Reading
GradCAM with TensorFlow: Interpreting Neural Networks with Class Activation Maps

Deep learning models, particularly convolutional neural networks (CNNs), are widely used for image classification, object detection, and various computer vision tasks. However, these models are often referred to as “black boxes” due to their complex decision-making processes. To interpret these decisions and understand what parts of an image influence the Continue Reading
Visual Question Answering from Scratch using TensorFlow
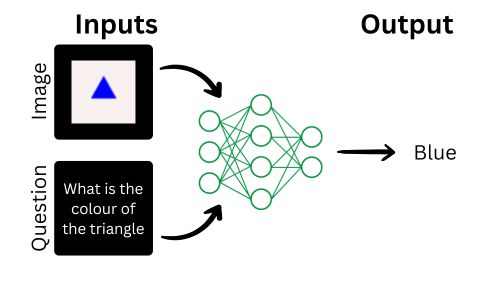
Visual Question Answering (VQA) is a fascinating field in artificial intelligence where a system answers questions about an image. This combines natural language processing (NLP) to understand the question and computer vision to analyze the image. For example, given an image of a red apple and the question “What color Continue Reading
What is Image Captioning?

In recent years, the field of artificial intelligence (AI) has seen remarkable advancements, particularly in how machines can understand and describe visual content. One of the fascinating developments in this area is image captioning, where AI models are trained to generate descriptive captions for images. This technology, often referred to Continue Reading
ResUNet++ Implementation in TensorFlow
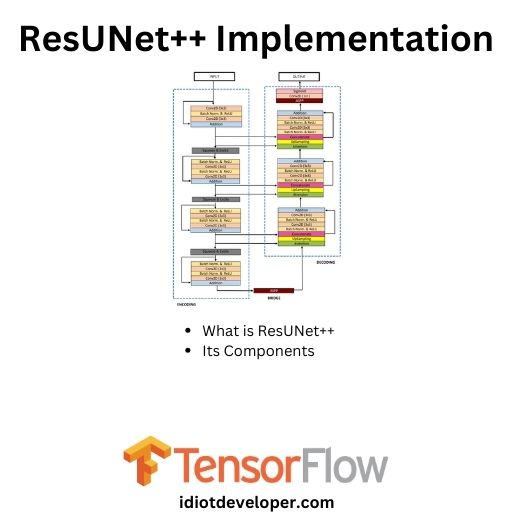
In this article, we will study the ResUNet++ architecture and implement it using the TensorFlow framework. ResUNet++ is a medical image segmentation architecture built upon the ResUNet architecture. It takes advantage of Residual Networks, Squeeze and Excitation blocks, Atrous Spatial Pyramidal Pooling (ASPP), and attention blocks. What is ResUNet++? Debesh Continue Reading
UNet 3+ Implementation in TensorFlow

In this article, we will implement the UNet 3+ architecture using TensorFlow. UNet 3+ extends the classic UNet and UNet++ architecture incorporating full skip connections. We will delve into each block of the UNet 3+ architecture, explaining how they work and how they contribute to improving the model’s performance. Understanding these Continue Reading
Skip Connection in Image Segmentation: UNet, UNet++ and UNet 3+

Image segmentation, a fundamental task in computer vision, involves partitioning an image into multiple segments to simplify its representation. One of the critical advancements in image segmentation architectures is the integration of skip connections, which have revolutionized the field by improving the accuracy and efficiency of segmentation models. What are Continue Reading
[Paper Summary] UNet 3+: A Full-Scale Connected UNET For Medical Image Segmentation
![[Paper Summary] UNet 3+: A Full-Scale Connected UNET For Medical Image Segmentation](https://idiotdeveloper.com/wp-content/uploads/2024/02/ResU-Net-1.jpg)
In medical image analysis, accurately identifying and outlining organs is vital for clinical applications such as diagnosis and treatment planning. The UNet architecture, a widely favoured choice for these tasks, has seen enhancements through UNet++, which introduced nested and dense skip connections to improve performance. Taking this evolution further, the Continue Reading
ResUNET: A TensorFlow Implementation for Semantic Segmentation

In computer vision and medical image analysis, semantic segmentation plays a pivotal role in understanding and interpreting visual data. One of the prominent architectures in this domain is ResUNet, a fusion of U-Net and ResNet architectures, renowned for its ability to efficiently capture local and global features. In this blog Continue Reading