Generative Adversarial Networks (GANs) have revolutionized the field of artificial intelligence by introducing a powerful framework for generating realistic data. Among various GAN architectures, Deep Convolutional Generative Adversarial Networks (DCGANs) have gained significant popularity due to their ability to generate high-resolution images. In this article, we delve into the realm of Conditional DCGANs, an enhanced version that introduces conditional information to the generative process.
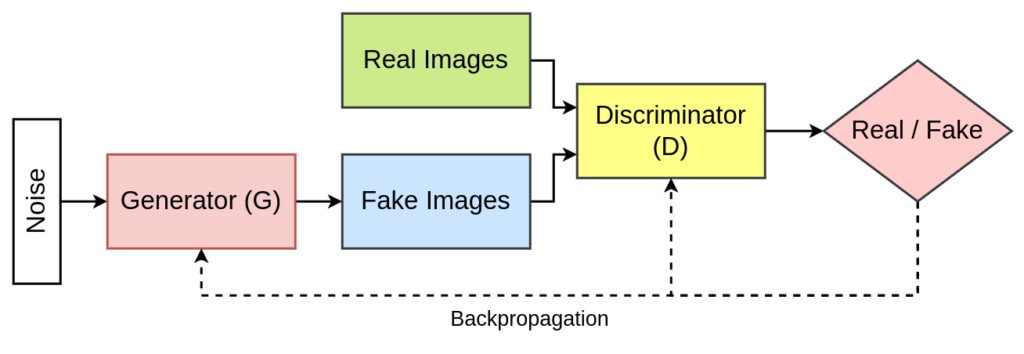
Introduction to DCGANs
DCGANs, proposed by Radford et al. in 2015, extended the traditional GAN architecture by incorporating convolutional layers. This modification improved the model’s ability to capture spatial hierarchies and create more detailed and realistic images. DCGANs became a cornerstone in image synthesis tasks, demonstrating remarkable performance in generating diverse, high-quality images.
Research Paper: Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Convolutional layers in both the generator and discriminator networks characterize DCGAN’s architecture. The generator uses transposed convolutions to upsample the input noise, creating a more complex data representation. Simultaneously, the discriminator utilizes convolutional layers to assess the authenticity of the generated samples. Both the generator and discriminator network use LeakyReLU as the activation function.
Read More: What are Deep Convolutional Generative Adversarial Networks (DCGANs)
Introduction to Conditional GANs
Conditional GANs, introduced by Mirza and Osindero in 2014, introduced a conditional input to the generator and discriminator. This conditional information allows for the generation of specific outputs based on given labels or attributes. By conditioning the GAN, it becomes possible to control and guide the generation process, enabling the creation of targeted and customized outputs.

Research Paper: Conditional Generative Adversarial Nets
Read More: What is a Conditional GAN: Unleashing the Power of Context in Generative Models
Merging DCGAN with Conditional GAN
The idea of merging DCGAN with Conditional GAN stems from the desire to leverage the benefits of both architectures. By introducing conditionality to DCGANs, we enhance the control and specificity in image generation. This combination leads to Conditional DCGANs, a versatile model capable of generating images based on desired conditions.
Architecture of Conditional DCGAN
The architecture of Conditional DCGAN involves integrating conditional information into both the generator and discriminator. The generator takes noise and conditional information as input to generate images, while the discriminator evaluates the authenticity of generated images considering both the image data and conditional input. This dual modification enables the model to generate images based on specific attributes or labels.
Applications of Conditional DCGAN
Conditional DCGAN finds applications in various domains:
- Image-to-Image Translation: Conditional DCGANs can be used for tasks such as translating satellite images to maps, black-and-white photos to color, or sketches to realistic images. The conditional input guides the generator to produce outputs that adhere to specific criteria.
- Style Transfer: Artistic style transfer is another area where Conditional DCGANs excel. By conditioning the generator on a particular art style, the model can transform input images to match the specified aesthetic.
- Data Augmentation: In data science and computer vision, Conditional DCGANs are employed for data augmentation. By conditioning the generator on the class labels of the images, the model can generate additional training samples for specific classes.
- Custom Image Synthesis: For applications requiring the generation of custom images with specific attributes, such as faces with certain expressions or objects in particular poses, Conditional DCGAN proves to be highly useful.
Challenges and Future Directions
Despite their success, Conditional DCGANs face challenges like mode collapse and training instability. Future research directions may focus on addressing these challenges, improving the conditioning mechanisms, and extending the model’s capabilities to handle more complex tasks.
Conclusion
Conditional DCGANs represent a powerful fusion of DCGAN and Conditional GAN architectures, providing a flexible and controlled approach to image generation. Their applications span across various domains, and with ongoing research, these models are likely to play a pivotal role in advancing the field of generative models.




