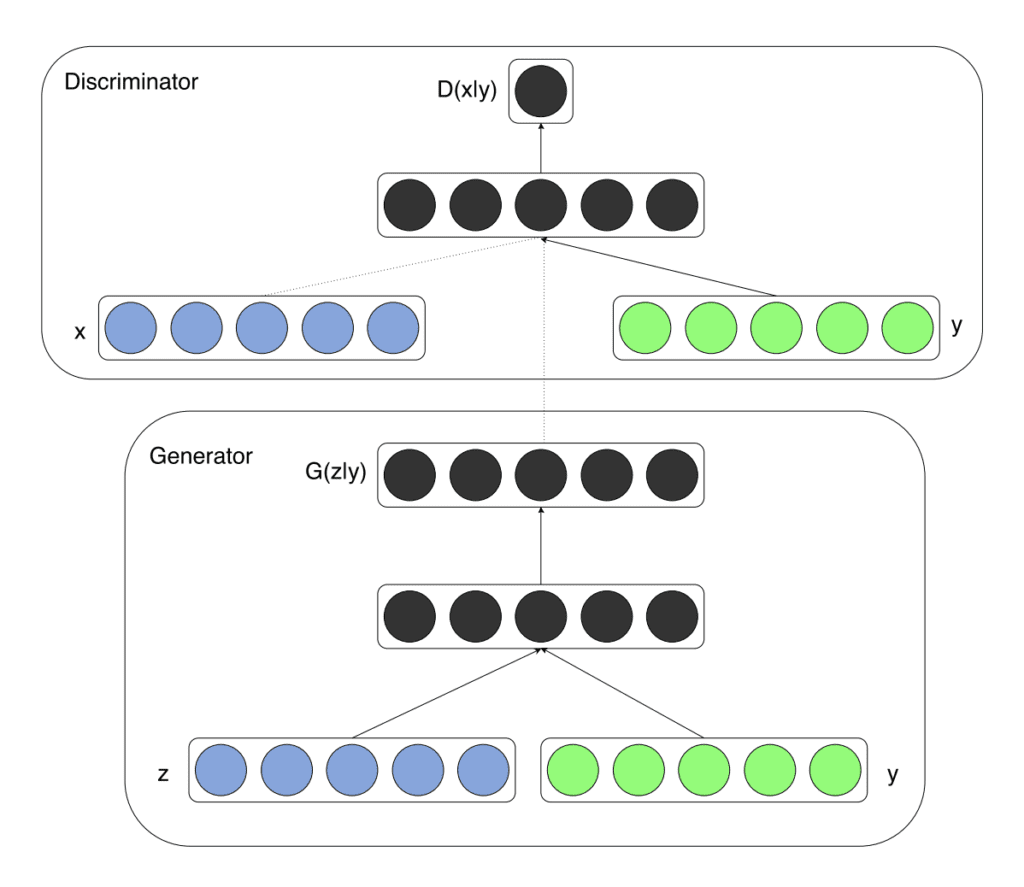
In the rapidly evolving landscape of artificial intelligence and machine learning, Generative Adversarial Networks (GANs) have emerged as a revolutionary approach to generating data that mimics real-world distributions. One intriguing development within this realm is the Conditional GAN, an extension of the classic GAN architecture that introduces the concept of Continue Reading
Vanilla GAN in TensorFlow

This tutorial will teach you how to implement basic Generative Adversarial Networks (GANs) in TensorFlow using Keras API. For this purpose, we will utilize the Anime Face Dataset and try to generate realistic anime faces. What is GAN GAN stands for Generative Adversarial Network, a framework in which two neural Continue Reading
Mastering k-Nearest Neighbor Algorithm in R

The field of machine learning is thriving with a plethora of algorithms that can be used to solve a wide range of problems. One such algorithm is the k-Nearest Neighbor (k-NN), which is a simple yet powerful non-parametric method used for classification and regression tasks. In this article, we will Continue Reading
Types of Machine Learning

Artificial Intelligence (AI) has become an indispensable aspect of modern technology, primarily due to the learning capabilities of AI algorithms from a dataset. This has led to the growth of machine learning, a branch of AI that enables machines to learn and improve from experience without explicit programming. Machine learning Continue Reading
Turing Test and The Chinese Room Test

Artificial Intelligence (AI) has been improving and plays a vital role in our daily lives. One of the most popular tests for determining the intelligence of a machine is the Turing Test, proposed by Alan Turing in 1950. However, the Turing Test has faced criticism, one of which is the Continue Reading
Types of Artificial Intelligence
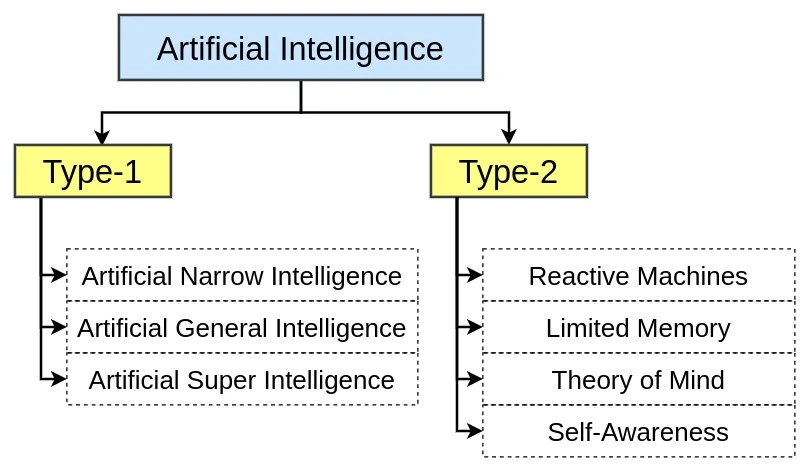
Artificial Intelligence (AI) has been a buzzword for a while now, and the technology is growing at an unprecedented rate. With the rise in AI, machines are becoming increasingly intelligent and able to perform tasks that were once considered the sole domain of humans. In this article, we will discuss Continue Reading
What is Artificial Intelligence

Artificial intelligence (AI) is one of the most rapidly developing technologies of our time. It is a branch of computer science that involves creating intelligent machines that can perform tasks that would typically require human intelligence. AI is already changing the world as we know it, and its potential impact Continue Reading
Read 3D NIFTI Images in Python3

Medical imaging is an essential tool in the diagnosis, treatment, and monitoring of various medical conditions. One of the most widely used medical imaging techniques is Magnetic Resonance Imaging (MRI), which produces three-dimensional images of the human body. These images are saved in a standard file format called NIFTI, which Continue Reading
Attention UNET in PyTorch
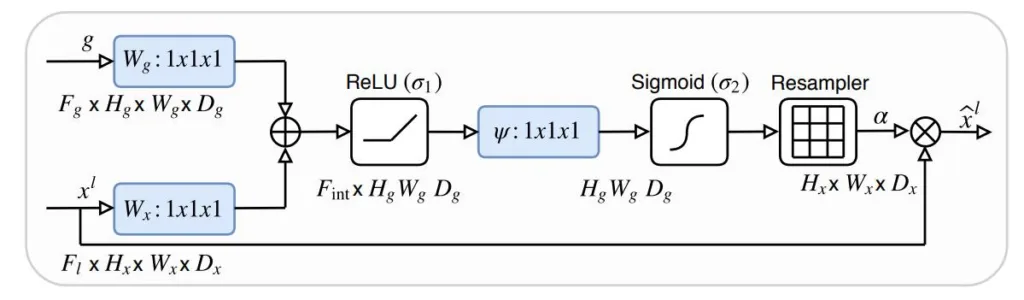
In this article, we are going to learn about the Attention UNET and then implement it in the PyTorch framework. Attention UNET is a type of Convolutional Neural Network (CNN) that is commonly used for image segmentation tasks. It is an extension of the original U-Net architecture, which was proposed Continue Reading
Attention UNET and its Implementation in TensorFlow
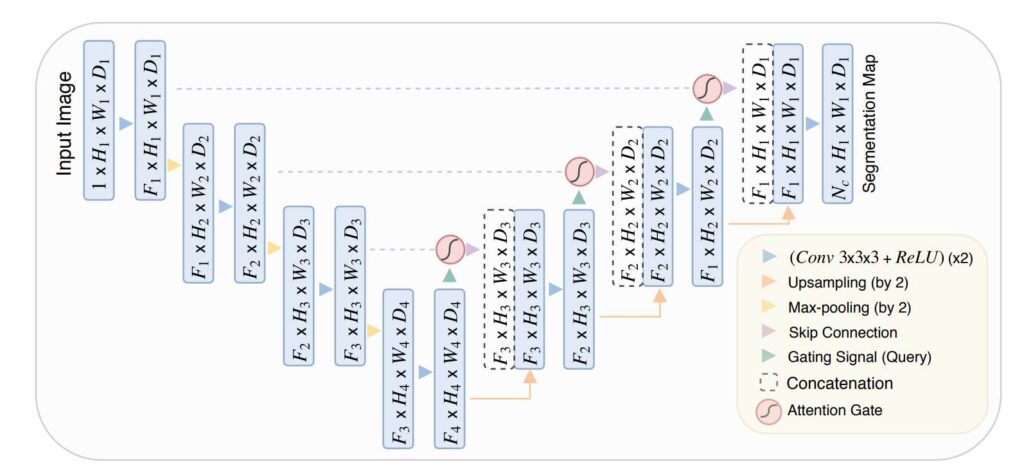
In the article, we will go through the paper Attention U-Net: Learning Where to Look for the Pancreas. It was written by Ozan Oktay et. al in the year 2018 at the MIDL (Medical Imaging with Deep Learning) conference. The Attention UNET introduces a novel Attention Gate that enables the Continue Reading